前言
在了解了Seata 的使用和基本原理后,尝试进行了一把简单的压测,看看在高并发情况下是否有其他问题。
测试环境
个人电脑:
- Intel® Core™ i7-8750H CPU @ 2.20GHz 2.21 GHz
- 内存:16.0 GB
- 系统:Windows 10 专业版
组件:
- JDK 1.8
- nacos 2.0.3
- Seata 1.4.2(Nacos 注册中心,本地文件配置中心,记录数据库存储会话)
- Spring Boot 2.2.13
- Mariadb 10.1
- 账户、订单、库存单体服务部署
提交测试
全局事务的路径为,用户服务扣除余额=》订单服务添加一个订单=》库存服务扣除库存。
并发总数设置为1W次,并发请求数每次增加10。
并发 10
在该并发量下,成功下单1W,也没有什么异常,检查数据,也没有数据不一致的问题。

并发 20
在该并发量下也没有什么异常,但是偶尔某个响应时间明显长了很多。

并发 30
聚合报告:

前面开始的线程:
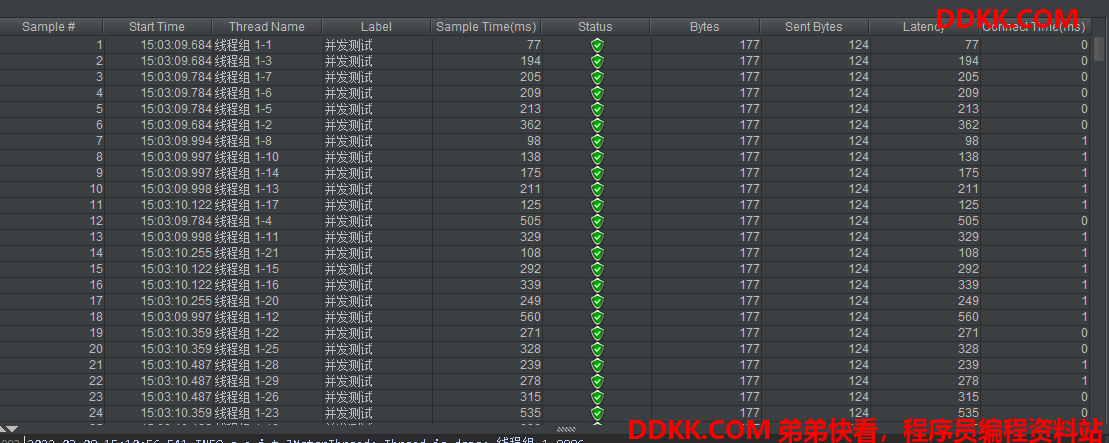
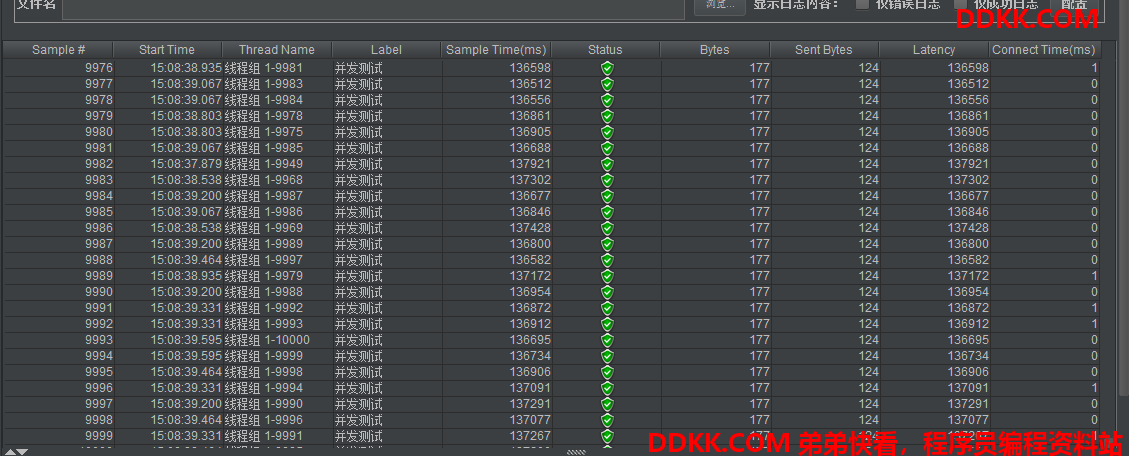
最后的线程:
订单数:
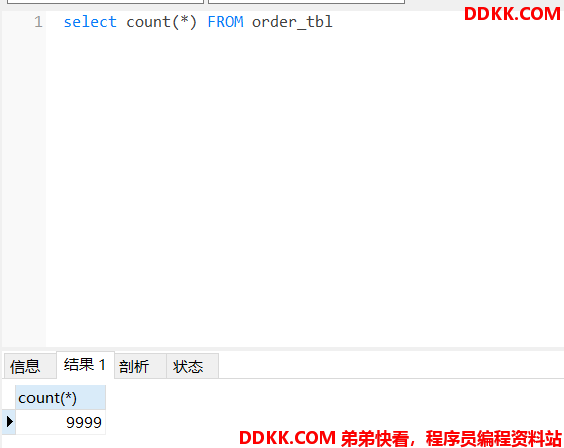
从上可以看到,当并发请求数达到30时,吞吐量仍然在20/S 左右,并且响应时间很长,存在异常,有一个订单失败。猜测响应时间过长的原因在于全局锁的竞争等待。
并发 100
在该请求并发情况下,吞吐量明显下降,异常率也飙升,失败了1000多个订单。但数据任然保持了一致性。
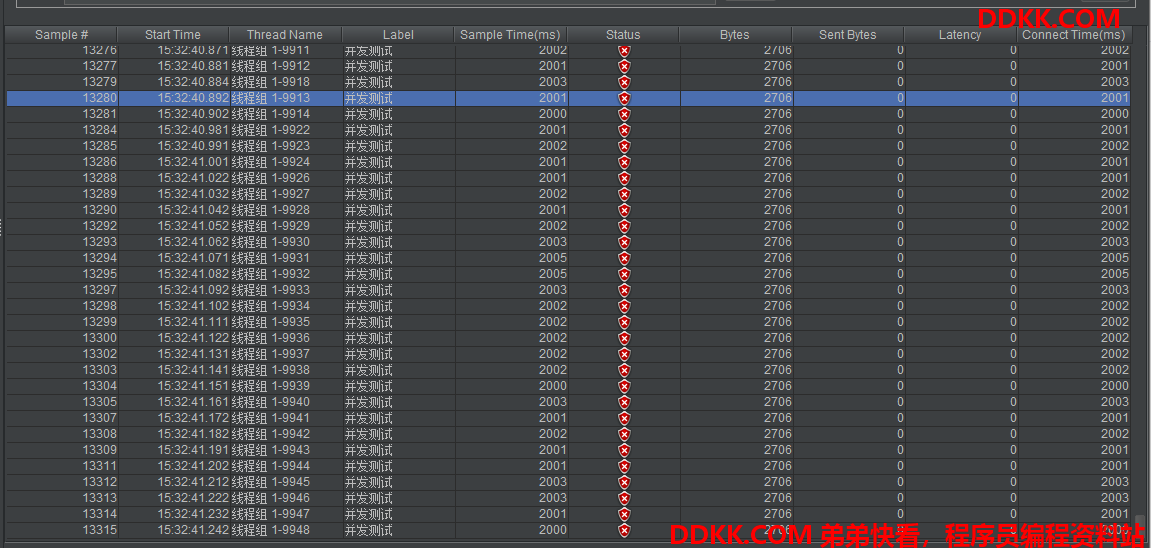
回滚测试
在库存服务中,抛出异常,测试在全局回滚的状态下,是否有并发问题。
并发10
数据无异常,全部回滚成功:

并发30
数据无异常,全部回滚成功:

并发100
数据无异常,全部回滚成功,吞吐量在50/S。

不需要全局事务测试
为了对比性,最后去掉分布式事务注解,测试下本地事务吞吐量。
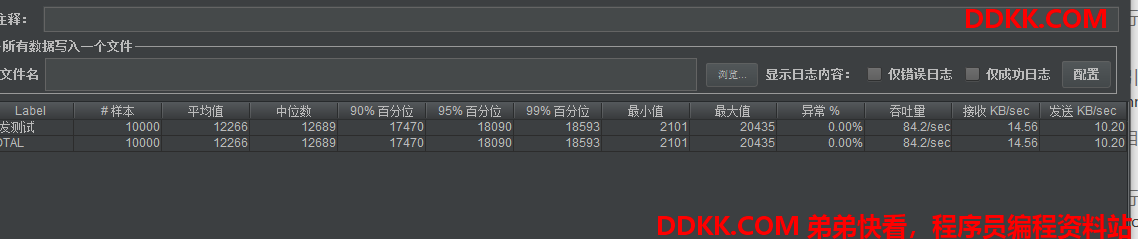
并发100
可以看到吞吐量在80/S,比分布式事务场景下还是高了不少。
总结
1. 数据一致性
在高并发下,能保持全局事务数据一致性,没有发现脏数据。
2. 吞吐量
在高并发下,吞吐量大概在20/S,性能一般,所以能不使用分布式事务就不要使用。
3. 成功率
在并发请求数超过20 时,会爆发异常,100 并发数下,异常率为18%。
4. 响应时间
随着并发增加,响应时间也会增加很多,主要原因在于,分布式事务需要全局锁。
5. 注意事项
- 总体性能不高,在高并发场景下需要搭建集群环境
- 针对某一数据的并发操作,吞吐量很低,需要做限流处理,不然会很卡或者报错