Apache Spark - Adaptive Query Execution/AQE
1. AQE–History
- 自适应查询
- Adaptive/AQE/AE
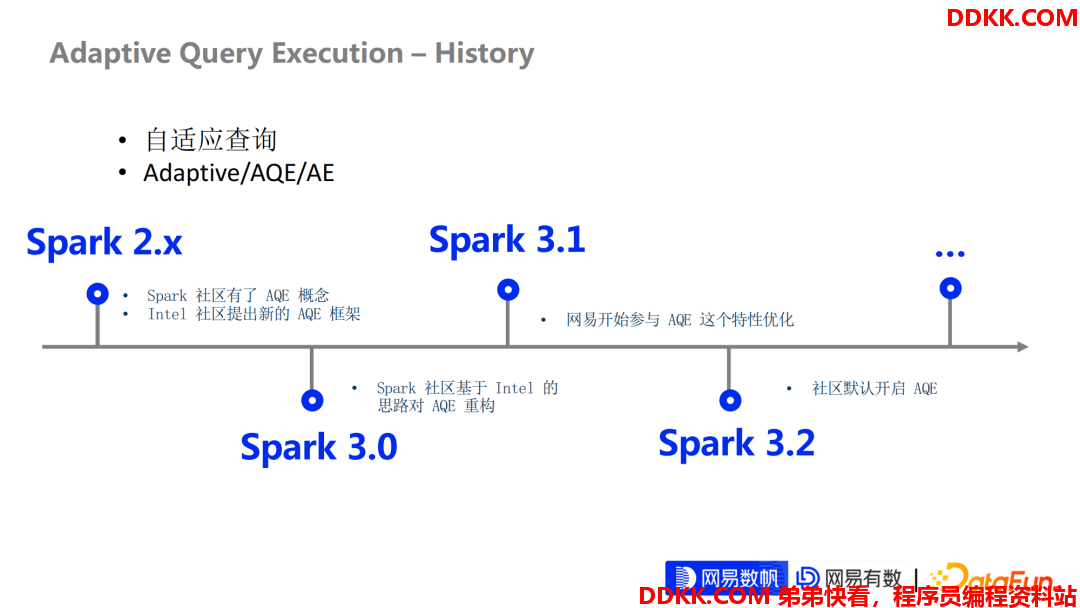
下面先来讲一下 Apache Spark Adaptive Query Execution 的一些历史, AQE 在不管是 Spark 开源代码里面还是在技术博客里面出现的频率越来越高,我们一般会用 AQE 这种缩写去简称它。
- Spark 2.X
AQE在Spark 2.X版本其实就已经有了一定的雏形。但是整个框架是非常 Hack 的,并且存在很多 Bug,它提供的功能就是可以合并一些小的分区。除此之外也没有别的功能,设计非常简单。
- Spark 3.0
到Spark 3.0的这个开发阶段,Intel 提出了一个基于 AQE 的新框架。在这个框架下我们可以做非常多事情,主要围绕两部分:
①对于 Shuffle Reader 阶段的各种优化
包括我们现在可以想到的一些Join 倾斜优化、 Local Shuffle Reader 的优化。这些优化在现在这个框架里都非常简单,只需要添加一些规则就可以支持。
②通过优化执行计划来进一步去优化 SQL 性能
比如我们以前见到的广播 Join,在 AQE 这个特性里面可以在运行时动态地将我们的 Join 转化成广播 Join 来跑。这一层面提高了 SQL 的性能。
- Spark 3.1
Spark 3.1时代,网易开始进入并参与到了 AQE 特性的优化和增强。到目前为止,大概有40多个 Patch 已经合入了 Apache Spark 的社区。
网易内部默认打开了 AQE 特性并且效果非常好,相比于原来的Spark2.x 版本,几乎每个在TPC-DS性能测试下,几乎有 100% 的性能提升。
- Spark 3.2
Spark 3.2才把 AQE 特性默认开启我相信在未来即将发布的 Spark 版本里面, AQE 会发挥更多更重要的作用,也还会有更多的特性的引入进来。
2. AQE–Shuffle
- Small Reduce Partition
- Skewed Reduce Partition
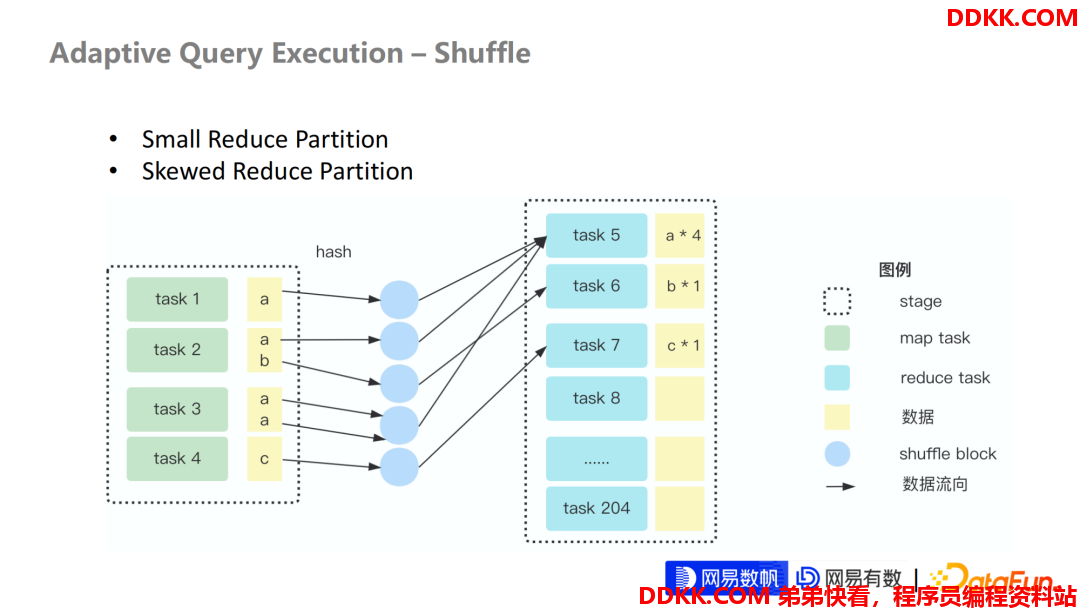
下面来讲一下 AQE 整个的一个设计,它解决了什么问题?以及它是如何解决的?
- 我们看一个非常简单的一张 Shuffle 图:
左边部分:是 Shuffle 的 Map 阶段,也就是负责写 Shuffle 数据的这一个 Stage
右边部分:是负责 Read Shuffle 数据的 Stage
中间部分:是 Spark Shuffle Block
可以看到,这是个非常简单的 Demo,它的数据已经出现了非常小的一些分区,实际在 Reduce 分区里面只有3个分区是有数据的,剩下197个是空的。我们知道这200个分区是 Spark 默认的分区配置,也就是我们经常会调整的 SQL Shuffle Partition 的配置。
- 这个 Shuffle 其实已经引入2个问题:
①假设我们期望每个分区只处理两条数据,Task5 分区已经出现了数据倾斜。
②剩下的分区都是小分区,或者是根本没有数据的分区,无效分区,这些分区在 Spark 整个调度层面会造成非常严重的 Task 资源浪费。
- AQE 的诞生就是为了解决这些问题
3. AQE - Small Reduce Partition
- Coalesce Shuffle Partition
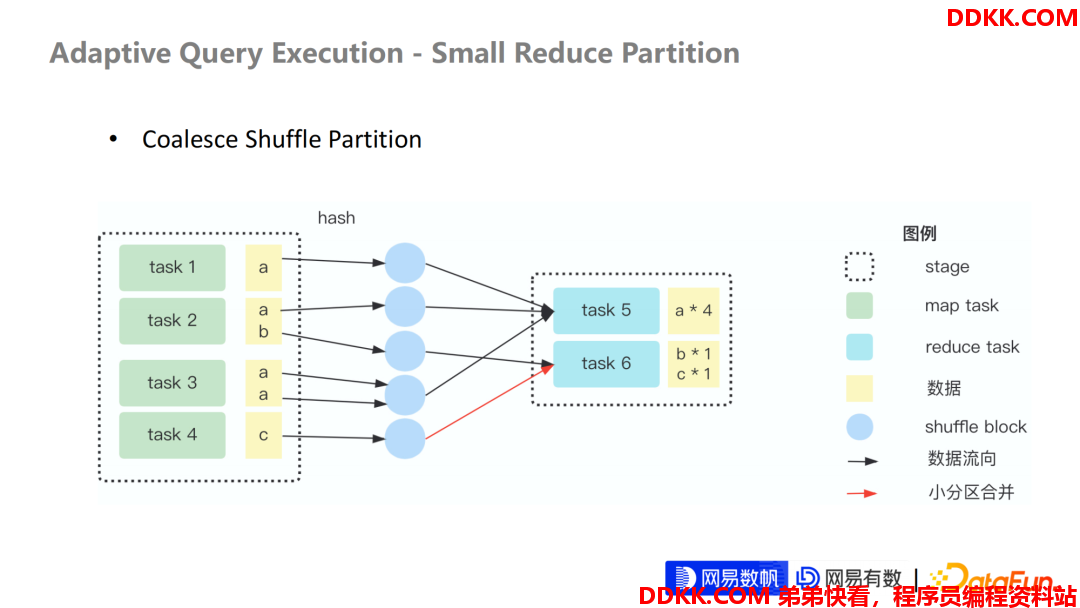
我们先来看一下第一个问题,Small Reduce Partition , 也就是 Reduce 分区处理的数据量很小。在 Spark 的 AQE 的框架里面,这个特性的规则就是 Coalesce Shuffle Partition。Shuffle Partition 其实是和 Reduce Partition 等价的,在 Spark 代码里面这个特性规则就命名为 Shuffle Partition。
可以看到,经过 AQE 优化之后,整个 Shuffle Partition 用2个 Task 就完成了整个 Stage 的执行。对比刚刚那个 Stage 节省了198个 Task。这在实际的调度层面,会极大地提高任务的执行性能。
这根红线是表明了这个被合并的分区的一个数据流向,也就是 Task 6原本需要读 Task2 中的b这条数据,但是我们期望每个 Task 假设处理2条数据,最终它所有会把 Task4 产生的数据c也收录到这个分区内部来处理。这样就起到合并 Reduce 分区的效果。
在另一层面,如果 Stage 是最后一个 Stage,也就是负责写数据 Stage,那这个 Stage 还将影响整个产生文件数据量的大小,也就是我们以前经常听到的一些小文件问题。
4. AQE – Skewed Reduce Partition
- Optimize Skewed Join
- Optimize Skew In Rebalance Partition
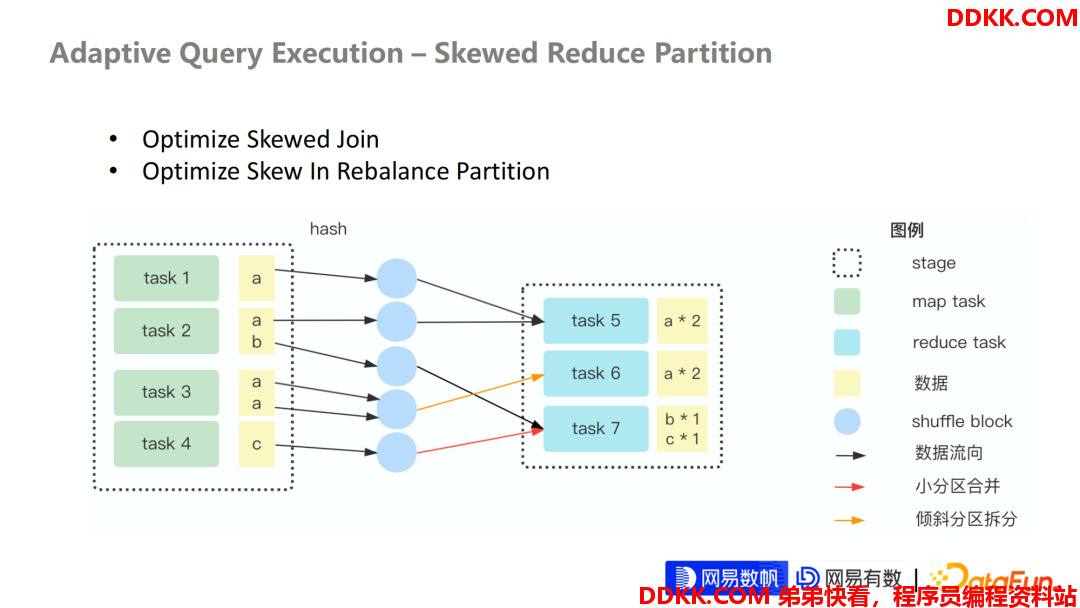
第二个部分我们来讲一下 Shuffle Partition 文件 Skew 的问题。
我们知道 Spark 3.2 对于 Skew 分区的优化其实由两部分组成:
①对于 Join 倾斜的优化
②对于 Rebalance Partition 的优化
其实这两个优化的本质原理都是类似,都是通过拆解大分区来去平衡每个分区处理的数据量。
比如这个例子中a这个数据其实是倾斜的,我们希望每分区处理2条数据,而原来的 Task5处理了4条数据。我们期望把 Task5的分区再拆,一拆为二,拆成两个分区来处理。最终结果采用了三个分区来处理这些数据,每个分区处理的数据量都是一致。这样非常平均的 Task 数据量会让每个 Task 的执行性能,执行速度都非常相近,避免出现一些长尾的 Task 或倾斜的 Task,导致拖累整个 Stage 执行的性能问题,从而解决了倾斜的问题。
5. AQE – Optimize Plan
- Dynamic Join Selection
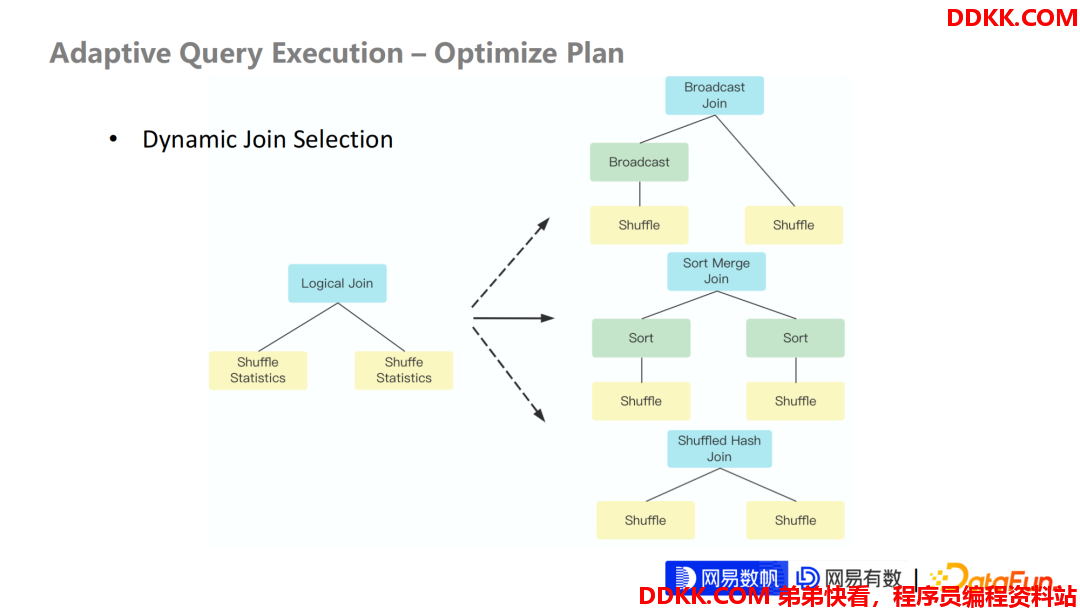
刚刚讲的是关于 AQE 对于 Shuffle Read 这一个层面的优化思路,就是通过动态地生成 Shuffle Read 来合并分区,或者优化 Join 分区去调整每个 Task 的输入数据量。另一个思路就是可以在 AQE 框架内,动态地去优化执行计划。
在没有AQE 之前,Spark 优化执行计划都是基于规则或者是基于静态统计数据的优化方式,整个过程在 SQL 编译阶段就完成了。一旦确认每个执行计划的执行算子之后,在执行过程中不会发生任何的改变,它只会去按照的最初的执行计划一直跑。
那么我们是不是可以拿到在执行中的一些 Shuffle 的数据,再通过这些数据去优化下一阶段要去跑的执行计划。基于这个思路,AQE 就提出了重新优化执行计划这样一个特性,网易在这个特性里面支持了对于 Join 的动态选择,是在 Join 领域里面非常核心的一个 Feature。
我们知道在 Spark 层面,如果是等值 Join,它会有三种执行方式:
①默认的是基于 Sort Merge Join,也是非常普适的,非常稳定的一种 Join 方式。
②如果一边数据量非常小,会采用广播 Join 的方式,也就是我们经常会遇到的一种。
这个 广播 Join 会让我们经常会遇到一些 OOM 问题,因为广播 Join 在原来都会采用静态的数据统计估计。数据统计估计可能是不准确的,因为它可能考虑到一些数据压缩率、每个算子的数据膨胀或者数据过滤的一些系数,它可能不太精准,从而导致我们在广播 Join 的阶段误判了执行计划的一个代价,把一个非常大的 Relation去广播到每个Reduce Task,导致我们的 Driver 压力非常大。
在AQE 的环境下,可以通过采集执行计划实际的数据大小。如果该大小小于期望的 Driver 内存大小,可以考虑把数据Down到 Driver,再广播出去。这比相对于静态的数据统计来做广播 Join 判断,可以避免 OOM 情况。因为整个数据都是非常实际、非常准确的,不会出现误估的情况。
③还有一种Join 是基于 Shuffle 的Hash Join,它的特点就是每一个分区内的数据都不是很大,但是结果总的数据量比较大,那我们可以把每一个分区内的数据 Build成一个 Hash Relation,然后再去和另一边做 Join。
每一种Join 的执行策略都有各自的优势和劣势。用户在优化的时候,他肯定需要去不断调试,需要不断地去判断数据分布情况。如果 SQL 非常复杂,这种优化的成本是非常高的。我们通过在 AQE 这个框架里去支持基于 Runtime 的动态选择 Join 策略,可以极大的帮助用户降低优化成本。
整个动态 Join 选择在网易内部上线效果也还是比较可观的,相比于不开这个动态 Join 选择会有2%-30%的 Join 的性能提升。
Kyuubi + Spark 数仓类任务优化实践
第二部分来围绕着 Kyuubi 和 Spark 这两个组合拳分享关于数仓类任务的优化实践。
1. Kyuubi + Spark – 架构
- Thrift & JDBC & Rest & 多租户
- 云原生
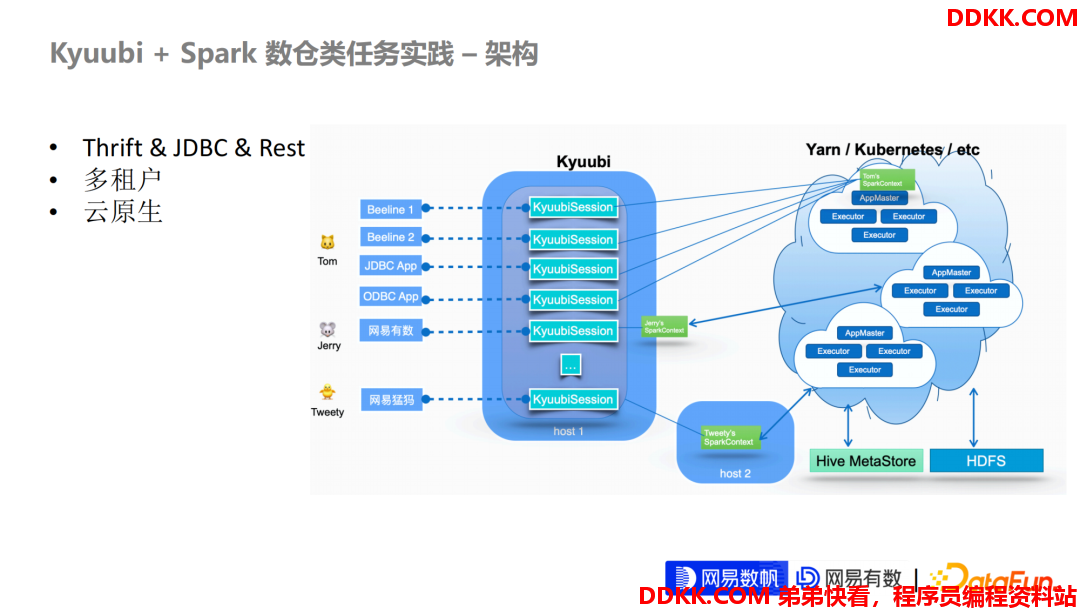
我们先讲一下 Kyuubi 这整个的架构和定位。
①Apache Kyuubi 对外可以支持 Thrift 接口或者 JDBC 接口,我们社区最近在支持的一个 Rest 接口。这是非常灵活的。我们网易内部,通过这些接口,我们支持了对于离线 SQL 任务,就是我们通常说的离线数仓类任务的一些支持。
②多租户的支持。在企业级的大数据场景里面多租户是非常重要,考虑到数据读写的安全,以及我们在数据层面的更细粒度,比如 Row Level 或者是 Column Level 的鉴权。
③Kyuubi 这套架构是完全支持云原生的,在网易内部其实一个 Kyuubi 集群可以同时路由到 Kubernetes 集群和 Yarn 集群,只需要在用户层面直接需要改一些配置就可以这样灵活地去路由。
**2. Kyuubi+**Spark–安全
- Kerberos
- Kerberos-Proxy
- Ranger
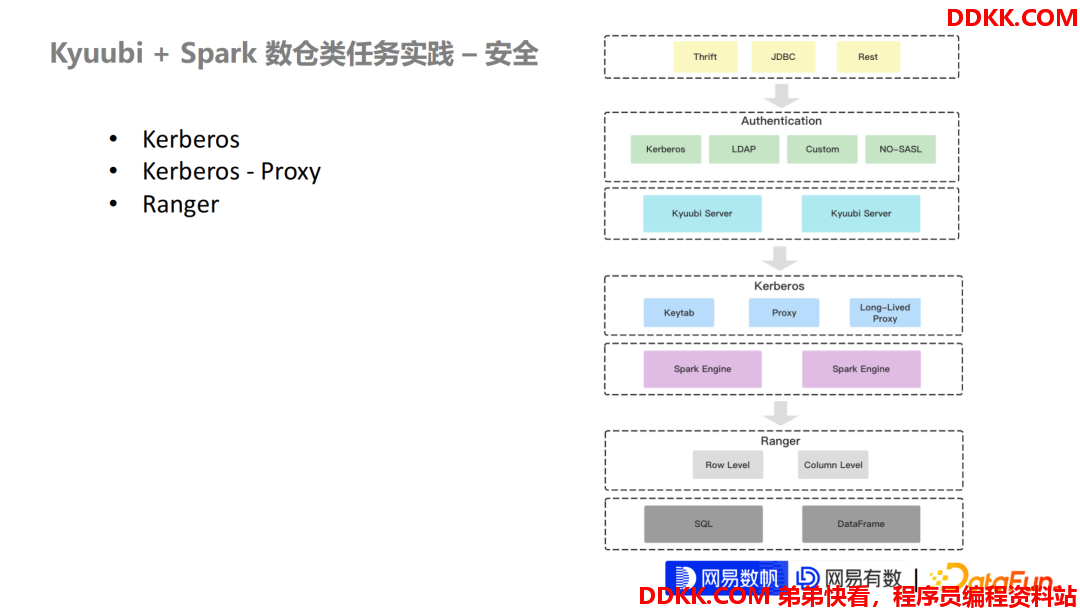
下面讲一下这个 Kyuubi + Spark 这一套体系中,Kyuubi 是怎么去考虑数据安全或者说是怎么接入一套安全认证体系的?
我们知道在大数据场景,在 Hadoop 的生态范围内, Kerberos 是一个绕不过去的安全认证系统,Kyuubi 在 Kerberos 集成方面做了非常多的工作。分为两个部分:
第一部分是 Kyuubi Server, 负责接入用户的 Query。
第二部分是 Kyuubi 的引擎,比如 Spark 引擎,或者是我们最新推出的一些 Flink 引擎或者 Trino 引擎去负责执行用户的 Query。
第一部分Kyuubi的接入层。在接入层 Kyuubi Server 我们**支持了最常见的 Kerberos,还有一些比较简单的 LDAP,包括我们支持用户去自定义自己的一些鉴权行为,来帮助用户去更容易地去和自己内部的一些安全认证体系做集成,**这是第一步在 Kyuubi Server 的一些集成环境 。
第二部分 Kyuubi Server 和 Kyuubi 引擎之间,我们也支持基于 Kerberos(不管是 Keytab 或者是 Proxy)的两种接入方式。
**另外 Kyuubi 还自研了支持 Proxy 的一个 Long Live 的行为,**Hadoop 的原生的 Proxy 体系,并不支持长期的任务作业,比如一个任务跑了3天,过了12个小时,或者是一段时间内,你的 Proxy 的 Token 就失效了。这时候你的任务是无法长期作业的。
Kyuubi 的定位其实是非常的广泛,它可以作为一个长期存在的服务,去提供比如 Ad-Hoc 之类这种查询服务。我们希望 Kyuubi 整个架构可以支持把引擎缓存起来,支持引擎常驻等功能。这时候基于 Long Live 的 Proxy 的协议就非常有效果,**通过在Kyuubi Server 内部不断地去利用 Kyuubi 自己的 Keytab 去刷新用户的 Proxy Token。从而再通过 Thrift 协议去扔给 Kyuubi 的引擎。**这样是可以去保证 Kyuubi 引擎的Token永远是活跃状态,不会出现失效问题,从而实现 Long Live的这种Proxy类的协议。
最后我们在引擎层面其实还支持更细粒度的安全特性,比如对于数据 Row Level 和Column Level 的数据过滤或者是 Data Marks,当然我们特性需要在1.6下一版本可以支持,现在还在研发阶段。但是整个 Kyuubi 的数据安全体系建设体系是非常完善的。
3. Kyuubi+Spark–方案
- Distribute By + Local Sort ×
- Rebalance + Z-Order √
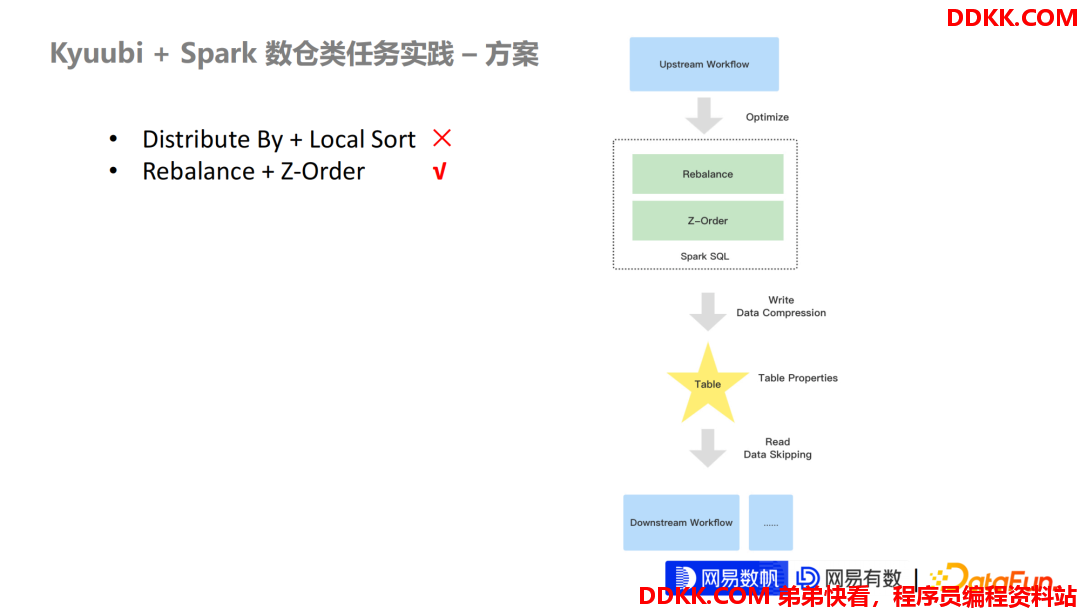
下面再说一下关于我们数仓类任务的一个优化方案。刚刚我们基于 Kyuubi + Spark 已经解决了数任务是如何去调度的,去跑在 Yarn 也好,跑 Kubernetes 也好,都已经完成了这些支持,那剩下的就是任务本身的一些性能,它的数据产出质量。
性能方面已经有了 Spark AQE 这一核心特性,那剩下的我们需要重点考虑的,对于 SQL 开发者来说,是它的数据产出质量。
关于数据产出质量这一层面来说,Spark 的支持其实不太友好,或者是每个大数据引擎的支持都不太友好。**不管是对于小文件的处理也好,或者是对于倾斜文件的拆分也好,**基本上没有出现一个成体系的一套方案,或者是一个开箱即用的方案。
数据开发在这种场景下就会自己地去琢磨,他会去根据数据去优化,比如会加一些 Distribute By 这种行为,或者在 Distribute By 后面再加一个 Local Sort,或者是在 Hive SQL 里面可能合并进行一个 Cluster By 来提高整个数据的产出质量。
数据的产出质量其实可以分成两部分来看。
第一部分是数据的压缩率。基于 Hash 分区后,或者在做排序后,它的压缩率会有一定程度的提高。
另一方面就是数据文件的一个质量。我们期望文件大小是非常适合我们去 Read 的,比如和 HDFS 的 Block 大小是匹配的。期望整个文件稳定在 256M 或者是 128M 这种固定大小的一个文件块,这样在下游 Read 阶段会有比较好的一个数据效果,同时对于我们 HDFS Name Node 一些元数据治理也有非常好的一个优化。
但是原生的 Distribute By 有一些弊端,首先它就解决不了文件倾斜的问题。当你出现某些 Key 值倾斜时候,Distribute By 会导致某些分区的数据量非常大,导致这个任务跑得非常慢,因为某些 Task 可能需要处理比别的 Task 的多几倍或者几十倍的数据。另一方面,在 Local Sort 其实对于多维数据来说的数据聚集分布的效果没有非常优秀,我们在此基础上提出了基于 Rebalance + Z Order 的、在写层面的优化方案。
Rebalance 可以在 AQE 框架下提供小文件合并以及大文件的一个拆分的功能。另外,网易内部还提供了关于基于 Stage 粒度的一个配置隔离,现在已经可以在 Kyuubi 社区里面可以看到。
我们知道写 Stage 永远是最后一个 Stage,那 Stage 配置隔离意味着你可以控制最后一个 Stage 的整个 Input Size。比如网易内部期望默认输出的一个文件大小是 200M+ 或者 300M+,那我们可以把最后一个分区的 Input Size 设置成 200M+ 或者 300M+,从而可以保证每个任务产生的数据文件都是期望的大小。
另一层面在 Z Order,在最近在大数据领域来说相是比较流行的一个特性,比如Databricks Delta和Iceberg 都在探索相关的支持。本质上就是把多维数据可以映射到一维数据,在映射的过程中可以保证这整个多维数据的数据聚集分布效果不失真。
这在一定程度上就可以让整个数据的分布非常优秀,从而可以在保证压缩率的情况下,让下游的任务在 Read 阶段有非常好的 Data Skipping 效果。
这整套方案在网易内部已经做了大量的优化实践。现在通过 Kyuubi 已经可以完成这整套优化链路。
首先我们可以通过定义表的一个核心的字段,比如我们某一张表有3~5个字段, 适合去做排序或者有非常好的压缩效果,或者在被下游任务去读的时候会非常频繁,亦或者是一些热点字段作为谓语条件存在频率非常高。就可以把这些字段定义到这张表的 Properties 里面去。
Kyuubi 再跑这些 SQL 的时候,就会动态感知这些 Table 里面的 Properties,判断是否要为这些写的数仓类任务增加 Rebalance + Z Order,去规范化每一个数仓类任务的产出,从而让整个产出的数据质量及产出的表的下游任务在读的时候有非常好的查询性能。这会获得两部分收益:
①对于写存储层面的一个收益
②在下游任务读的一个 Read 查询层面的收益
两个层面的收益效果都非常理想。
4. Kyuubi+Spark–数据
- 降低存储成本
- 提高查询性能
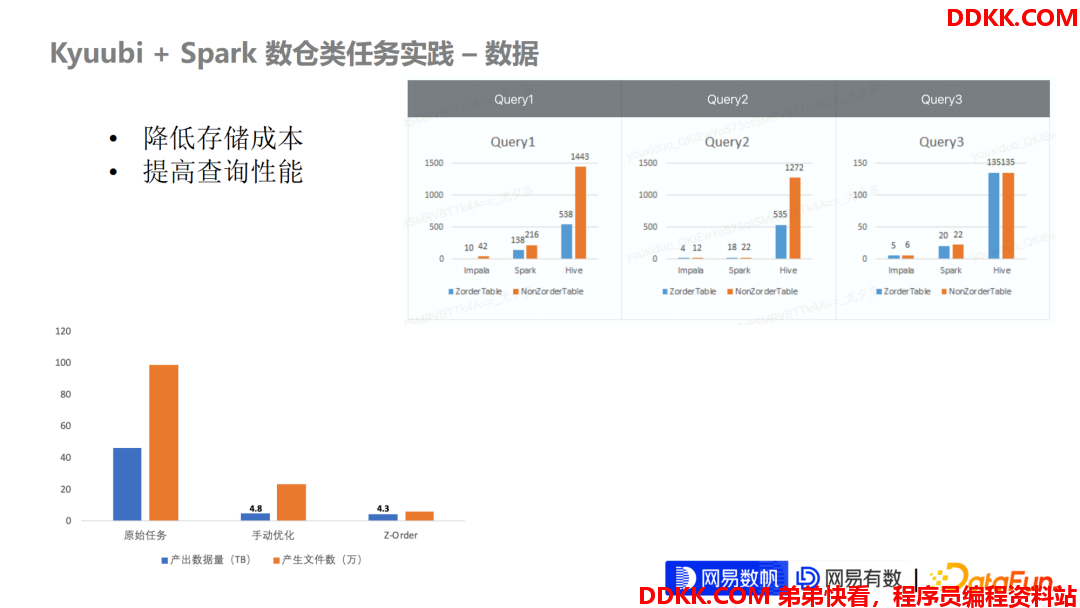
下面再给一些我们网易内部的、基于 Rebalance + Z Order 的性能数据。
左边这张图是我们的整个产出的一个文件数据量和产生的文件的数据大小,可以看到三个阶段:
第一阶段是野生或者是刚写完的这个任务,整个产出质量非常不理想,不管压缩率也好,还是文件数也好,都是野蛮生长。这时候经验丰富的一些SQL开发就会去通过给 Distribute By 或者是 Distribute By 再取模,或者是再通过一些比较 Hack 的行为强行把当前的这部分数据压缩率降下来。
但是有一些场景非常难以保证压缩率和小文件同时下降。比如在一些动态分区写的这种场景,其实压缩率和小文件他们这两个条件是互斥的,也就是非常难保证同时满足两个条件且都达到非常好效果。
我们通过 Rebalance + Z Order 这一套优化下来,不管是在产生的数据量也好,还是在产生的小文件数也好,它都有非常好的下降趋势。当然产生数据量,一般来对于用户是第一关心的点,可能宁愿会牺牲文件数量也来保证压缩率。
另一方面右边这张图可以看到我们经过优化之后,对于下游任务的查询性也有非常大的提升,并且性能的提升其实是跨引擎的,包括我们测试的一些 Impala 引擎,或者是我们最常用的 Spark 引擎,还有我们历史遗留的 Hive 引擎。三个引擎对于优化后的表的查询都有一定程度的性能提升。这对于我们来说是非常非常好的一个信号,因为我们写任务这一环节都是通过 Spark SQL 去写的。但是在读阶段在各个引擎都可以享受到写优化带来的性能提升,相当于进一步提高了优化的一个覆盖范围。
因为数仓类任务,我们知道它可能下游任务是其他更上层的数仓任务,也可能是一些直接报表,或者是给数据分析师接 HQL 之类的一些查询。那他每一个查询的引擎可能在不同公司内部用的组件模型都不太一样,那有些用 Impala,有些可能用 Presto,可能有些用其他的引擎。我们在优化层面上支持了多引擎的查询性能优化,也取得了非常好的效果。
希望大家可以在有兴趣的可以来 Kyuubi 社区来体验一下 Rebalance + Z Order 这一套方式。