哈希表的概念
哈希表(Hash Table)是一种特殊的数据结构,它最大的特点就是可以快速实现查找、插入和删除。
我们知道,数组的最大特点就是:寻址容易,插入和删除困难;而链表正好相反,寻址困难,而插入和删除操作容易。那么如果能够结合两者的优点,做出一种寻址、插入和删除操作同样快速容易的数据结构,那该有多好。这就是哈希表创建的基本思想,而实际上哈希表也实现了这样的一个“夙愿”,哈希表就是这样一个集查找、插入和删除操作于一身的数据结构。
哈希表(Hash Table):也叫散列表,是根据关键码值(key-value)而直接进行访问的数据结构,也就是我们常用到的map。
哈希函数:也称为是散列函数,是Hash表的映射函数,它可以把任意长度的输入变换成固定长度的输出,该输出就是哈希值。哈希函数能使对一个数据序列的访问过程变得更加迅速有效,通过哈希函数,数据元素能够被很快的进行定位。
哈希表和哈希函数的标准定义:若关键字为k,则其值存放在h(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为哈希函数,按这个思想建立的表为哈希表。
设计出一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题。
但是,一般散列函数都面临着冲突的问题。两个不同的关键字,由于散列函数值相同,因而被映射到同一表位置上。该现象称为冲突(Collision)或碰撞。发生冲突的两个关键字称为该散列函数的同义词(Synonym)。
设m和n分别表示表长和表中填入的结点数,则将α=n/m定义为散列表的装填因子(Load Factor)。α越大,表越满,冲突的机会也越大。通常取α≤1。
哈希表的实现方法
哈希表的实现就是映射函数构造,看某个元素具体属于哪一个类别。如何构造我们要考虑两个问题:
- n个数据原仅占用n个地址,虽然散列查找是以空间换时间,但仍希望散列的地址空间尽量小。
- 无论用什么方法存储,目的都是尽量均匀地存放元素,以避免冲突。
所以,我哈希表的映射函数构造方法也有很多,常见的有:直接定址法、 除留余数法、 乘余取整法、 数字分析法、 平方取中法、 折叠法、 随机数法等。
1、直接定位法
Hash(key) = a·key + b (a、b为常数)
优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突.
缺点:要占用连续地址空间,空间效率低。
**例:**关键码集合为{100,300,500,700,800,900}, 选取哈希函数为Hash(key)=key/100, 则存储结构(哈希表)如下:

2、除留余数法
Hash(key) = key mod p (p是一个整数)
特点:以关键码除以p的余数作为哈希地址。
关键:如何选取合适的p?
技巧:若设计的哈希表长为m,则一般取p≤m且为质数 (也可以是不包含小于20质因子的合数)。
3、 乘余取整法;
Hash(key) = [B*( A*key mod 1 ) ]下取整 (A、B均为常数,且0<A<1,B为整数)
**特点:**以关键码key乘以A,取其小数部分,然后再放大B倍并取整,作为哈希地址。
**例:**欲以学号最后两位作为地址,则哈希函数应为: H(k)=100*(0.01*k % 1 ) 其实也可以用法2实现: H(k)=k % 100
4、数字分析法
**特点:**某关键字的某几位组合成哈希地址。所选的位应当是:各种符号在该位上出现的频率大致相同。
例:有一组(例如80个)关键码,其样式如下:

5、平方取中法
**特点:**对关键码平方后,按哈希表大小,取中间的若干位作为哈希地址。
理由:因为中间几位与数据的每一位都相关。
例:2589的平方值为6702921,可以取中间的029为地址。
6、折叠法
**特点:**将关键码自左到右分成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按哈希表表长,取后几位作为哈希地址。
适用于:每一位上各符号出现概率大致相同的情况。
法1:移位法 ── 将各部分的最后一位对齐相加。
法2:间界叠加法──从一端向另一端沿分割界来回折叠后,最后一位对齐相加。
**例:**元素42751896, 用法1: 427+518+96=1041 用法2: 427 518 96—> 724+518+69 =1311
哈希表定址与解决冲突
Hash表解决冲突的方法主要有以下几种:
开放定址法(开地址法)、 链地址法(拉链法)、 再哈希法(双哈希函数法)、 建立一个公共溢出区,而最常用的就是开发定址法和链地址法。
1、开放定址法
如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。线性探测带来的最大问题就是冲突的堆积,你把别人预定的坑占了,别人也就要像你一样去找坑。改进的办法有二次方探测法和随机数探测法。开放地址法包括线性探测、二次探测以及双重散列等方法。
**设计思路:**有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入。
**含义:**一旦冲突,就找附近(下一个)空地址存入。
具体实现:
- 线性探测法
Hi=(Hash(key)+di) mod m ( 1≤i < m ) 其中: Hash(key)为哈希函数 m为哈希表长度 di 为增量序列 1,2,…m-1,且di=i
例:
关键码集为 {47,7,29,11,16,92,22,8,3},
设:哈希表表长为m=11; 哈希函数为Hash(key)=key mod 11; 拟用线性探测法处理冲突。建哈希表如下:
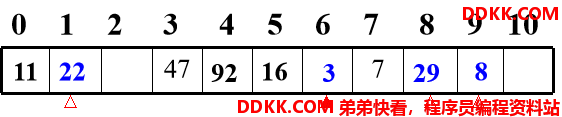
解释:
①47、7(以及11、16、92)均是由哈希函数得到的没有冲突的哈希地址;
②Hash(29)=7,哈希地址有冲突,需寻找下一个空的哈希地址:由H1=(Hash(29)+1) mod 11=8,哈希地址8为空,因此将29存入。
③另外,22、8、3同样在哈希地址上有冲突,也是由H1找到空的哈希地址的。其中3 还连续移动了两次(二次聚集)
int FindHash(SeqList* pL, KeyType K)
{
int c=0; int p=Hash(K); /*求得哈希地址*/
while(pL->data[p].key!=NULL_KEY && K!=pL->data[p].key && ++c<MAXNUM) p=Hash(K+c);
if(K==pL->data[p].key) {
printf("\n成功找到 %d", K);
return p; /*查找成功,p返回待查数据元素下标*/
}
else if(pL->data[p].key==NULL_KEY) {
printf("\n无法找到 %d , 在位置 %d 插入。", K,p);
pL->data[p].key = K; pL->n++;
return p;
} else {
printf("\n无法找到 %d , 表已满。", K);
return -1;
}
}
讨论:
线性探测法的优点:只要哈希表未被填满,保证能找到一个空地址单元存放有冲突的元素;
线性探测法的缺点:可能使第i个哈希地址的同义词存入第i+1个哈希地址,这样本应存入第i+1个哈希地址的元素变成了第i+2个哈希地址的同义词,……,因此,可能出现很多元素在相邻的哈希地址上“堆积”起来,大大降低了查找效率。
解决方案:可采用二次探测法或伪随机探测法,以改善“堆积”问题。
2) 二次探测法
仍举上例,改用二次探测法处理冲突,建表如下:
Hi=(Hash(key)±di) mod m 其中:Hash(key)为哈希函数 m为哈希表长度,m要求是某个4k+3的质数; di为增量序列 12,-12,22,-22,…,q2
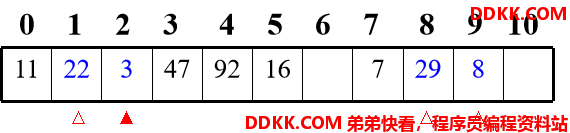
注:只有3这个关键码的冲突处理与上例不同, Hash(3)=3,哈希地址上冲突,由 H1=(Hash(3)+12) mod 11=4,仍然冲突; H2=(Hash(3)-12) mod 11=2,找到空的哈希地址,存入。
2**、链地址法(拉链法)**
基本思想:将具有相同哈希地址的记录链成一个单链表,m个哈希地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构。
**注:**有冲突的元素可以插在表尾,也可以插在表头
例:设{ 47, 7, 29, 11, 16, 92, 22, 8, 3, 50, 37, 89 }的哈希函数为: Hash(key)=key mod 11, 用拉链法处理冲突,则建表如下图所示。
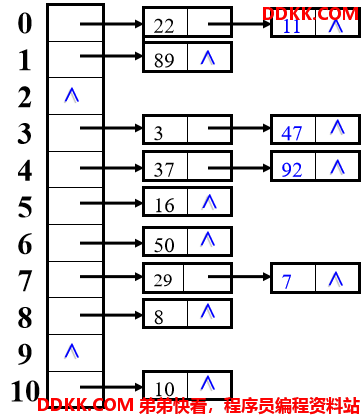
3、再哈希法(双哈希函数法)
Hi=RHi(key) i=1, 2, …,k
RHi均是不同的哈希函数,当产生冲突时就计算另一个哈希函数,直到冲突不再发生。
**优点:**不易产生聚集;
**缺点:**增加了计算时间。
4. 建立一个公共溢出区
思路:除设立哈希基本表外,另设立一个溢出向量表。 所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的地址是什么,一旦发生冲突,都填入溢出表。
这个方法其实就更加好理解,你不是冲突吗? 好吧,凡是冲突的都跟我走,我给你们这些冲突找个地儿待着。这就如同孤儿院收留所有无家可归的孩子 样,我们为所有冲突的关键字建立了一个公共的溢出区来存放.
哈希表的查找及分析
哈希查找过程
哈希表的主要目的是用于快速查找,且插入和删除操作都要用到查找。由于散列表的特殊组织形式,其查找有特殊的方法。 设散列为HT[0…m-1],散列函数为H(key),解决冲突的方法为R(x, i) ,则在散列表上查找定值为K的记录的过程如图所示。
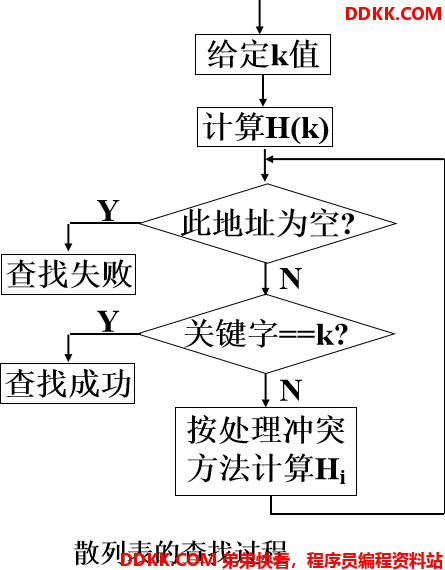
查找效率分析
明确:散列函数没有“万能”通式,要根据元素集合的特性而分别构造。
讨论:哈希查找的速度是否为真正的O(1)?
不是。由于冲突的产生,使得哈希表的查找过程仍然要进行比较,仍然要以平均查找长度ASL来衡量。 一般地,ASL依赖于哈希表的装填因子,它标志着哈希表的装满程度。

讨论:
1)散列存储的查找效率到底是多少?
答:ASL与装填因子α有关!既不是严格的O(1),也不是O(n)

2)“冲突”是不是特别讨厌?
答:不一定!正因为有冲突,使得文件加密后无法破译(不可逆,是单向散列函数,可用于数字签名)。 利用了哈希表性质:源文件稍稍改动,会导致哈希表变动很大。
练习:
给定关键字序列11,78,10,1,3,2,4,21,试分别用顺序查找、二分查找、二叉排序树查找、散列查找(用线性探查法和拉链法)来实现查找,试画出它们的对应存储形式(顺序查找的顺序表,二分查找的判定树,二叉排序树查找的二叉排序树及两种散列查找的散列表),并求出每一种查找的成功平均查找长度。散列函数H(k)=k%11。
1) 顺序查找的成功平均查找长度为: ASL=(1+2+3+4+5+6+7+8)/8=4.5;
2) 二分查找的判定树(中序序列为从小到大排列的有序序列)如图所示
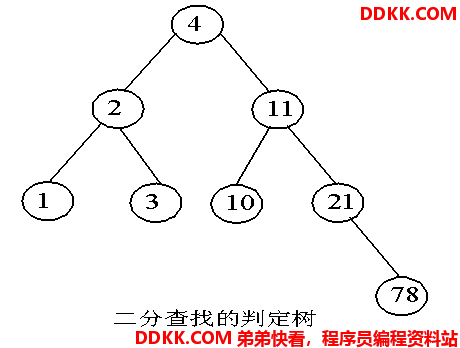
从上图可以得到二分查找的成功平均查找长度为: ASL=(1+2*2+3*4+4)/8=2.625;
3) 二叉排序树(关键字顺序已确定,该二叉排序树应唯一)如图 所示
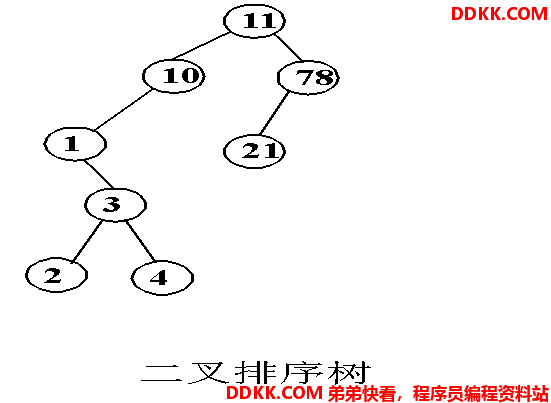
从图可以得到二叉排序树查找的成功平均查找长度为: ASL=(1+2*2+3*2+4+5*2)=3.125;
4) 线性探查法解决冲突的散列表如图所示
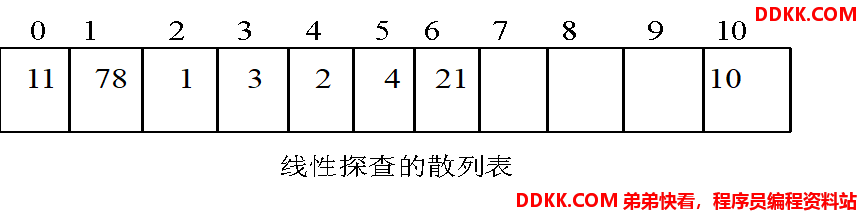
从图可以得到线性探查法的成功平均查找长度为: ASL=(1+1+2+1+3+2+1+8)/8=2.375;
5)拉链法解决冲突的散列表 如图所示
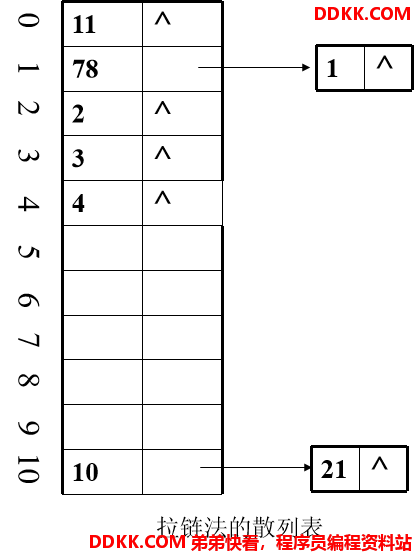
从图可以得到拉链法的成功平均查找长度为: ASL=(1*6+2*2)/8=1.25。