背景
Shuffle是分布式计算框架用来衔接上下游任务的数据重分布过程,在分布式计算中所有涉及到数据上下游衔接的过程都可以理解为shuffle。针对不同的分布式框架,shuffle有几种实现形态:
1、 基于文件的pullbasedshuffle,如MapReduce、Spark这种shuffle方式多用于类MR的框架,比如MapReduce、Spark,它的特点是具有较高的容错性,适合较大规模的批处理作业由于实现的是基于文件的shuffle方案,因此失败重跑时只须重跑失败的task、stage,而无须重跑整个job;
2、 基于管道的pushbasedshuffle,比如Flink、Storm等基于管道的pushbasedshuffle的实现方式多用于Flink、Storm等流式框架,或是一些MPP框架,如Presto、Greenplum等,它的特点是具有较低的延迟和较高的性能,但是比较大的问题是由于没有将shuffle数据持久化下来,因此任务的失败会导致整个作业的重跑;
Shuffle是分布式框架里面最为重要的一个环节,shuffle的性能和稳定性直接影响到了整个框架的性能和稳定性,因此改进shuffle框架是非常有必要的。
业务痛点
Spark在云原生场景下的挑战
基于本地磁盘的shuffle方式,使得Spark在云原生、存储计算分离、在离线环境中有极大的使用限制:
1、 在云原生环境中,serverless化是服务部署的一个目标,但是由于弹性或是抢占情况的发生,节点或是容器被抢占导致executor被kill是一种常态,现有的shuffle无法使计算做到serverless,在节点/容器被抢占时往往需要重新计算shuffle数据,有很高的代价;
2、 在线集群通常只有少量的本地磁盘和大量的CPUcore,因此其计算和IO是不平衡的,在这样的集群中根据算力去调度作业时非常容易将磁盘写满;
3、 现在越来越多的数据中心架构采用了存储计算分离的部署方式,在这样的部署方式下基于本地磁盘的shuffle方式首先会遇到的问题是由于本地磁盘的不足导致无法存放shuffle数据;其次,虽然可以通过块存储(RBD)的方式来解决本地存储,但是对于shuffle这样的IO使用模式,使用块存储会带来极大的网络开销和性能问题;
Spark在生产环境的挑战
当前分布式计算平台上大多数的批处理作业是Spark作业,少量是MR作业,相比于MR作业,Spark作业的稳定性较差,而稳定性的问题中至少有一半是由于shuffle的失败造成的。
Shuffle失败导致的任务陷入重试,严重拖慢作业。shuffle fetch失败会导致map任务重跑重新生成shuffle数据,然后再重跑reduce任务,如果reduce任务反复失败会导致map任务需要反复重跑,在集群压力较高的情况下重跑的代价很高,会严重影响作业。

邵铮在SPARK-1529中就有相应的评论,地址如下:
https://issues.apache.org/jira/browse/SPARK-1529
对于超大规模的shuffle数据(T级别以上的shuffle量)的作业,非常难以顺利跑过,这里面的问题有:
1、 shuffle数据非常容易将磁盘写满只有通过反复调整和重试使executor尽量分布到多的节点(anti-affinity)上避免这个问题;
2、 海量的shufflepartition导致非常多的shuffle连接,使得shuffle框架极容易发生超时问题,以及非常高的随机访问IO所导致的问题;
基于本地磁盘的shuffle方式有较为严重的写放大问题和随机IO问题,当任务数量达到10K乃至100K以上时,随机IO的问题非常严重,严重影响了集群的性能和稳定性。
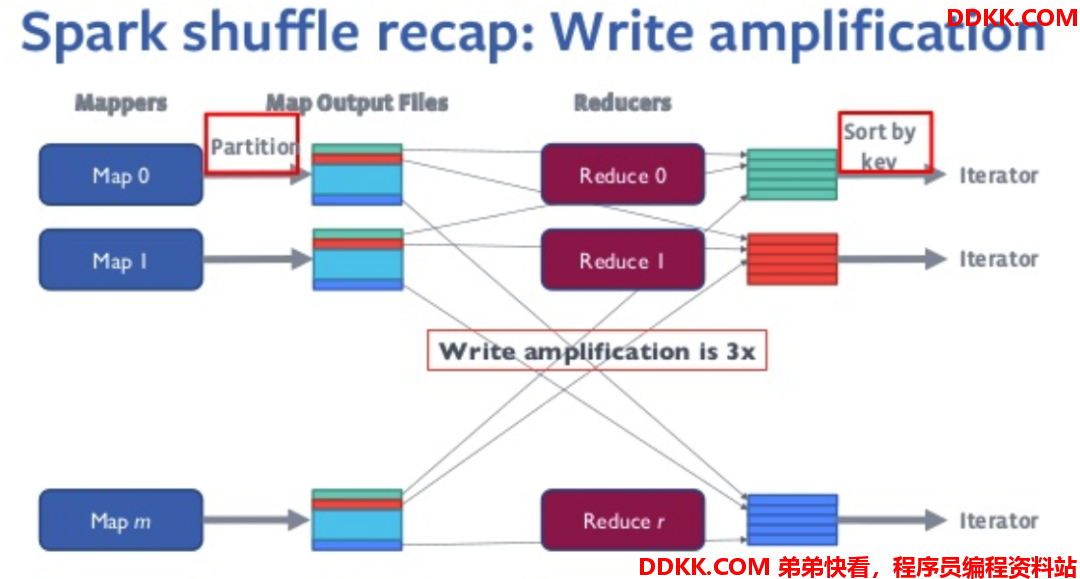
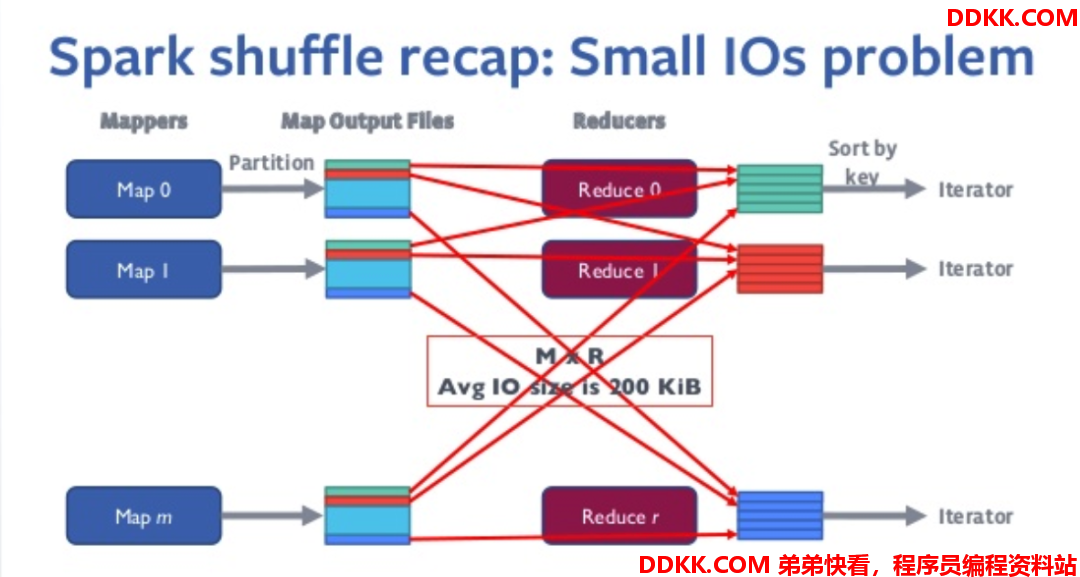
因此实现一个更好的、能解决上述业务痛点的shuffle框架显得尤为重要。
业界趋势
业界在shuffle[1]上也有了多年的探索,围绕各自的业务场景构建了相应的能力,这里罗列一下主流公司在shuffle上所做的工作。
百度DCE shuffle
百度DCE shuffle是较早在业内实践并大规模使用的remote shuffle service方案,它设计的初衷是为了解决几个问题,一是在离线混部,二是提高MR作业的稳定性和处理规模。百度内部的MR作业已经改造接入DCE shuffle并使用多年,现在Spark批处理作业也已经改造使用DCE shuffle做为其shuffle引擎。
Facebook Cosco Shuffle
Facebook Cosco Shuffle的设计初衷和百度非常接近,Facebook数据中心的构建是存储计算分离,因此传统的基于本地文件的shuffle方式有较大的开销,同时在Facebook中最大的作业规模shuffle量达100T,这对shuffle有极大的挑战,因此Facebook实现了基于HDFS的remote shuffle service - Cosco Shuffle。
Google Dataflow Shuffle
Google Dataflow Shuffle是Google在Google Cloud上的Shuffle服务,针对云上的弹性易失环境,Google开发了一套Dataflow Shuffle服务供Google Cloud的大数据服务使用。Dataflow Shuffle也是一套remote shuffle service,将shuffle存储移到了VM之外,提供了计算作业更大的弹性。
Uber Zeus
Uber 为了解决上述提到的Shuffle痛点,也实现了Zeus这个Remote Shuffle Service,该项目已经开源。从设计文档及实现看,他们部署了多台Shuffle Server用来接收并聚合Shuffle数据,采用SSD作为存储介质来提升Shuffle性能。
阿里ESS
阿里的ESS(EMR Remote Shuffle Service)主要是为了解决Spark on Kubernetes面临的计算存储分离问题,使得Spark能够适配云原生环境。
业务价值
实现Remote Shuffle Service,能带来几点业务价值:
- **云原生架构的支持:**现有的分布式计算框架(如Spark需要依赖本地磁盘存储Shuffle数据)极大地限制了云原生的部署模式。使用Remote Shuffle Service可以有效减少对本地磁盘的部分依赖,支持集群的多种部署模式,提升资源利用率,助力云原生架构。
- **提升Spark作业shuffle稳定性:**对于shuffle数据量达到TB,甚至10TB级别,这类任务会对磁盘空间造成很大压力,同时,Task数据较多还造成了网络访问的压力,最终导致失败率较高,而Remote Shuffle Service能更好的解决这些问题,使得业务方能平稳运行这类任务。
Firestorm介绍
目标
在腾讯内部每天有上百万的Spark任务在运行,上述各类Shuffle问题也经常遇到。同时,为了更好的利用硬件资源,计算存储分离的部署模式也在逐步推进。因此,我们进行了Firestorm的研发,该项目的目标如下:
- 支持大Shuffle量的任务(如,TeraSort 40T+)
- 支持云原生的部署模式(如,计算存储分离部署模式)
- 支持多种存储系统(LocalFile, HDFS, COS等)
- 支持数据完整性校验
- 性能与计算引擎的原生方案接近
架构设计方案
Remote Shuffle Service的架构如下:
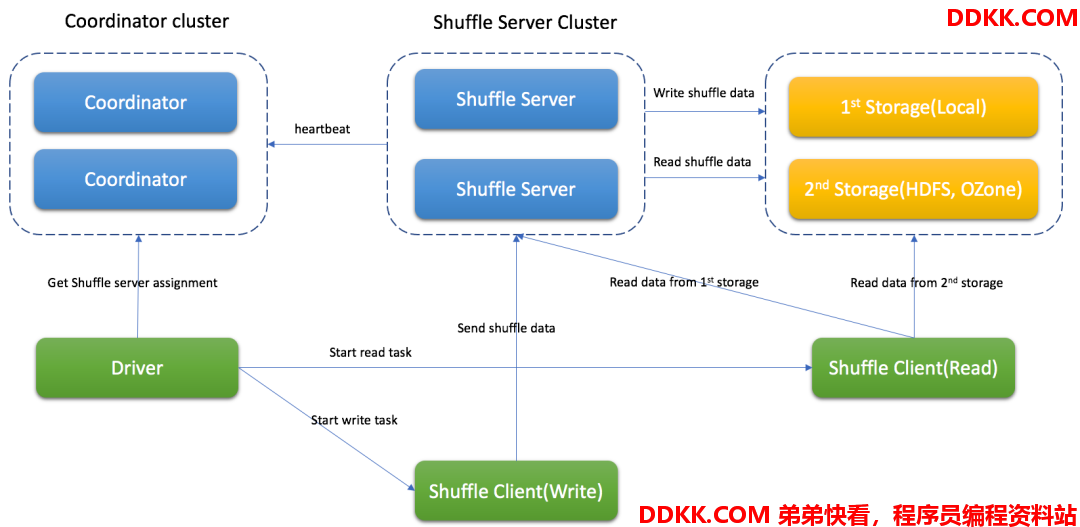
其中,各个组件的功能如下:
- Coordinator,基于心跳机制管理Shuffle Server,存储Shuffle Server的资源使用等元数据信息,还承担任务分配职责,根据Shuffle Server的负载,分配合适的Shuffle Server给Spark应用处理不同的Partition数据。
- Shuffle Server,主要负责接收Shuffle数据,聚合后再写入存储中,基于不同的存储方式,还能用来读取Shuffle数据(如LocalFile存储模式)。
- Shuffle Client,主要负责和Coordinator和Shuffle Server通讯,发送Shuffle数据的读写请求,保持应用和Coordinator的心跳等。
- 在Shuffle Server和Storage交互过程中,解耦了Storage Handler组件,基于这个组件可以灵活接入不同的存储,满足各种存储需求。
架构设计差异点
相较于业界的其它方案,Firestorm有其独特的地方:
- 架构方面,引入Coordinator组件,更好的管理Shuffle Server并基于Shuffle Server的节点状态合理分配Shuffle任务,集群本身也支持灵活的横向扩展以满足生产需要
- 技术方面,解耦了存储模块,支持新的Shuffle数据存储方式仅需要实现相关接口。作为整个系统最重要的数据校验部分,除了CRC,数据去重等实现外,还增加了读写数据一致性校验,使得数据在传输过程中更安全可靠。
- 运营方面,Firestorm提供了各类运行统计数据并接入内部监控平台,便于观察集群整体状况,了解性能瓶颈,并能在异常状况下及时收到告警信息。
整体流程
基于Firestorm的整体Shuffle流程如下:
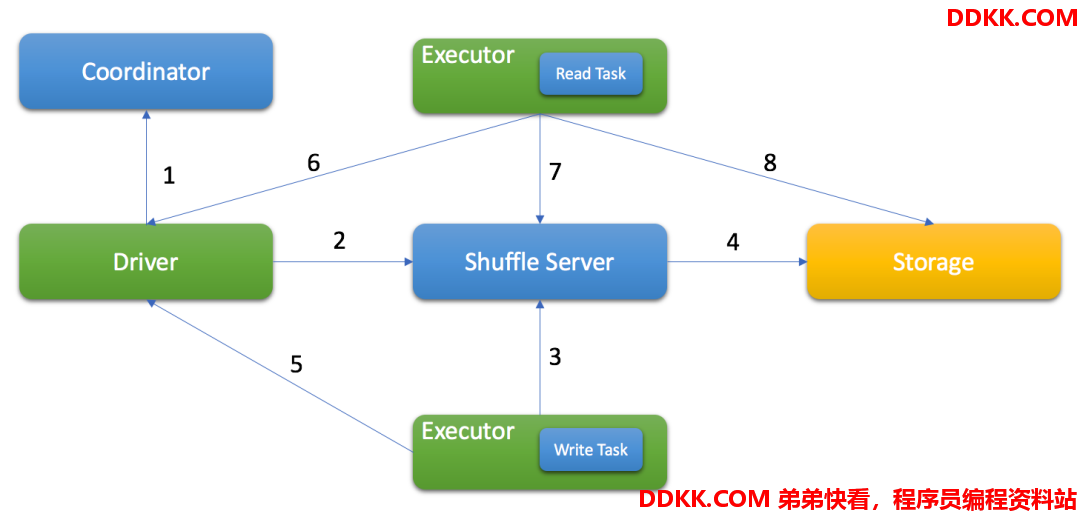
1、 Driver从Coordinator获取分配信息;
2、 Driver向ShuffleServer注册Shuffle信息;
3、 基于分配信息,Executor将Shuffle数据以Block的形式发送到ShuffleServer;
4、 ShuffleServer将数据写入存储;
5、 写任务结束后,Executor向Drive更新结果;
6、 读任务从Driver侧获取成功的写Task信息;
7、 读任务从ShuffleServer获得Shuffle元数据(如,所有blockId);
8、 基于存储模式,读任务从存储侧读取Shuffle数据;
写流程
在写Shuffle数据的时候,需要考虑内存合理使用,文件的异步写入,Shuffle数据的合并等,具体流程如下:
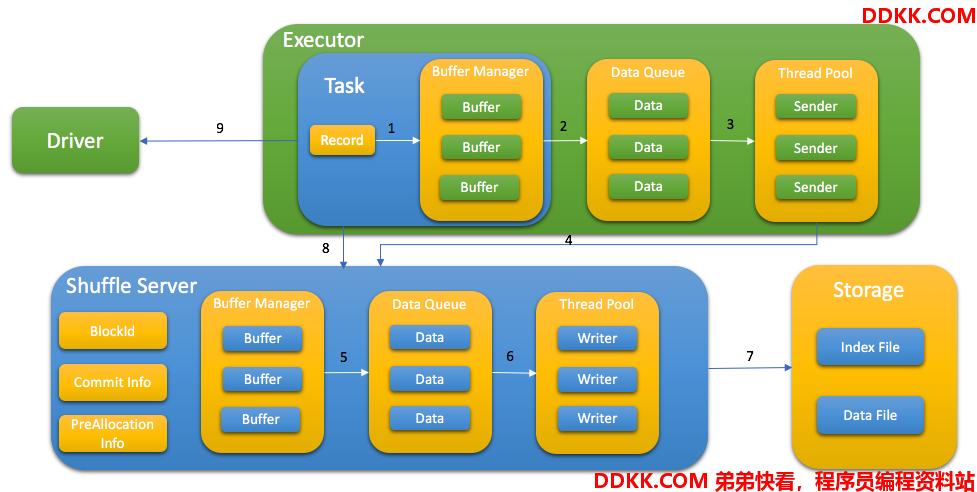
1、 Task基于PartitionId,将数据发送到对应Buffer中;
2、 当Buffer到达阀值时,将Buffer的数据发送到数据队列里;
3、 不断的从数据队列里获取数据,并提交给发送线程;
4、 发送线程先向ShuffleServer请求内存空间,再将数据发送至ShuffleServer的缓冲区;
5、 ShuffleServer缓冲区到达阀值后,将Shuffle数据发送至写队列;
6、 不断从写队列中获取数据,并提交给写入线程;
7、 基于Shuffle数据信息(ApplicationId,ShuffleId,PartitionId)获取存储路径,将Shuffle数据写入Index文件和Data文件中;
8、 Task写入完成后,告知ShuffleServer任务已完成并获取当前所有任务完成数,假如任务完成数小于预期值,则进入下一步,假如任务完成数大于预期值,则发送信息给ShuffleServer将缓冲区相关信息写入存储,并等待写入结果,成功后进入下一步;
9、 Task完成后,将TaskId记录在MapStatus中,并发送到Driver,该步骤用来支持Spark推测执行功能;
读流程
在读Shuffle数据的时候,主要考虑数据的完整性,具体流程如下:
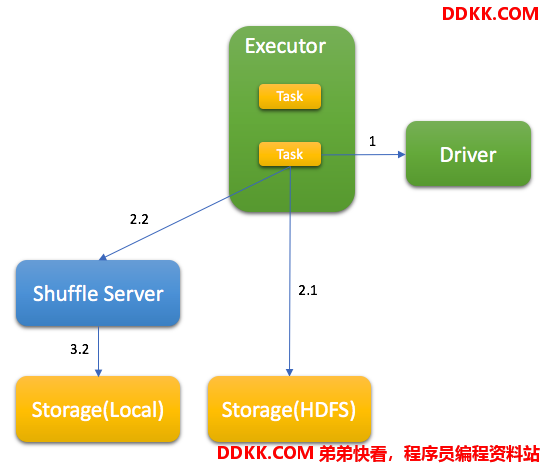
1、 从Driver侧获取Write阶段所有成功TaskId;
2、 读取shuffle数据,先读取Index文件,校验BlockId是否都存在,基于Index文件Offset信息,再读取Data文件,获取shuffle数据;
· 如果Storage是HDFS,则直接从HDFS读取
· 如果Storage是Local File,则需要通过Shuffle Server读取文件
Shuffle文件
对于Shuffle数据,存储为Index文件和Data文件,其中实际的Shuffle数据以Block形式存储在Data文件中,而Index文件则存储每个Block的元数据,具体存储信息如下:
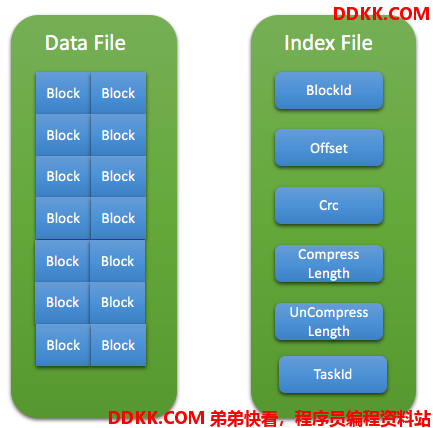
- BlockId: 每个Block的唯一标识,long型,前19位为自增Int,中间20位为PartitionId,最后24位为TaskId
- Offset: Block在Data文件里的偏移量
- Crc: Block的Crc校验值,该值在Block生成时计算并最终存储在Index文件,读取Block时用来验证数据完整性
- CompressLength: Block压缩后的数据长度
- UnCompressLength: Block未压缩的数据长度,用来提高读取时解压效率
- TaskId: 用来过滤无效的block数据
数据校验
数据的正确性对于Shuffle过程来说是最为关键的,下面介绍了Firestorm如何保障数据的正确性:
1、 写任务为每个Block数据计算CRC校验值,读任务会对每个Block基于CRC进行校验,避免数据不一致;
2、 每个BlockId存储在ShuffleServer侧,读取数据的时候,将验证所有BlockId都被处理,避免数据丢失;
3、 成功的Task信息将记录在Driver侧,读取时过滤冗余的Block,避免推测执行导致的数据不一致问题;
支持多存储
由于存储的选择较多,LocalFile,HDFS,OZONE,COS等,为了能方便接入各类存储,在设计上对存储做了解耦,抽象了读写接口。对于不同的存储只需要实现相关接口,即可作为Shuffle数据的后端存储使用。
Firestorm 收益
支撑云原生的部署模式
Firestorm目前在腾讯内部已经落地于近万个节点的在离线混布集群,每天支撑近5W的分布式计算作业,每天的Shuffle数据量接近2PB,任务失败率从原先的14%降低到了9%,已经达到了初期制定的第一阶段目标,助力分布式计算上云。
改善Shuffle阶段的稳定性及性能
基于TPC-DS 1TB数据量,我们对使用原生Spark Shuffle 和 使用Firestorm进行了性能对比测试,测试环境如下:
- 3台服务器作为计算节点,80 core + 256G + HDD
- 3台服务器作为ShuffleServer,112core + 128G + HDD存储Shuffle数据
TPC-DS的SQL复杂程度不一,对于简单的SQL,由于Shuffle数据量较少,原生Spark Shuffle表现更好,但是性能优势并不明显,而对于复杂的SQL,涉及到大量的partition的Shuffle过程,则Firestorm表现更稳定,且性能有大幅提升,下面将分别描述这2种场景:
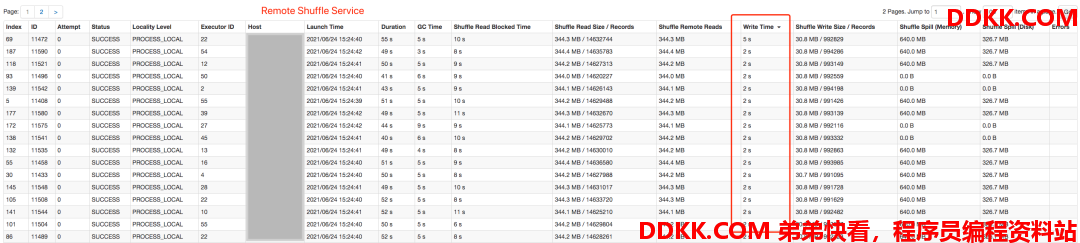
**场景1,**简单SQL,以query43为例,下图是query43的Stage图,由2个stage组成,shuffle数据量非常少,使用原生Spark Shuffle整个query运行耗时12秒左右,而使用Remote Shuffle Service则需要15秒左右。

那这个时间是损耗在哪里了呢?下图展示了第一个stage的相关耗时,可以看到在write time这一列的统计上,原生Spark Shuffle是有性能优势的,耗时都在毫秒级别,而使用Firestorm,由于在shuffle write阶段增加了RPC通信,导致耗时增加,再加上任务数量需要分多批次跑完,每批次都会产生几百毫秒的差值,最终造成了原生Spark Shuffle在这个query上有了3秒左右的性能优势。
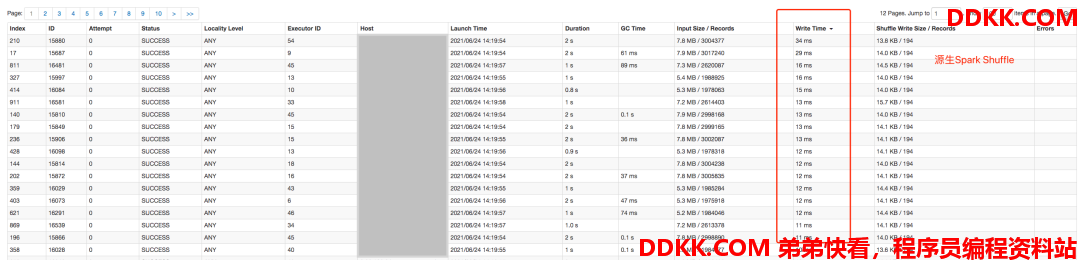
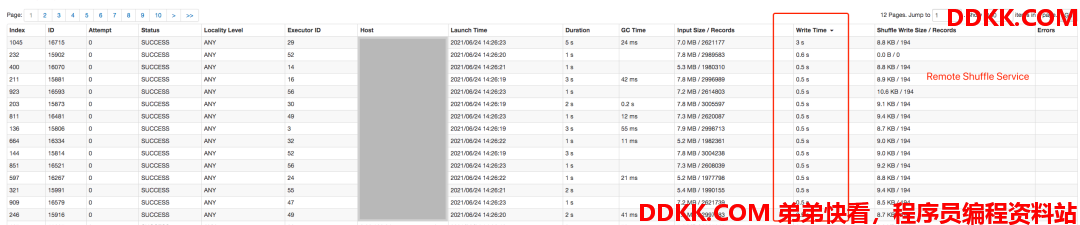
随着SQL的执行时间增加,这类性能优势会逐步下降,几乎可以忽略不计,这一类的SQL有query1, query3等等,这里就不一一列举了。
**场景2,**复杂SQL,以query17为例,下图展示了分别使用不同shuffle模式的Stage图,从图中可以看到这个SQL的stage数量多,且shuffle数据量大,执行的耗时上使用原生Spark Shuffle为8分钟左右,而使用Remote Shuffle Service仅为3分钟左右。


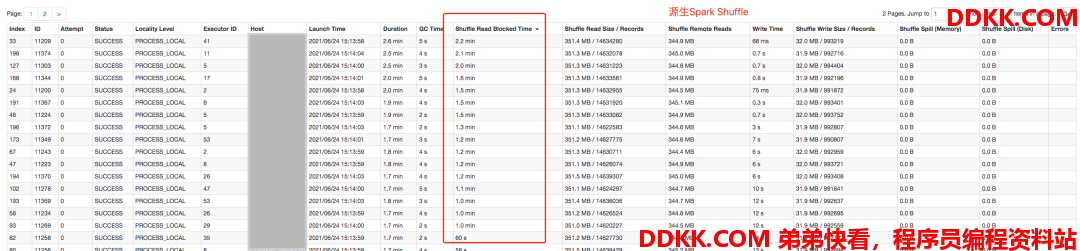
将耗时最长的Stage展开,进一步看下具体的耗时比对,先看下Shuffle Read的耗时,由于原生Spark Shuffle需要从各个Executor上拉取数据,涉及到大量的网络开销以及磁盘的随机IO,耗时非常长,甚至达到了2分钟,而Remote Shuffle Service由于读取时降低了网络开销,且读取的是整块Shuffle数据,所以耗时短且较为稳定。
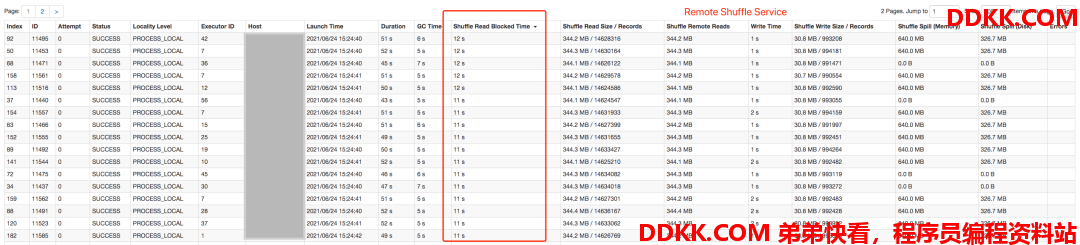
再来看下Shuffle Write的耗时,原生Spark Shuffle依然耗时长,且不稳定,这个主要是由于这个时间点,计算节点同时处理Shuffle Read和Shuffle Write,都需要对本地磁盘频繁访问,且数据量较大,最终导致了耗时大幅增长,而Remote Shuffle Service在读写机制上很好的规避了这类问题,所以整体性能有了大幅提升且更稳定。
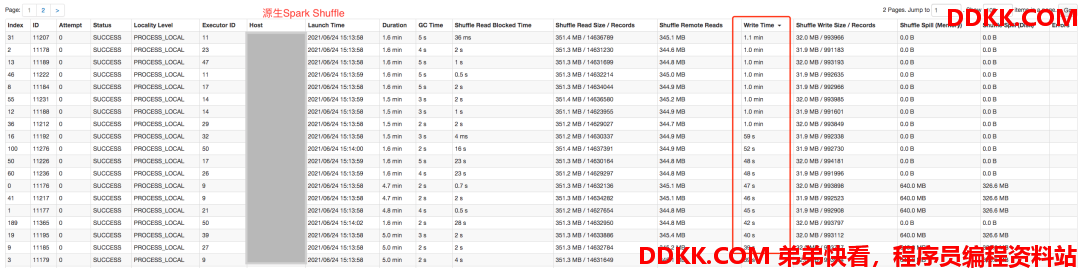
这类SQL还有query25,query29等待,这里就不一一举例了。
除了上述2个场景外,还有部分query由于shuffle数据量更大,使用原生Spark Shuffle不能正常跑出结果,而使用Remote Shuffle Service则可以顺利运行,如,query64,query67。
总的来说,在Shuffle数据量较小的场景下,相比原生Spark Shuffle,Remote Shuffle Service并无优势,性能有5%-10%的小幅下降或基本持平,而在Shuffle数据量大的场景下,Remote Shuffle Service则优势明显,基于TPC-DS的部分SQL测试结果显示,性能有50% - 100%的提升。
总结
本文介绍了现有Spark Shuffle实现的各类问题及业界的应对方式,结合腾讯公司内部的Spark任务实际运行状况,介绍了我们自研的Firestorm的架构,设计,性能,应用等。希望在云原生的场景中,Firestorm能更好的协助分布式计算引擎上云。