一、前言
在过去50年计算机的发展历史中,推动计算技术潮流滚滚向前的一大分支就是对于计算资源的快速调度和有效利用,围绕这这个方向,在如下计算特性上做了不同角度和深度的技术演进:

这些技术演进的根本意义还是在于通过基于隔离、限制和标准化的资源共享来提升资源的使用效率(包括资源调度效率和资源占用效率)。
从大型机、物理单机、计算集群到虚拟机技术、容器技术再到serverless技术,计算资源的快速调度能力和使用率都在不断得到提升;尤其是从计算资源虚拟化技术开始在硬件层面得到突破开始,云计算技术成为计算资源管理的主流方向,带来了全新的资源管理视野;而发端于2013年的docker容器技术,更是将虚拟化技术变得更加轻量,使得计算资源的调度能力和使用率上升到虚拟机技术之上的一个层次。
本文将对于Docker技术的前身LXC以及容器技术依赖的namespace、cgroup以及UnionFS技术等进行分析,对docker技术栈进行全面的介绍。
二、LXC container技术
在操作系统领域中,container技术不是一个新概念,针对不同资源在不同层次都有container技术的尝试:
- 1979: UNIX Chroot
- 2000: FreeBSD Jails
- 2004: Solaris Zones
- 2008: LXC(Linux-Vserver、OpenVZ 和 FreeVPS)
- 2013: Docker
而LXC是2008年出现在Linux生态中的,基于Kernel提供的资源调度和管理能力的,面向用户侧的易于使用的工具,它是一系列内核技术和胶水技术融合的产品。之前像Linux-Vserver、OpenVZ 和 FreeVPS之类的container技术都是需要patch内核之后再使用的,LXC是第一个intree的kernel native container方案。LXC使用的内核技术包括:
- Kernel namespaces (ipc, uts, mount, pid, network and user)
- Apparmor and SELinux profiles
- Seccomp policies
- Chroots (using pivot_root)
- Kernel capabilities
- CGroups (control groups)
根据官网的描述,LXC对标的是近似虚拟机使用体验的共享内核应用运行环境:
LXC containers are often considered as something in the middle between a chroot and a full fledged virtual machine. The goal of LXC is to create an environment as close as possible to a standard Linux installation but without the need for a separate kernel.
LXC的资源共享是在借助于namespace进行资源隔离、借助于cgroup进行资源限制、借助于LXC API和工具集实施标准化部署的基础上实现的。虽然对标的是虚拟机体验场景,和虚拟机技术KVM相比的区别主要是在于Kernel的共享和没有硬件模拟这个overload:
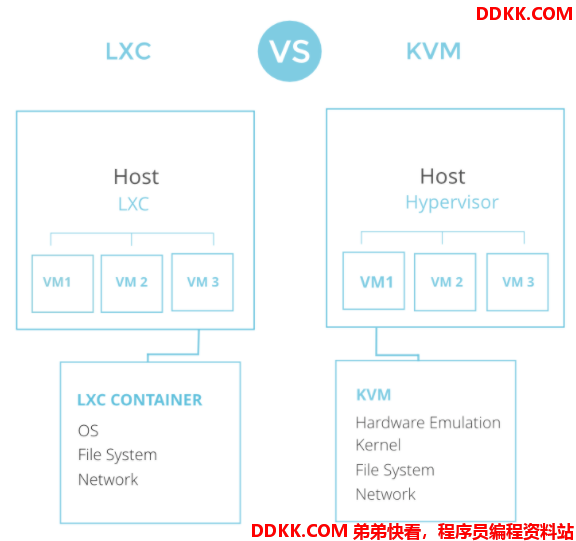 https://archives.flockport.com/lxc-guide/
https://archives.flockport.com/lxc-guide/
三、Docker Container技术
在技术领域,一般最为闪亮的项目都是开辟创新性技术的项目,这些项目能够开创一个全新的领域,比如Linux Kernel;而通过将各种技术进行集成然后得到领域性的突破,Docker技术算是为数不多、影响也巨大的案例之一。Docker技术是典型的将不同侧面优秀的技术通过胶水技术融合在一起,而形成的更加优秀、有影响力和有商业价值的技术。
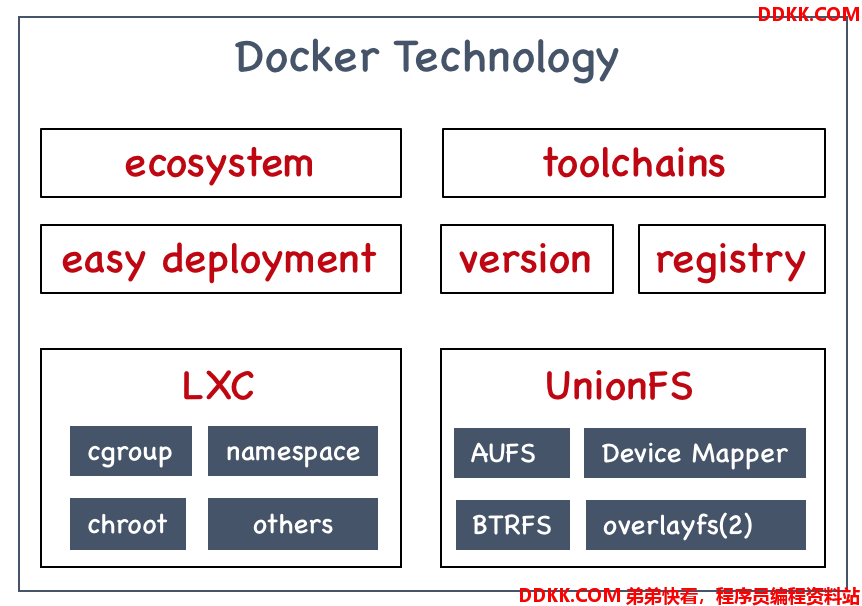
从上图可以看到,Docker技术一方面熟练运用底层Kernel的资源管控(LXC相关技术)、文件系统等技术,另一方面由创造性的开创了适合生产大规模快速部署和演进的优良生态系统,两者叠加,使得Docker技术最终成为新一代的虚拟化技术的发展方向。通过上图可以看到,Docker提供是远远超出LXC技术的能力超集,根据文章《Understanding the key differences between LXC and Docker》的描述,Docker在可移植性、镜像共享和重用、镜像构建和版本管理、工具生态等方面要远胜于LXC,使得Docker容器技术成为以应用为中心的研发思想的最理想载体。
Docker方案的核心业务逻辑都被放置到了Docker Daemon中,Daemon中的Engine模块负责提交Job来完成从镜像下载、网络配置等一系列的Docker容器准备工作:
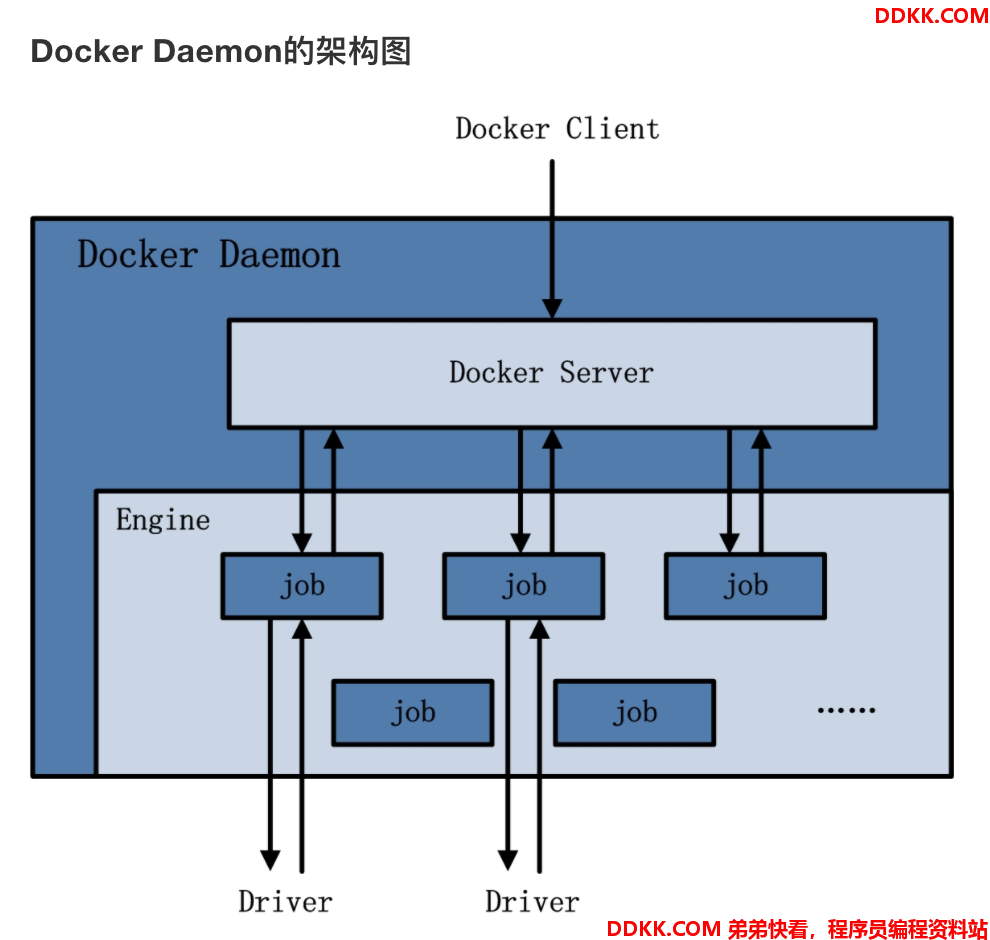 https://www.huweihuang.com/kubernetes-notes/docker/docker-architecture.html
https://www.huweihuang.com/kubernetes-notes/docker/docker-architecture.html
接下来的章节将对Docker容器技术涉及三大核心技术:namespaces、cgroups和UnionFS进行分析。
四、namespace技术: docker资源隔离
要进行资源的进程间共享,就要限定进程任务的环境边界(隔离)和资源边界(限额),namespace技术和cgroup就是分别用来限定环境边界和资源边界的。一般而言,进行环境边界的限定有两种方法,一种是打造客观隔离设施进行硬隔离(比如独立物理机、虚拟机等),另外一种是打造主管隔离环境进行软隔离,容器所采用的方法就是通过namespace内核技术限定进程对于周边runtime的感知来打造一个相对独立环境。
namespace技术从Kernel 2.4.19开始引入,根据文章https://lwn.net/Articles/531114/的描述:
The purpose of each namespace is to wrap a particular global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
所以这项技术的目的是通过进一层的抽象技术,将一个个的全局资源可控的映射给进程,使其产生能独占分配给它资源的错觉,现在namespace支持的系统资源包括:
| Namespace类型 | 系统调用参数 | 内核版本 | 隔离内容 |
|---|---|---|---|
| Mount Namespace | CLONE_NEWNS | 2.4.19 | 挂载点(文件系统) |
| UTS Namespace | CLONE_NEWUTS | 2.6.19 | 主机名与域名 |
| IPC Namespacce | CLONE_NEWIPC | 2.6.19 | 信号量、消息队列和共享内存 |
| PID Namespace | CLONE_NEWPID | 2.6.24 | 进程编号 |
| Network Namespace | CLONE_NEWNET | 2.6.29 | 网络设备、网络栈、端口等等 |
| User Namespace | CLONE_NEWUSER | 3.8 | 用户和用户组 |
而根据WiKi链接https://en.wikipedia.org/wiki/Linux_namespaces的描述,最近又增加了对于Control group (cgroup) Namespace(March 2016 in Linux 4.6)和Time Namespace(March 2020)的支持,使得各个进程可以拥有自己独立的cgroup和time资源。
在内核实现层面,内核引入了struct nsproxy来统一管理进程所属的namespace,在task_struct中只需存一个指向struct nsproxy的指针就行了:
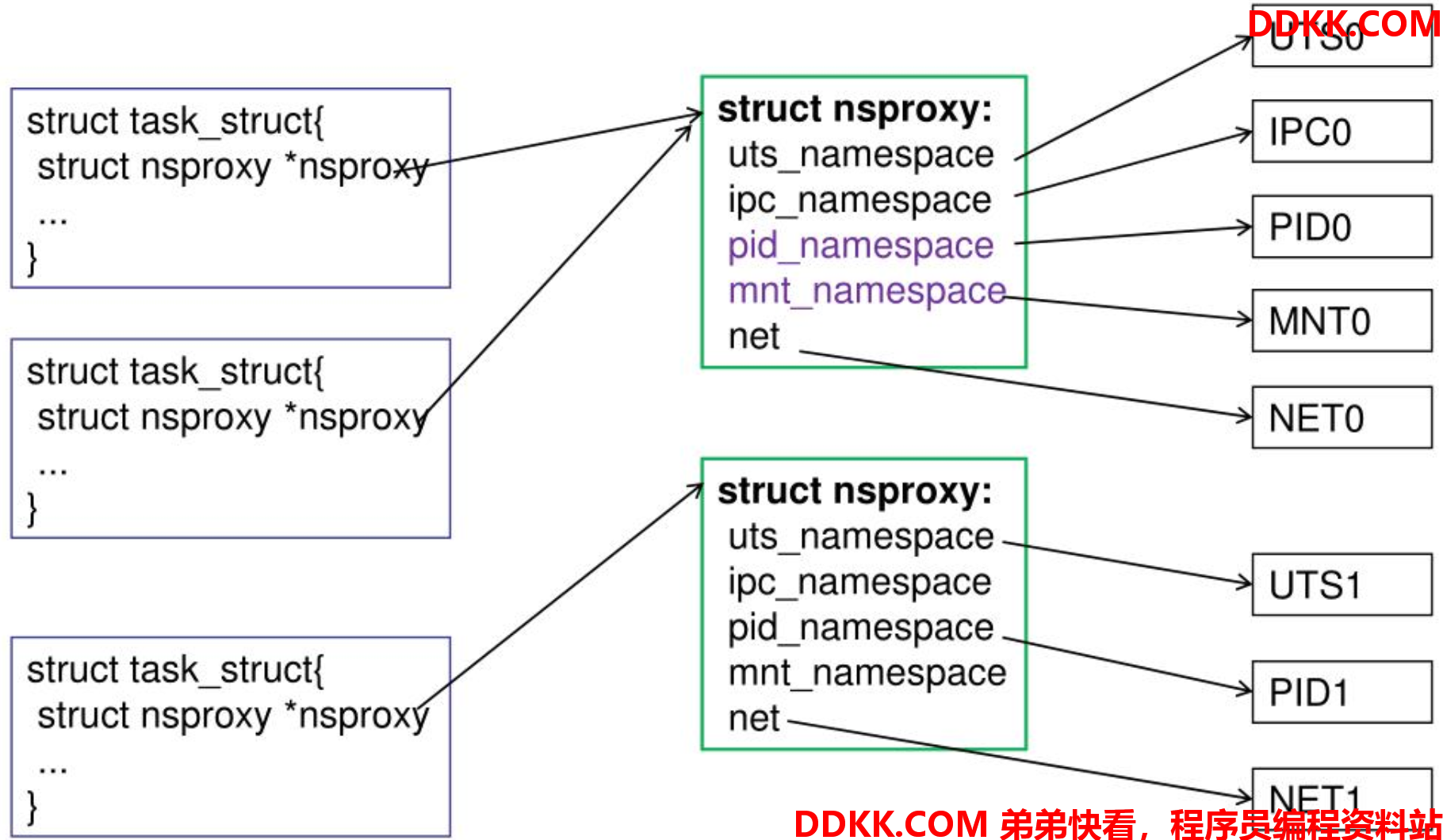
struct nsproxy定义如下:
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
extern struct nsproxy init_nsproxy;
针对于namespace,只有三个系统操作,分别是创建、加入和离开某个namespace,对应的systemcall分别是clone()、setns()和unshare()。通过namespace技术,容器可以拥有独立的主机名、网络、文件目录、PID系统、IPC环境等,完全可以满足一般进程的运行需求。
namespace在文件系统的接口位置如下:
[root@k8s-master-01 ~]# ls /proc/29222/ns -l
总用量 0
lrwxrwxrwx 1 root root 0 8月 11 15:41 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 8月 11 15:41 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 8月 11 15:06 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 8月 11 15:41 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 8月 11 15:41 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 8月 11 15:41 uts -> uts:[4026531838]
五、cgroup技术: docker资源限制
通过namespace可以限定进程能感知的运行环境,在这个隔离的运行环境中,进程可以使用CPU、内存、网络和磁盘等资源完成进程的业务。但是这些资源在全局视图中是唯一的、可分割但是不可长期独占的,所以如果要让各个进程能够按照既定规则合理分享这些资源,就需要使用cgroup技术。根据文档https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt,cgroup内核技术的主要目的是:
Control Groups provide a mechanism for aggregating/partitioning sets of tasks, and all their future children, into hierarchical groups with specialized behaviour.
所以cgroup的工作是将一批进程及其子进程标示成同一个cgroup进程组,形成层级的关系,并且对这个进程组实施统一的资源配置和管控。cgroup是在2007年被合并进入Kernel版本 2.6.24的,根据Wiki https://en.wikipedia.org/wiki/Cgroups,它提供的功能特性包括:
- 资源用量控制(Resource limiting): limiting groups can be set to not exceed a configured memory limit, which also includes the file system cache
- 资源优先级管理(Prioritization): some groups may get a larger share of CPU utilization or disk I/O throughput
- 资源用量审计(Accounting): measures a group's resource usage, which may be used, for example, for billing purposes
- 进程组活动控制(Control): freezing groups of processes, their checkpointing and restarting
cgroup包含任务、控制组、子系统和层级树等概念:
- task(任务) :系统中的进程。
- cgroup(控制组) :cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统,一个任务可以加入某个 cgroup,也可以进行 cgroup 迁移
- subsystem(子系统) :cgroups 中的 subsystem 进行资源调度,例如 CPU 子系统控制 CPU 时间分配,内存子系统限制内存使用量
- hierarchy(层级树) :hierarchy 由一系列 cgroup 以一个树状结构排列而成,每个 hierarchy 通过绑定对应的 subsystem 进行资源调度
当前cgroups支持的子系统有:
- blkio — 这个子系统为块设备设定输入 / 输出限制, 比如物理设备(磁盘, 固态硬盘,USB 等等).
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问.
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告.
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点.
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备.
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务.
- memory — 这个子系统设定 cgroup 中任务使用的内存限制, 并自动生成内存资源使用报告.
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包, 可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包.
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于 HugeTLB 系统进行限制, 这是一个大页文件系统.
在文件系统的体现如下:
mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
ls /sys/fs/cgroup/cpu,cpuacct
cgroup.clone_children cgroup.sane_behavior cpuacct.usage_percpu cpu.rt_period_us cpu.stat release_agent user.slice
cgroup.event_control cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us kubepods.slice system.slice
cgroup.procs cpuacct.usage cpu.cfs_quota_us cpu.shares notify_on_release tasks
task group、cgroup、hierarchy和subsystem之间的关系如下:
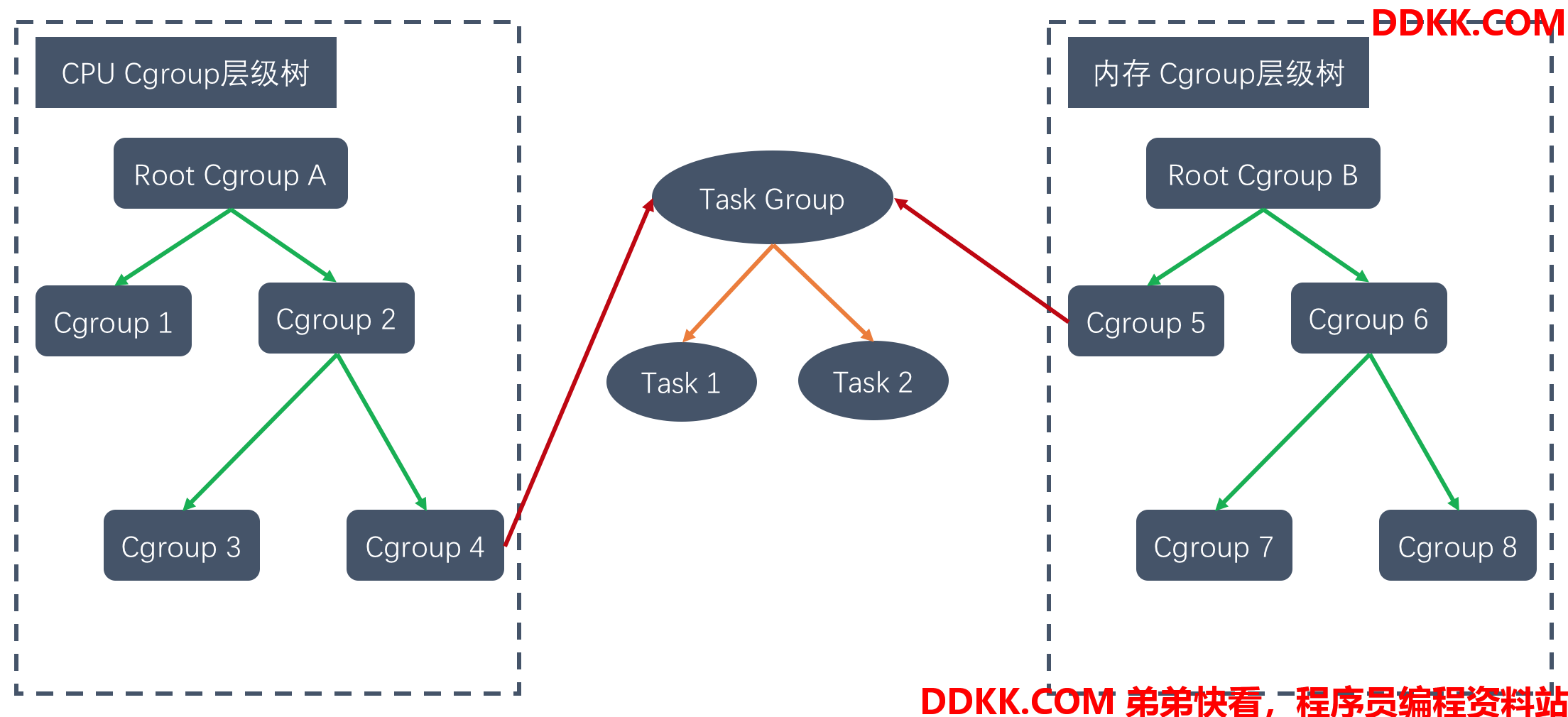
在内核实现方面,task_struct里面与 cgroup 相关的字段主要有两个,一个是css_set *cgroups,另一个字段是list_head cg_list。css_set *cgroups,表示指向css_set(包含进程相关的 cgroups 信息)的指针,一个 task 只对应一个css_set结构,但是一个css_set可以被多个 task 使用;list_head cg_list,是一个链表的头指针,这个链表包含了所有的链到同一个css_set的 task 进程:
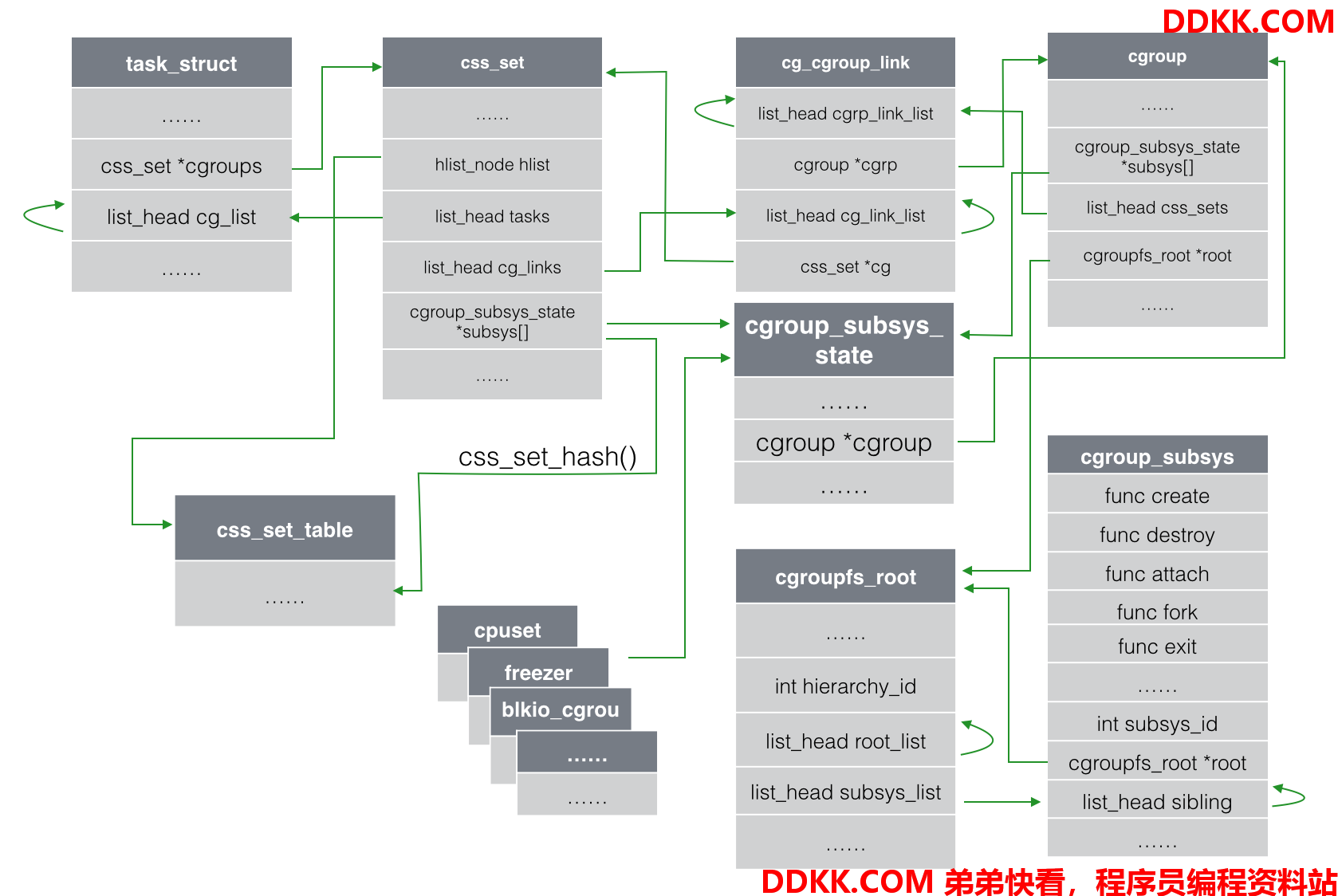 https://www.infoq.cn/article/docker-kernel-knowledge-cgroups-resource-isolation
https://www.infoq.cn/article/docker-kernel-knowledge-cgroups-resource-isolation
六、UnionFS技术: docker文件系统
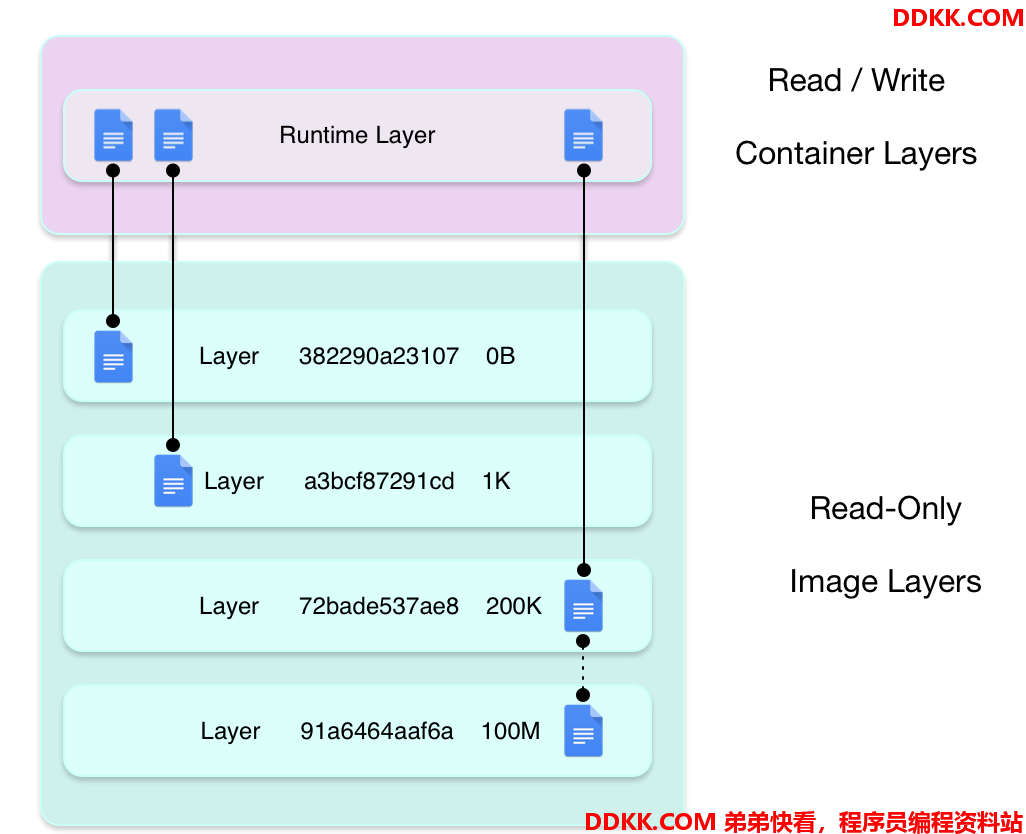
Docker强大的可移植性一方面体现在其运行环境的标准化(namespace)和资源控制技术标准化(cgroup),还在于其特定的分层的可共享的镜像技术,这种分层的可共享的文件系统可以实现构建时增量内容增加,发布时也只需要传输增量内容,非常适合大规模、标准化的发布。
Docker最早支持AUFS,后续又陆续支持Device Mapper、BTRFS、Overlayfs等文件系统。现在很多Kubernetes集群使用的都是overlayfs2版本。
UnionFS的技术特点在于:
- 支持将多个路径挂载到同一个目录下面,形成一个容器可见的单一文件系统
- 支持Copy on Write技术,可以实现文件系统快速共享挂载
七、总结
Docker容器技实现了计算资源的快速调度和有效利用:
- 隔离:通过namesapces技术进行主机名、网络、文件目录、PID系统、IPC环境等全局资源的隔离
- 共享:多个容器使用同一个内核并通过cgroup进行全局资源的共享
- 限制:cgroup进行包括CPU、内存、网络等资源的进程集层级的用量限制
- 标准化:借助Docker的生态工具进行标准化操作