1、为什么要用Volumes卷?
容器中的文件在磁盘上是临时存放的,容器一旦被删除,容器中的文件也就被删除了,这给容器中运行的特殊应用程序带来一些问题。具体来说,首先,当容器崩溃时,kubelet 将重新启动容器,容器中的文件将会丢失,因为容器会以干净的状态重建;其次,当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。
按照以前的思路是无法解决的,现在K8s抽象出 Volume 的概念来解决这两个问题。
Kubernetes 卷具有明确的生命周期,与包裹它的 Pod 相同。 因此,卷比 Pod 中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留。 当然,当一个 Pod 不再存在时,卷也将不再存在。也许更重要的是,Kubernetes 可以支持许多类型的卷,Pod 也能同时使用任意数量的卷。
注意卷不能挂载到其他卷,也不能与其他卷有硬链接。 Pod 中的每个容器必须独立地指定每个卷的挂载位置。
Kubernetes 支持下列类型的卷:
awsElasticBlockStore 、azureDisk、azureFile、cephfs、cinder、configMap、csi
downwardAPI、emptyDir、fc (fibre channel)、flexVolume、flocker
gcePersistentDisk、gitRepo (deprecated)、glusterfs、hostPath、iscsi、local、
nfs、persistentVolumeClaim、projected、portworxVolume、quobyte、rbd
scaleIO、secret、storageos、vsphereVolume
2、emptyDir卷
当Pod 指定到某个节点上时,首先创建的是一个 emptyDir 卷,并且只要 Pod 在该节点上运行,卷就一直存在。 就像它的名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
常用的emptyDir 的使用场景:
(1)缓存空间,例如基于磁盘的归并排序。
(2)为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
(3)在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
默认情况下, emptyDir 卷存储在支持该节点所使用的介质上;这里的介质可以是磁盘或 SSD 或网络存储,这取决于你的环境。 但是,您可以将 emptyDir.medium 字段设置为 “Memory”,以告诉 Kubernetes 为您安装 tmpfs(基于内存的文件系统)。 虽然 tmpfs 速度非常快,但是要注意它与磁盘不同。 tmpfs 在节点重启时会被清除,并且您所写入的所有文件都会计入容器的内存消耗,受容器内存限制约束。
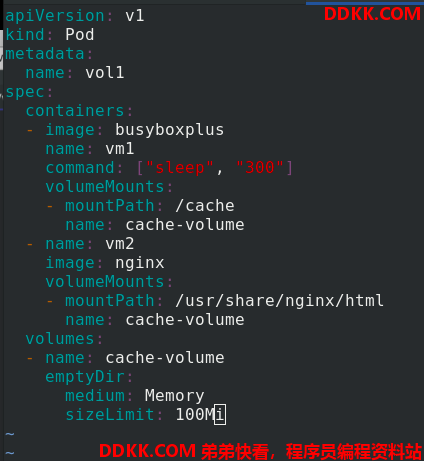
创建目录volumes,

编辑vol1.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: vol1
spec:
containers: %一个pod中创建两个容器共享volumes
- image: busyboxplus
name: vm1
command: ["sleep", "300"]
volumeMounts:
- mountPath: /cache %vm1中的卷挂载到容器内的/cache
name: cache-volume
- name: vm2
image: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html %vm2中的卷挂载到容器内的/usr/share/nginx/html
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
medium: Memory %使用内存介质
sizeLimit: 100Mi %可以使用100M内存
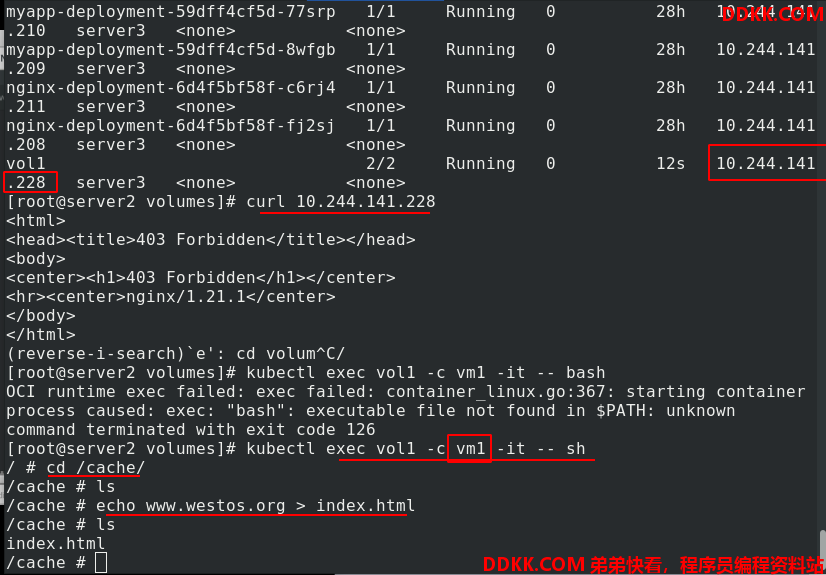
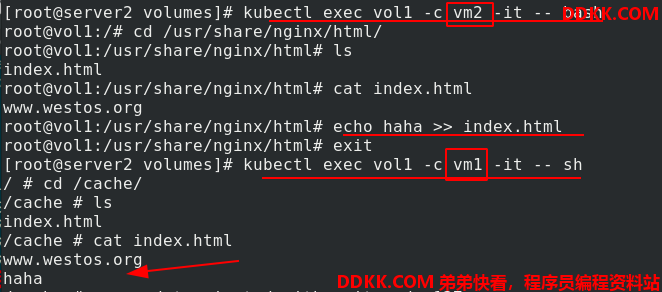
kubectl apply -f vol1.yaml创建pod,kubectl get pod -o wide查看pod,vol1的ip是10.244.141.228,访问,403错误是因为没有发布内容。进入vol1的vm1容器,在/cache中写入发布内容
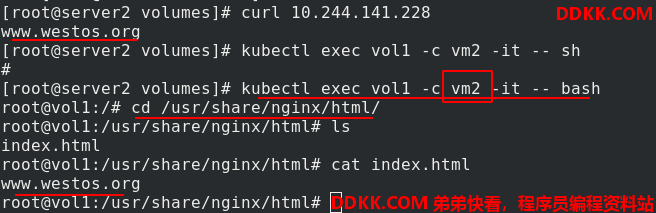
再次访问测试,有内容了。进入vol1的vm2容器,在/usr/share/nginx/html中可以看到发布内容和vm1中的一样,说明vm1和vm2共用卷资源
进入vol1的vm2容器,在原有内容的基础上再追加发布内容,回到vol1的vm1容器,看到了追加的内容,进一步证明了同一个pod内的两个容器vm1和vm2共用卷资源
如果写入了200M的文件,超过了限定的100M,pod会坏掉
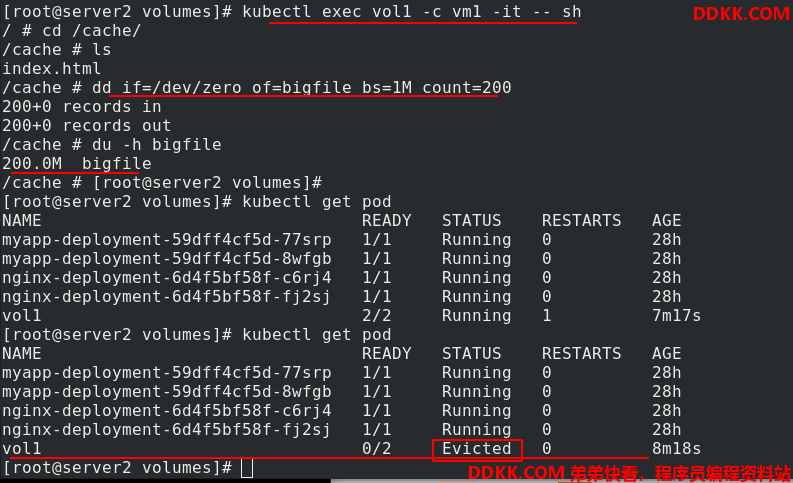
可以看到文件超过限制后,则1-2分钟后会被kubelet evict掉。之所以不是“立即”被evict,是因为kubelet是定期进行检查的,这里会有一个时间差。这就暴露了emptydir的一些缺点:
(1)不能及时禁止用户使用内存。虽然过1-2分钟kubelet会将Pod挤出,但是这个时间内,有可能对node造成损坏;
(2)影响kubernetes调度,因为empty dir并不涉及node的resources,这样会造成Pod“偷偷”使用了node的内存,但是调度器并不知晓;
(3)用户不能及时感知到内存不可用
3、hostPath 卷
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中。 虽然这不是大多数 Pod 需要的,但是它为一些应用程序提供了强大的逃生舱。
hostPath 的主哟用法有:
(1)运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
(2)在容器中运行 cAdvisor 时,以 hostPath 方式挂载 /sys。
(3)允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在。
(1)主机内目录挂载到pod中
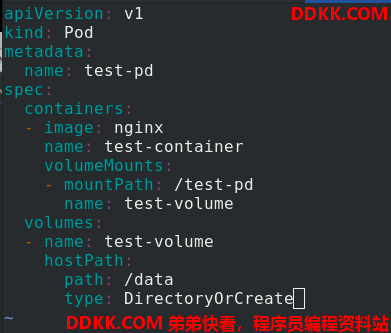
创建host.yaml 文件
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /test-pd %把卷挂载到容器内的/test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data %卷的路径在/data
type: DirectoryOrCreate %如果在指定路径上不存在,那么根据需要创建空目录,权限为0755,具有与kubelet相同的组和所有权
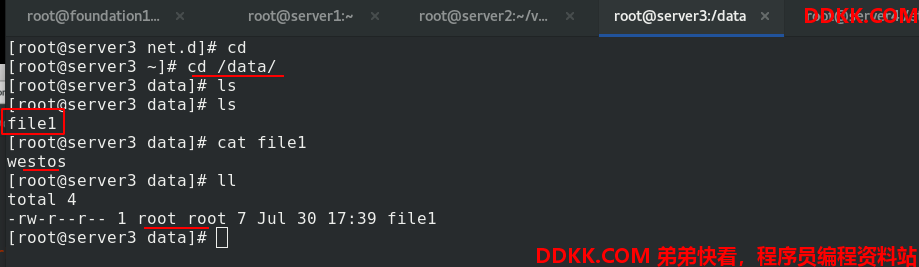
创建test-pd,查看它被调度到了server3上,进入test-pd,在/test-pd中写入文件
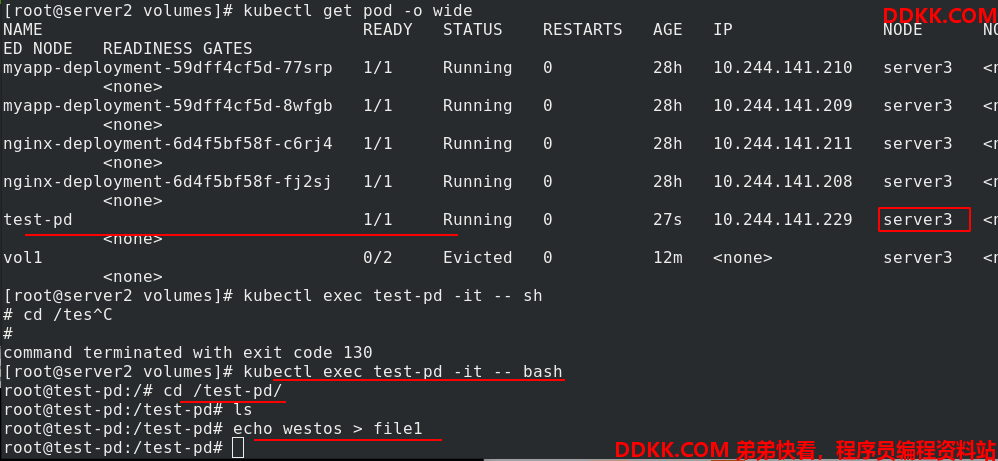
去真正的节点,查看在/data中确实有file1,拥有者和拥有组都是root
除了上面使用的DirectoryOrCreate之外,用户可以选择性地为 hostPath 卷指定更多 type

当使用这种类型的卷时要小心,因为:
(1)具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
(2)当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源。
(3)基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷。
(2)主机内nfs挂载到pod中
一般来说文件存储是独立于k8s集群的,所以nfs和仓库一样都放在了server1。
首先安装nfs
vim /etc/exports %编辑内容如图
systemctl start nfs %开启nfs
showmount -e %测试是否正常
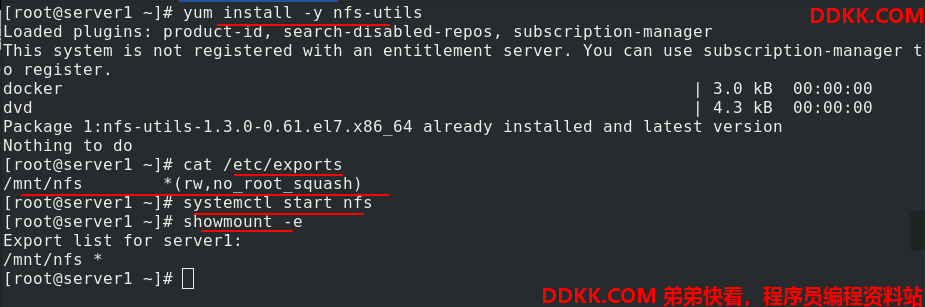
集群内所有节点也都需要安装nfs文件系统,并开启nfs。showmount -e 172.25.11.1可以测试是都正常

在server2编辑nfs.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html %把卷挂载到test-pd容器内的/usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
nfs:
server: 172.25.11.1 %卷的路径是172.25.11.1/mnt/nfs
path: /mnt/nfs
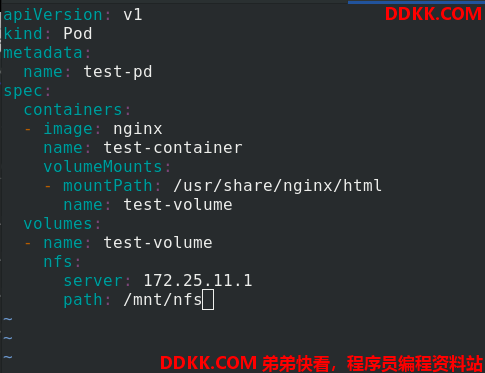
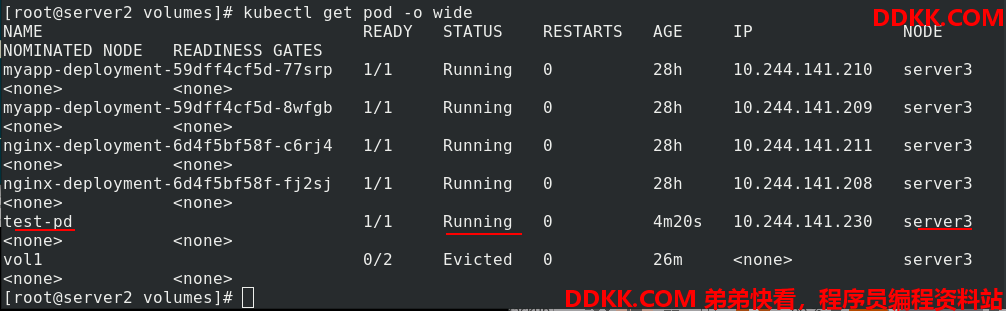
kubectl apply -f nfs.yaml 创建pod,查看节点,pod没有成功创建,是因为该pod调度到了server3,但是server3没有安装nfs或者开启nfs。
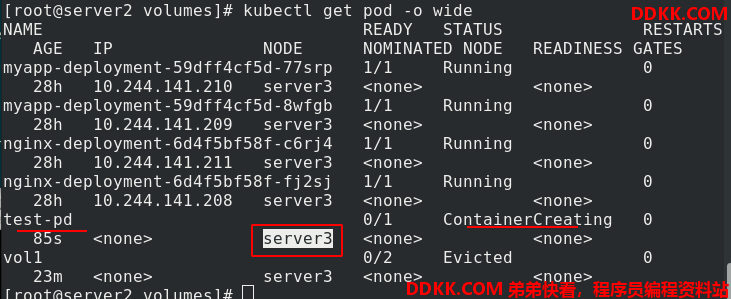
在server3安装好nfs
再次查看,正常运行
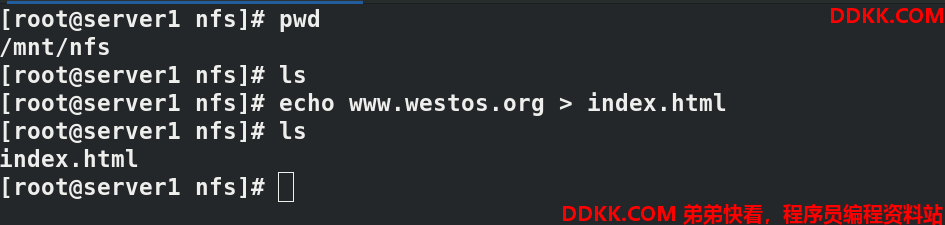
现在准备测试是否同步,在server1中,创建发布内容
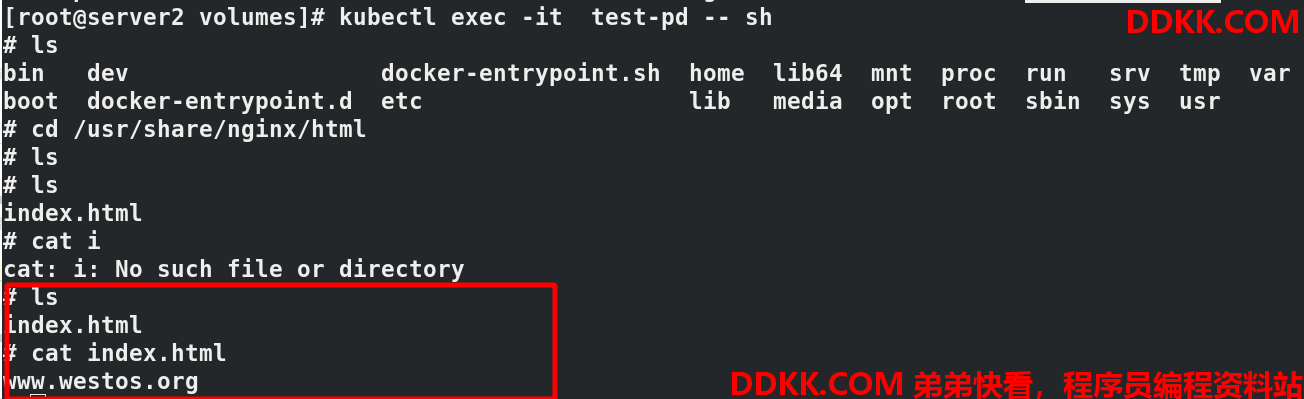
kubectl exec test-pd -it bash进入pod,查看存在发布内容,nfs+集群成功
4、PersistentVolume持久卷
(1)什么是持久卷?
PersistentVolume(持久卷,简称PV)是集群内,由管理员提供的网络存储的一部分。就像集群中的节点一样,PV也是集群中的一种资源。它也像Volume一样,是一种volume插件,但是它的生命周期却是和使用它的Pod相互独立的。PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节。
PersistentVolumeClaim(持久卷声明,简称PVC)是用户的一种存储请求。它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源。Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)。
有两种PV提供的方式:静态和动态。
(1)静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,这些存储对于集群用户是可用的。它们存在于Kubernetes API中,并可用于存储使用。
(2)动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass。
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态。
- 使用时:
集群检查PVC,查找绑定的PV,并映射PV给Pod。对于支持多种访问模式的PV,用户可以指定想用的模式。一旦用户拥有了一个PVC,并且PVC被绑定,那么只要用户还需要,PV就一直属于这个用户。用户调度Pod,通过在Pod的volume块中包含PVC来访问PV。 - 释放时:
当用户使用PV完毕后,他们可以通过API来删除PVC对象。当PVC被删除后,对应的PV就被认为是已经是“released”了,但还不能再给另外一个PVC使用。前一个PVC的属于还存在于该PV中,必须根据策略来处理掉。 - 回收时:
PV的回收策略告诉集群,在PV被释放之后集群应该如何处理该PV。当前,PV可以被Retained(保留)、 Recycled(再利用)或者Deleted(删除)。保留允许手动地再次声明资源。对于支持删除操作的PV卷,删除操作会从Kubernetes中移除PV对象,还有对应的外部存储(如AWS EBS,GCE PD,Azure Disk,或者Cinder volume)。动态供给的卷总是会被删除。
(2)静态PV
在nfs系统中写入发布文件
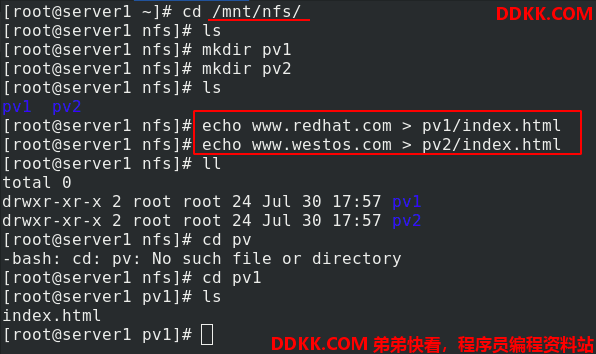
编辑pv.yaml文件
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce %策略为一次读写
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /mnt/nfs/pv1 %nfs路径是172.25.11.1/mnt/nfs/pv1
server: 172.25.11.1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany %策略为多次读写
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /mnt/nfs/pv2 %nfs路径是172.25.11.1/mnt/nfs/pv2
server: 172.25.11.1
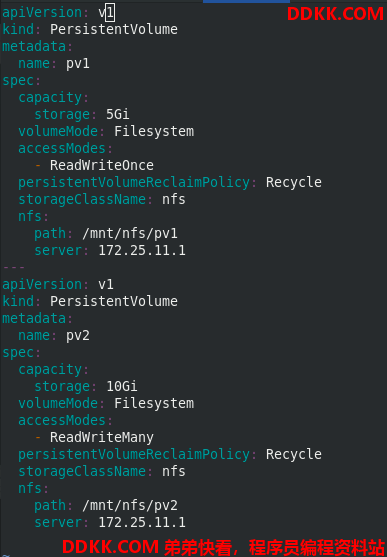
创建两个持久卷pv1和pv2。查看此时状态为Available模式
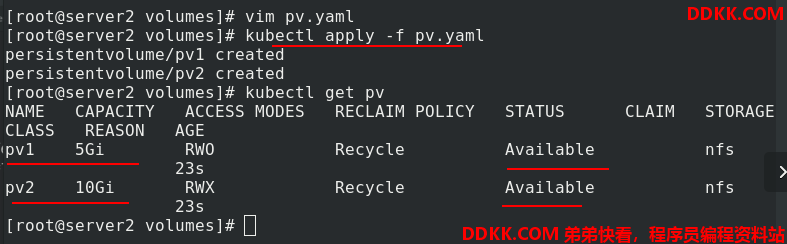
编辑pvc.yaml文件
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs
accessModes:
- ReadWriteOnce
resources:
requests: %最低需求为1G
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi %%最低需求为10G
创建两个pvc,pvc1和pvc2

创建pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd-1
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv1
volumes:
- name: pv1
persistentVolumeClaim:
claimName: pvc1 %test-pd-1使用pvc1
---
apiVersion: v1
kind: Pod
metadata:
name: test-pd-2
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv2
volumes:
- name: pv2
persistentVolumeClaim:
claimName: pvc2 %test-pd-2使用pvc2
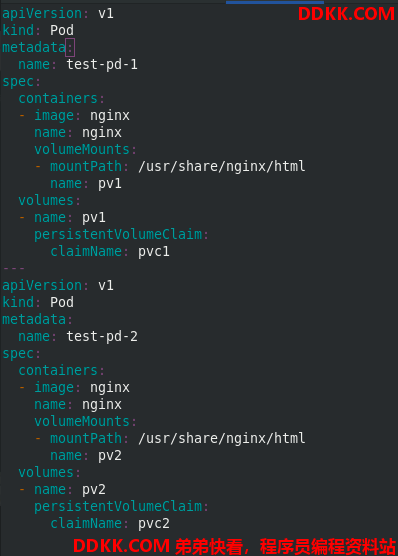
创建两个pod,test-pd-1和test-pd-2,查看状态是running
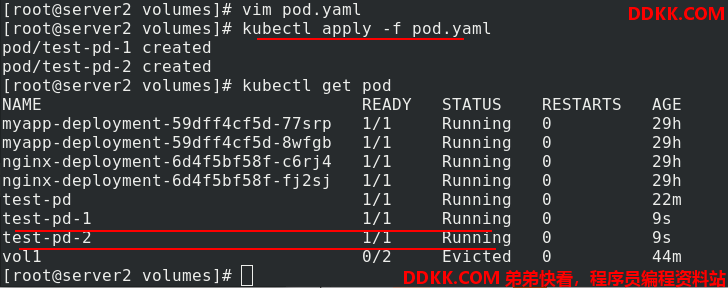
查看两个pod的ip,访问测试,不同的pod可以获得不同的发布内容
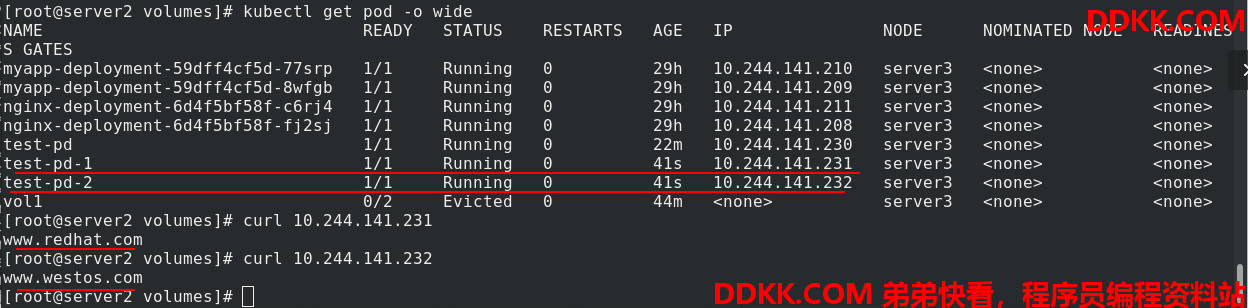
删除pod后,可以看到pvc和pv的绑定关系还在
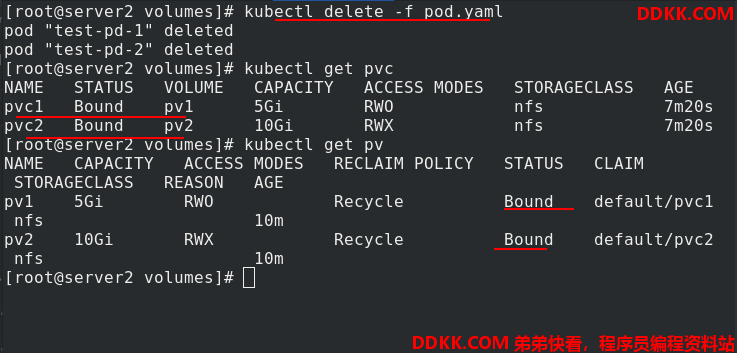
删除pvc后,仍然可以看到pvc和pv的绑定关系,不能给其他人使用。这属于静态pv的缺点之一。

删除时,要注意删除的顺序,先删除pod,再删除pvc,最后删除pv
静态卷需要提前创建好,但是实际生产环境中很可能管理员无法提前创建,所以下面使用动态卷,它可以自动创建
(3)动态PV
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到。
StorageClass的属性有:
(1)Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
(2)Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
更多属性查看:https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
NFSClient Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
PV以${namespace}-${pvcName}-${pvName}的命名格式提供(在NFS服务器上)
PV回收的时候以 archieved-${namespace}-${pvcName}-${pvName} 的命名格式(在NFS服务器上)
nfs-client-provisioner源码地址:https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client
首先从网上拉取镜像,导入镜像,并上传到仓库,方便后面使用。
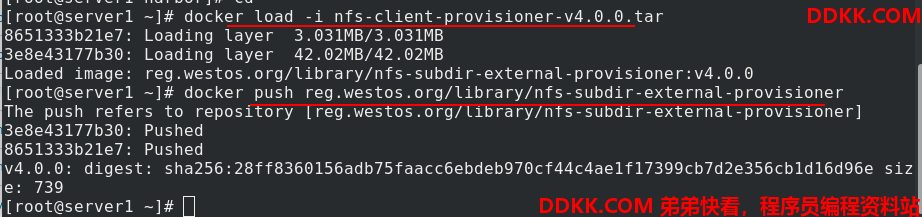
创建目录,创建ns
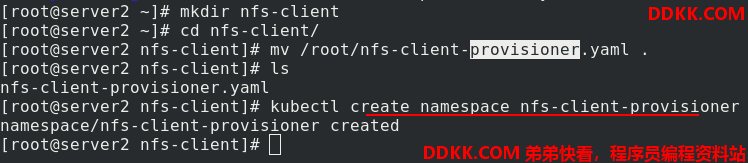
编辑nfs-client-provisioner.yaml文件(从官网下载即可)
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: westos.org/nfs
- name: NFS_SERVER
value: 172.25.11.1
- name: NFS_PATH
value: /mnt/nfs
volumes:
- name: nfs-client-root
nfs:
server: 172.25.11.1
path: /mnt/nfs
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: westos.org/nfs
parameters:
archiveOnDelete: "true" %true表示删除pvc后,目录打包
%false表示删除pvc后,目录直接删除
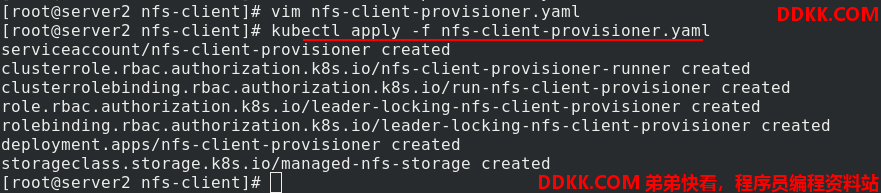
应用nfs-client-provisioner.yaml文件
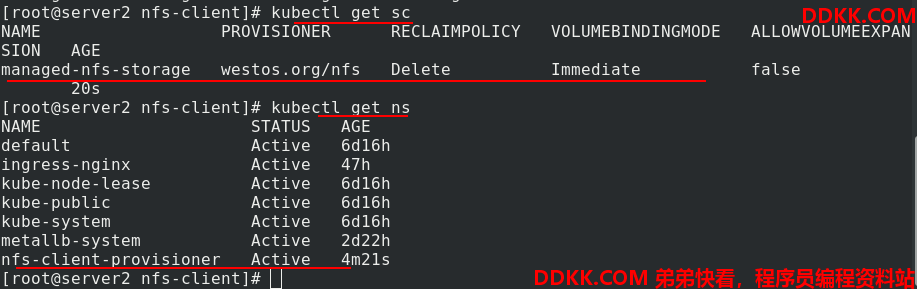
查看创建的sc和ns
编辑test-pvc.yaml文件
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: managed-nfs-storage %声明managed-nfs-storage这个sc
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
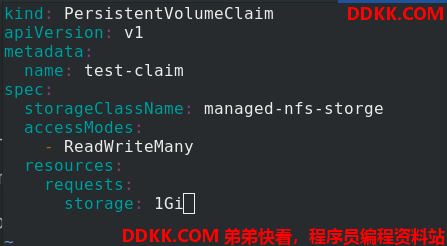
创建pvc,查看pv和pvc。一旦创建了pvc,就自动创建了pv

在server1中可以看到自动生成了子目录
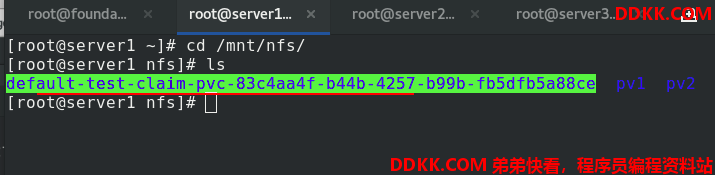
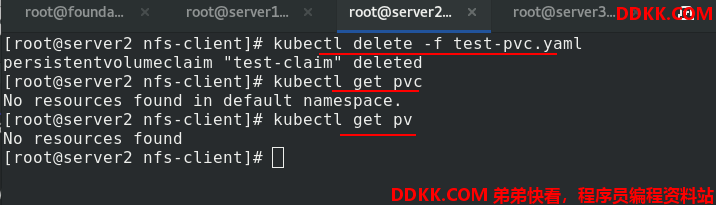
没有指定回收策略时,默认为Delete。删除pvc后,pv也就自动回收了。
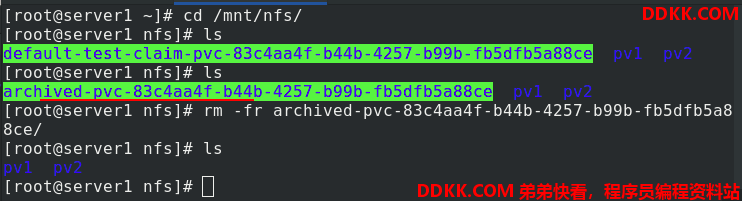
回收后,server1端,原来的子目录改名字,backup打包
编辑pod.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: test-pd-1
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv1
volumes:
- name: pv1
persistentVolumeClaim:
claimName: test-claim
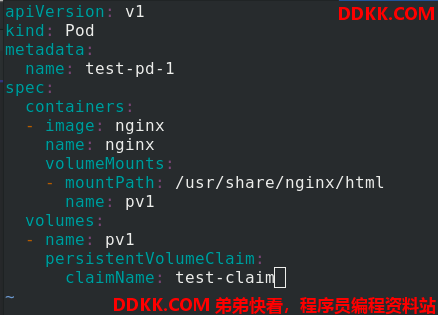
应用test-pvc.yaml文件和pod.yaml文件
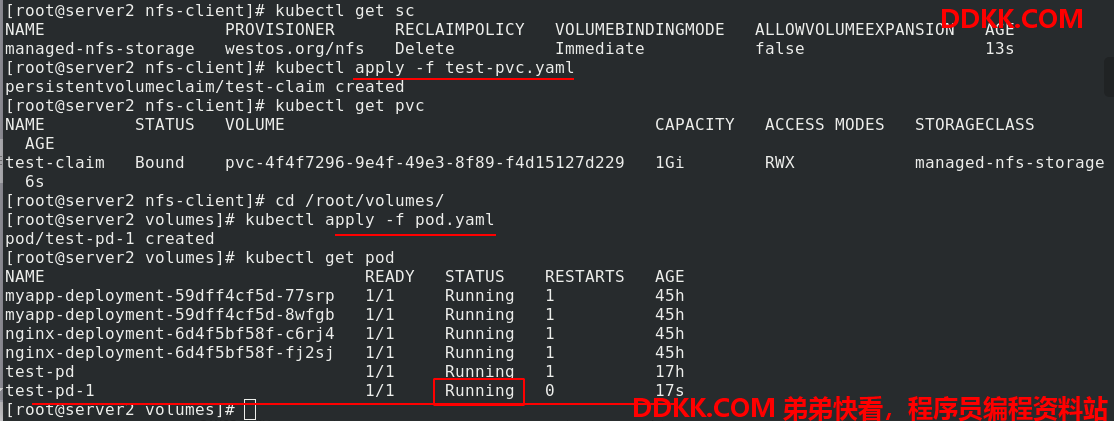
查看test-pd-1的ip,访问出现403报错,原因是没有默认发布文件
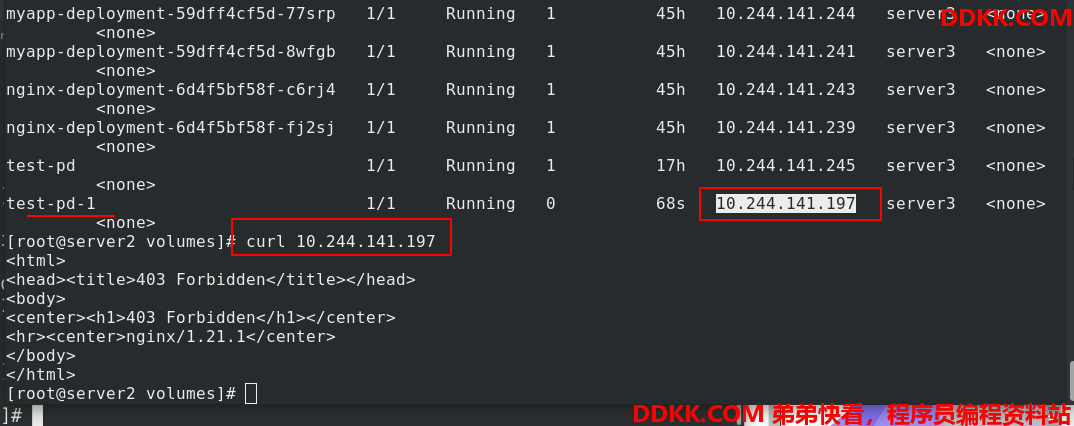
写入默认发布文件
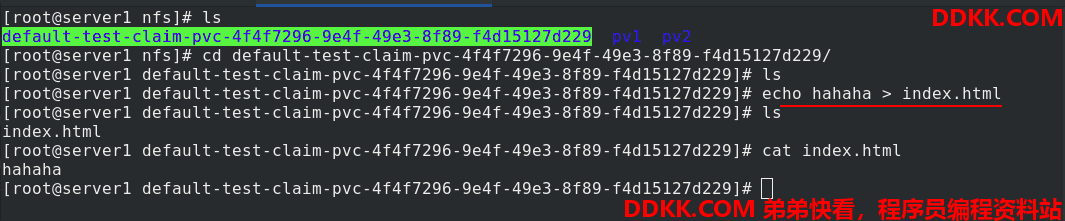
访问成功

清空实验环境
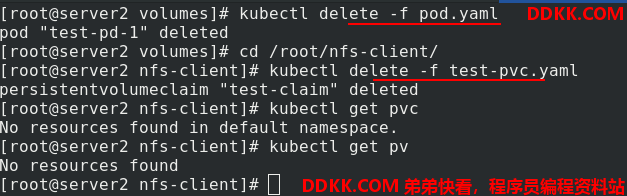
nfs没有动态卷了
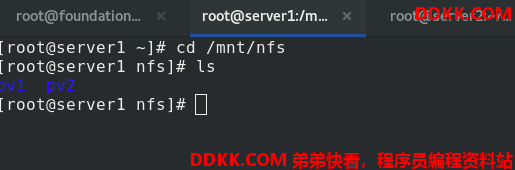
如果把test-pvc.yaml文件中的sc的指定给注释掉,
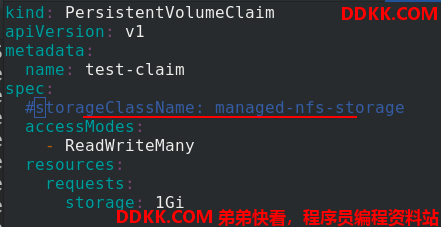
拉起pvc后,会显示pending状态,因为没有告诉它sc
除了指定sc,还有另外一种方法,把managed-nfs-storage设为默认sc。现在删除之前的pvc,重新创建pvc,就正常了
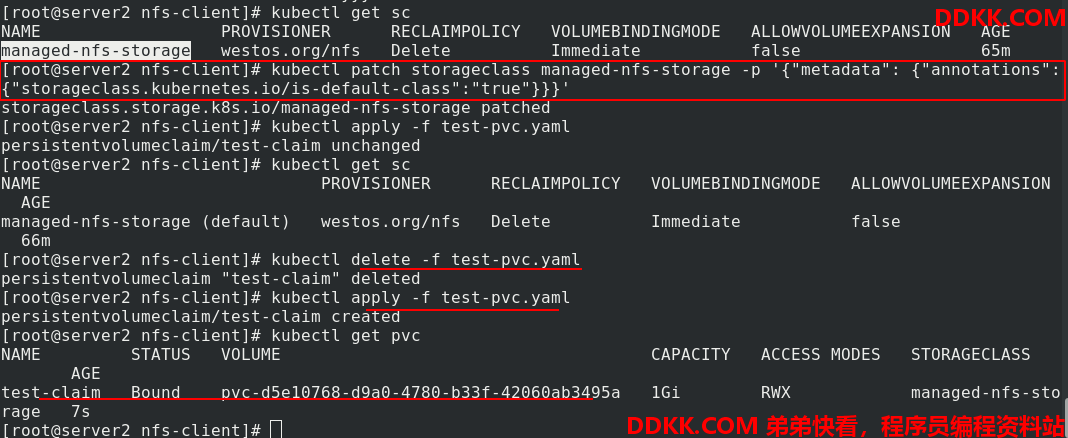
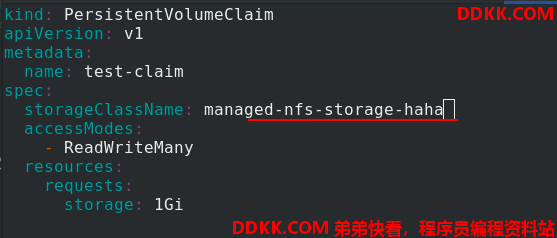
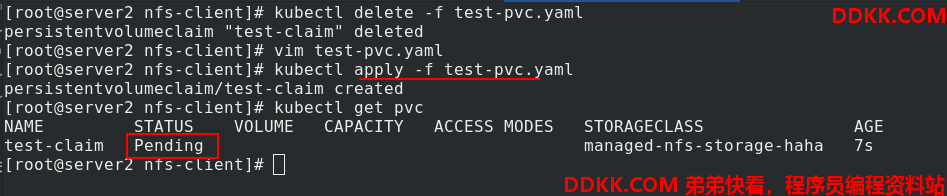
但是如果test-pvc.yaml文件中的sc的指定是不存在的,比如这里的managed-nfs-storage-haha
应用后,还是有问题的,状态为pending
5、StatefulSet控制器
StatefulSet将应用状态抽象成了两个条件:
(1)拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一致(稳定的状态)
(2)存储状态:应用的多个实例分别绑定了不同存储数据(动态数据卷)
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号),从0开始。创建时,是一个创建成功再创建下一个。回收时一个一个删除,不能直接用delete(会同时删除,乱了,没有序了),删除的方式是把文件中的副本数量改为0,再次应用,就会删除,后创建的先删除,一个接一个删除
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,即Pod对应的DNS记录。副本数量变为0,删除了容器,但是数据卷还是在的。等我们再次创建三个副本pod,web-0,web-1,web-2还是对应以前存在的数据卷,不会错乱。
创建目录
编辑nginx-svc.yaml 文件
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
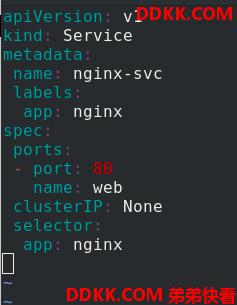
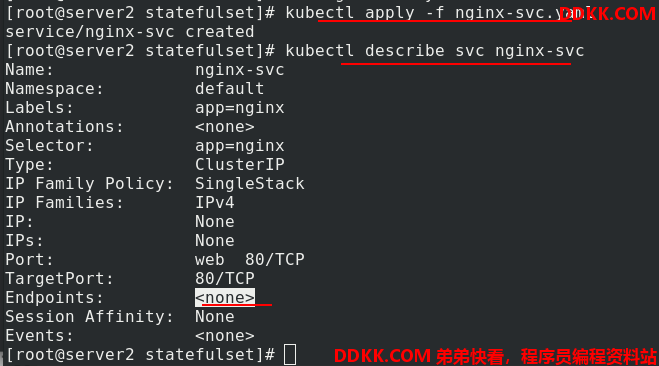
应用nginx-svc.yaml 文件,查看详细信息,没有后端,因为我们还没开
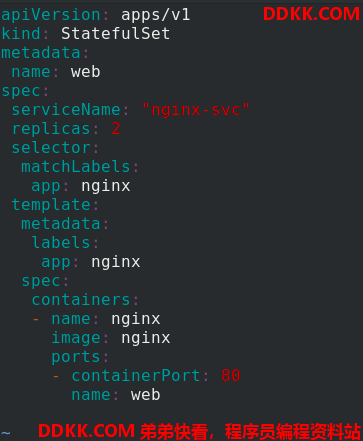
编辑statefulset.yaml 文件,使用StatefulSet控制器产生pod
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-svc"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
应用statefulset.yaml 文件产生pod
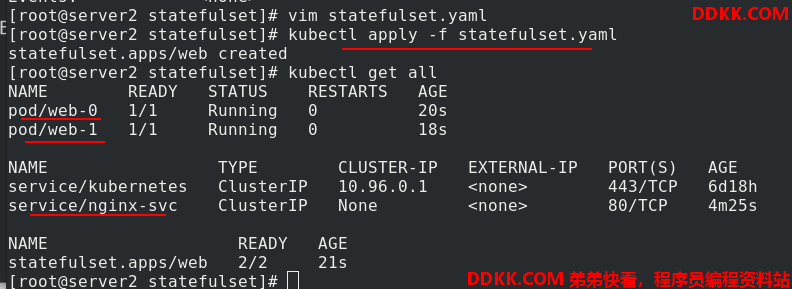
现在再次查看服务,就可以看到后端了
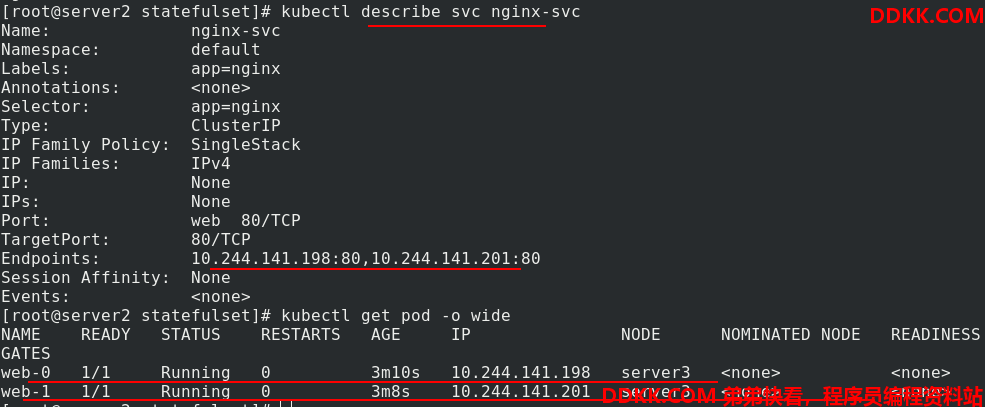
扩容时,修改statefulset.yaml 文件,副本数量增加为6
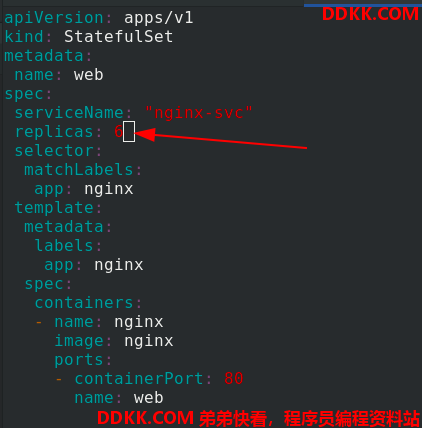
应用statefulset.yaml 文件,可以看到副本是一个一个生成的,有序的
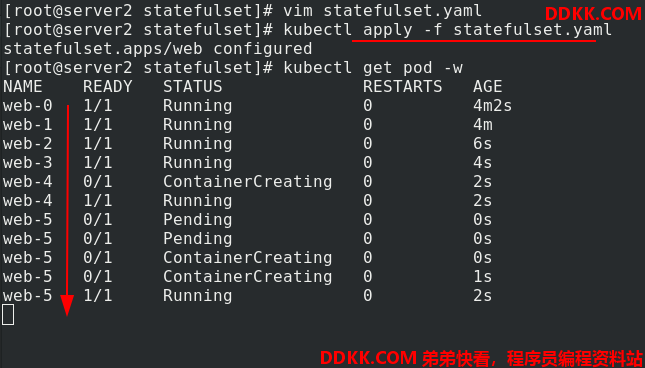
删除时,修改statefulset.yaml 文件,副本数量减少到0
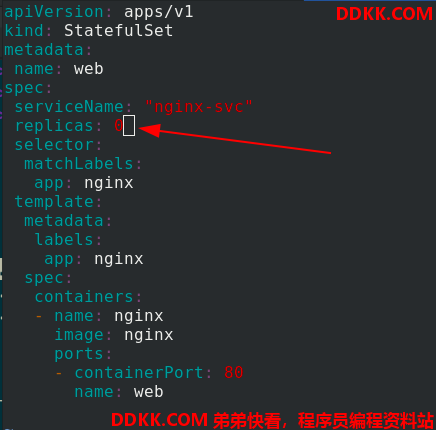
应用statefulset.yaml 文件,可以看到是一个一个删除的,并且是先删除新建的pod,后删除老的pod
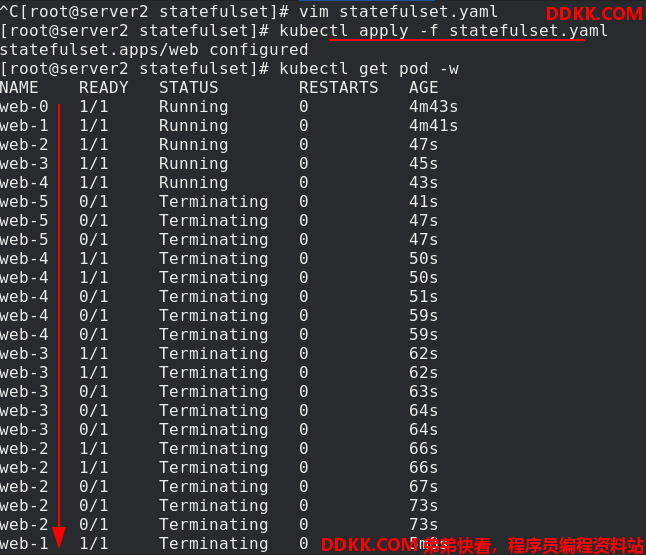
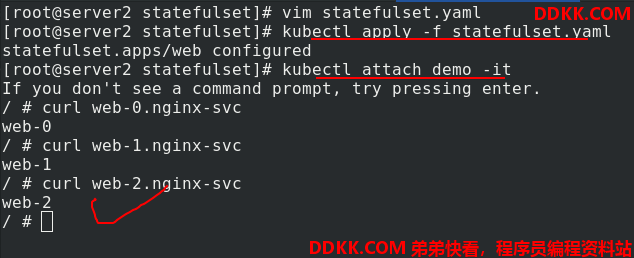
测试采用三个副本数,恢复副本数到3
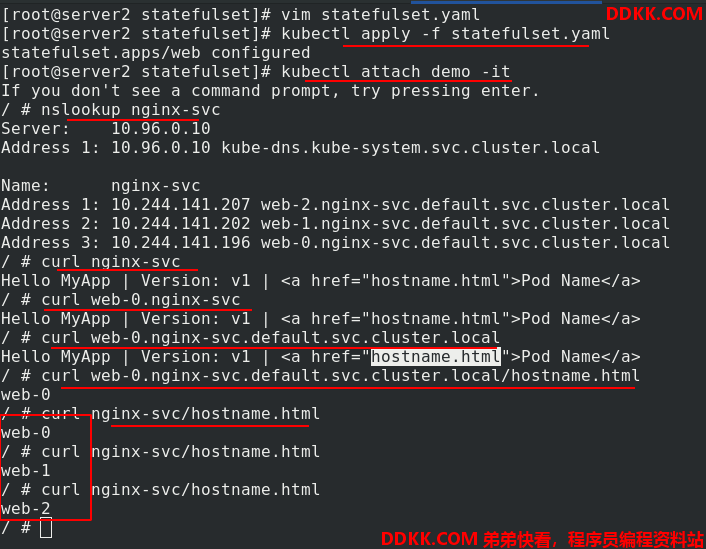
连接一个demo,进入查看可以解析,并且是负载均衡的。
PV和PVC的设计,使得StatefulSet对存储状态的管理成为了可能
编辑statefulset.yaml 文件
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-svc"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: nfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
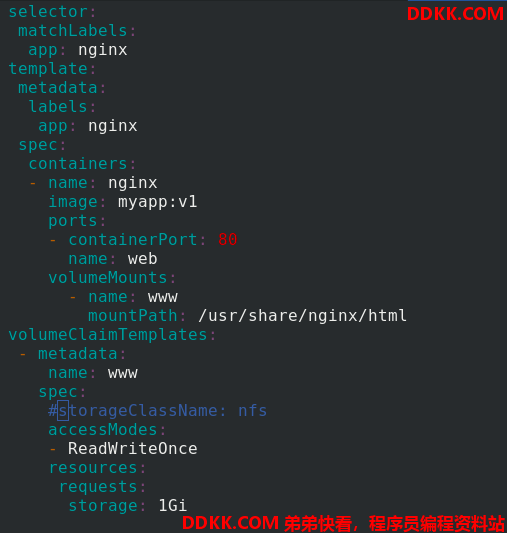
应用statefulset.yaml 文件,查看状态正常
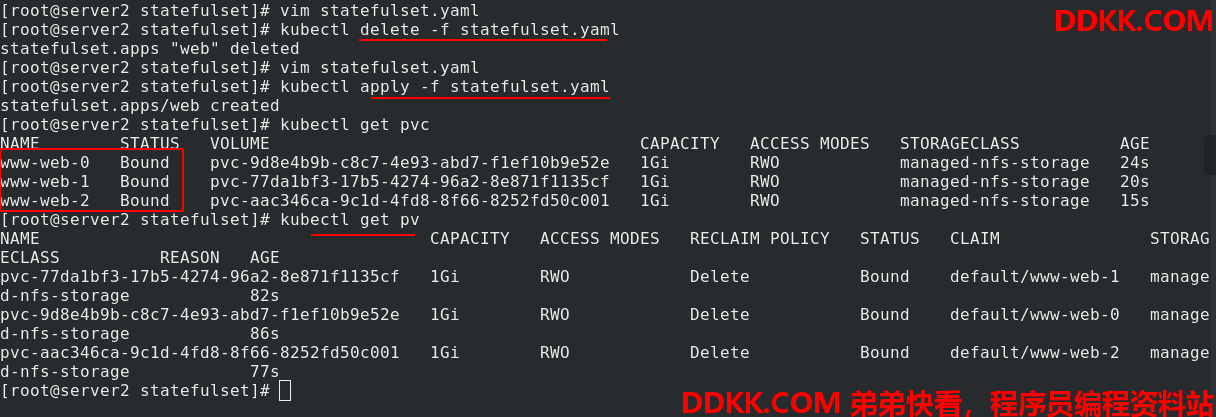
为了测试效果,nfs端,给每个卷写入不同的发布内容
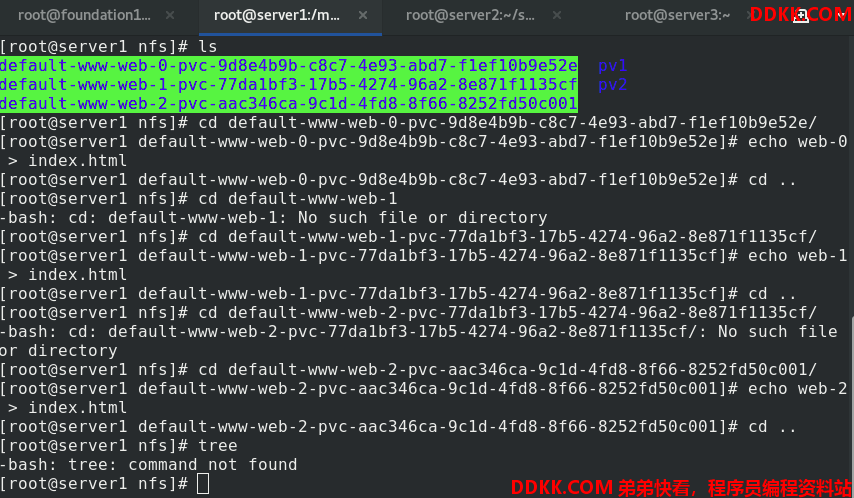
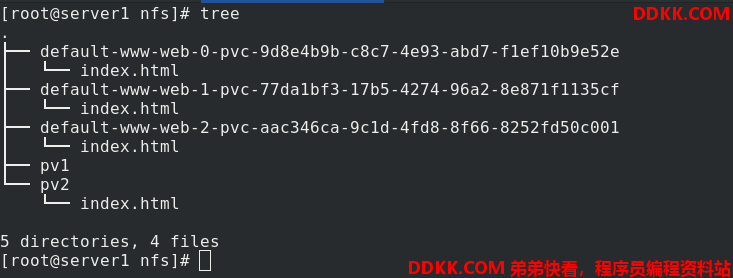
结构如下
server2进入demo,curl+服务名字,测试是负载均衡的
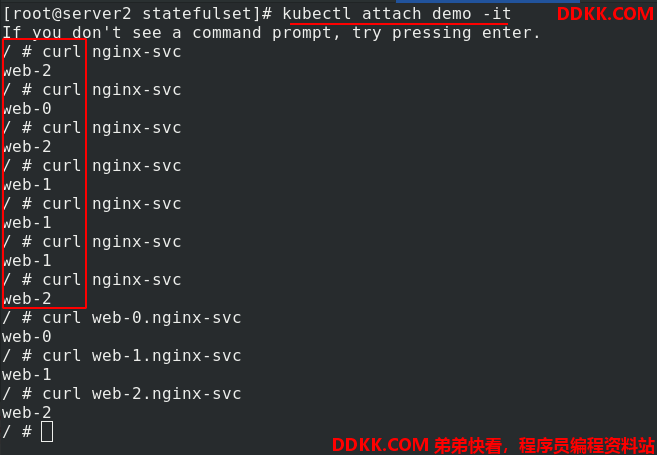
下面测试副本删除后,重新建立,原数据是否还在?
先把statefulset.yaml 文件中的副本数量变为0,
应用后,再把statefulset.yaml 文件中的副本数量变为3,
再次创建pod,进入demo测试,确实数据还在