事务分组
概念
事务分组:seata的资源逻辑,可以按微服务的需要,在应用程序(客户端)对自行定义事务分组,每组取一个名字。
例如以下配置中,定义了当前事务分组名为${spring.application.name}-tx-group。
seata:
是否开启spring-boot自动装配,默认true,包括数据源的自动代理以及GlobalTransactionScanner初始化
enabled: true
应用ID
application-id: ${
spring.application.name}
事务分组名
tx-service-group: ${
spring.application.name}-tx-group
事务分组映射
service:
vgroupMapping:
demo002-tx-group: "default"
在部署Seata 服务端时,是可以设置集群名称的,默认为default,在Nacos中可以看到集群名。

可以通过registry.conf配置文件,修改当前的集群名:
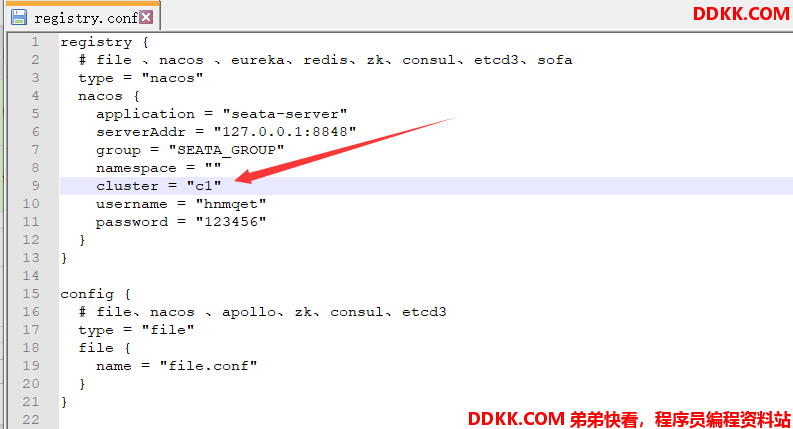
查看Nacos,可以看到当前存在两个Seata 集群,名称分别为default、c1。

集群模式下seata-server服务端由一个或多个节点组成。 应用程序(客户端)使用时需要指定事务逻辑分组与Seata服务端集群的映射关系。
比如之前我们定义当前后台的事务分组为demo002-tx-group,然后需要使用seata.service.vgroupMapping.事务分组名:集群名称来配置分组和集群的映射关系。这表示当前应用绑定的是名为default的集群。
事务分组映射
service:
vgroupMapping:
demo002-tx-group: "default"
事务分组如何找到后端Seata集群?
1. 配置事务分组名
应用程序(客户端)中配置了事务分组(GlobalTransactionScanner 构造方法的txServiceGroup参数)。
比如以下,demo002项目配置的事务分组名为:demo002-tx-group
seata:
是否开启spring-boot自动装配,默认true,包括数据源的自动代理以及GlobalTransactionScanner初始化
enabled: true
应用ID
application-id: ${
spring.application.name}
分组名
tx-service-group: ${
spring.application.name}-tx-group
当没有配置时,默认规则如下:
txServiceGroup = ${
spring.application.name}+ "-seata-service-group";
2. 配置事务分组名和集群名的映射关系
应用程序(客户端)还需要配置当前事务分组和TC集群的绑定关系。
若应用程序是SpringBoot则通过seata.service.vgroupMapping.事务分组名=集群名称 配置:
seata:
事务分组映射
service:
vgroupMapping:
demo002-tx-group: "default"
如果没有配置,默认为seata.service.vgroupMapping.my_test_tx_group=default,默认的事务分组名为xx--seata-service-group,如果不配置,就会报错。。。这里官方是否应该优化下,设置my_test_tx_group为默认的事务分组名。
if (0 == this.vgroupMapping.size()) {
this.vgroupMapping.put("my_test_tx_group", "default");
}
单个项目下的多个后台服务,配置一个分组就可以了,不需要每个服务都单独配置。
3. 获得TC服务列表
配置好当前应用程序(客户端)的服务分组名和集群名后,启动Seata 注册到注册中心中,启动后台程序时,客户端会根据事务分组名绑定的TC 集群名,去注册中心中获取真实的TC服务列表(即Seata-Server集群节点列表)。
其核心代码在NacosRegistryServiceImpl类中
public List<InetSocketAddress> lookup(String key) throws Exception {
// 1. 通过分组获取配置TC集群名。demo001-tx-group=》default
String clusterName = this.getServiceGroup(key);
if (clusterName == null) {
return null;
} else {
if (!LISTENER_SERVICE_MAP.containsKey(clusterName)) {
synchronized(LOCK_OBJ) {
if (!LISTENER_SERVICE_MAP.containsKey(clusterName)) {
List<String> clusters = new ArrayList();
clusters.add(clusterName);
// 2. 注册中心获取Seata 实例
// 参数getServiceName():registry.type.nacos.application配置的值=》seata-server
// 参数getServiceGroup():registry.type.nacos.group配置的值=》SEATA_GROUP
// 参数clusters:配置的TC集群名=》default
List<Instance> firstAllInstances = getNamingInstance().getAllInstances(getServiceName(), getServiceGroup(), clusters);
// 省略其他代码....
});
}
}
}
// 返回真实TC 列表
return (List)CLUSTER_ADDRESS_MAP.get(clusterName);
}
}
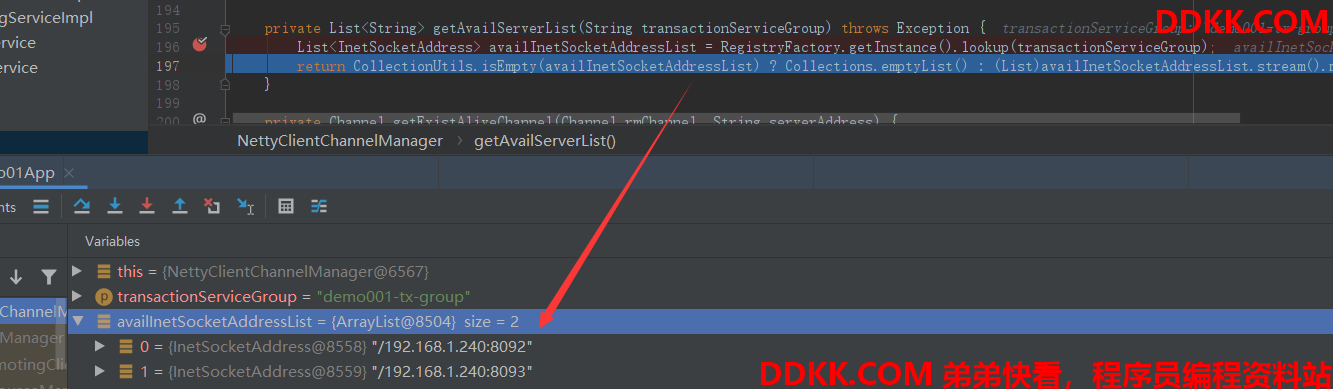
客户端通过注册中心获取到的Seata实例信息如下:
Instance{
instanceId='192.168.1.240#8092#default#SEATA_GROUP@@seata-server',
ip='192.168.1.240',
port=8092,
weight=1.0,
healthy=true,
enabled=true,
ephemeral=true,
clusterName='default',
serviceName='SEATA_GROUP@@seata-server',
metadata={
}}
最终通过服务分组名配置的集群名称,在Nacos中获取到了真实的TC服务列表。
为什么这么设计,不直接取服务名?
这里多了一层获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,出现某集群故障时可以快速failover,只切换对应分组,可以把故障缩减到服务级别,但前提也是你有足够server集群。
应用案例
事务分组的主要作用是,集群环境下,存在多个集群时,如果某个集群宕机,我们直接直接切换到可用集群。
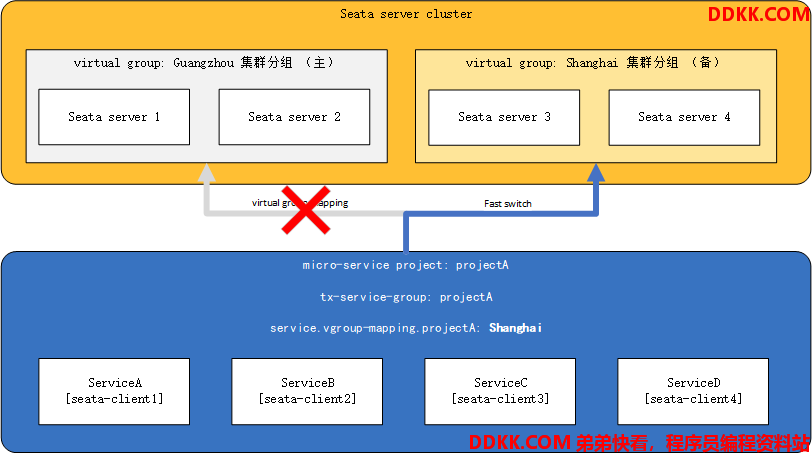
最佳实践1:TC的异地多机房容灾
- 假定TC集群部署在两个机房:guangzhou机房(主)和shanghai机房(备)各两个实例
- 一整套微服务架构项目:projectA
- projectA内有微服务:serviceA、serviceB、serviceC 和 serviceD
其中,projectA所有微服务的事务分组tx-service-group设置为:projectA,projectA正常情况下使用guangzhou的TC集群(主)
那么正常情况下,client端的配置如下所示:
seata.tx-service-group=projectA
seata.service.vgroup-mapping.projectA=Guangzhou
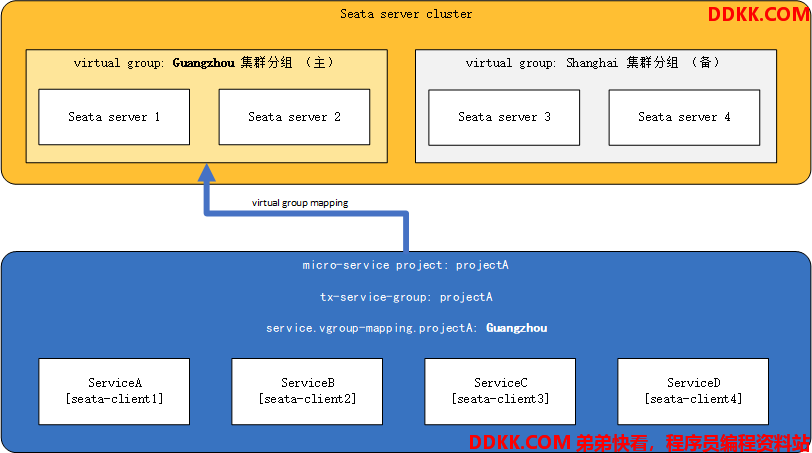
假如此时guangzhou集群分组整个down掉,或者因为网络原因projectA暂时无法与Guangzhou机房通讯,那么我们将配置中心中的Guangzhou集群分组改为Shanghai,如下:
seata.service.vgroup-mapping.projectA=Shanghai
并推送到各个微服务,便完成了对整个projectA项目的TC集群动态切换。
最佳实践2:单一环境多应用接入
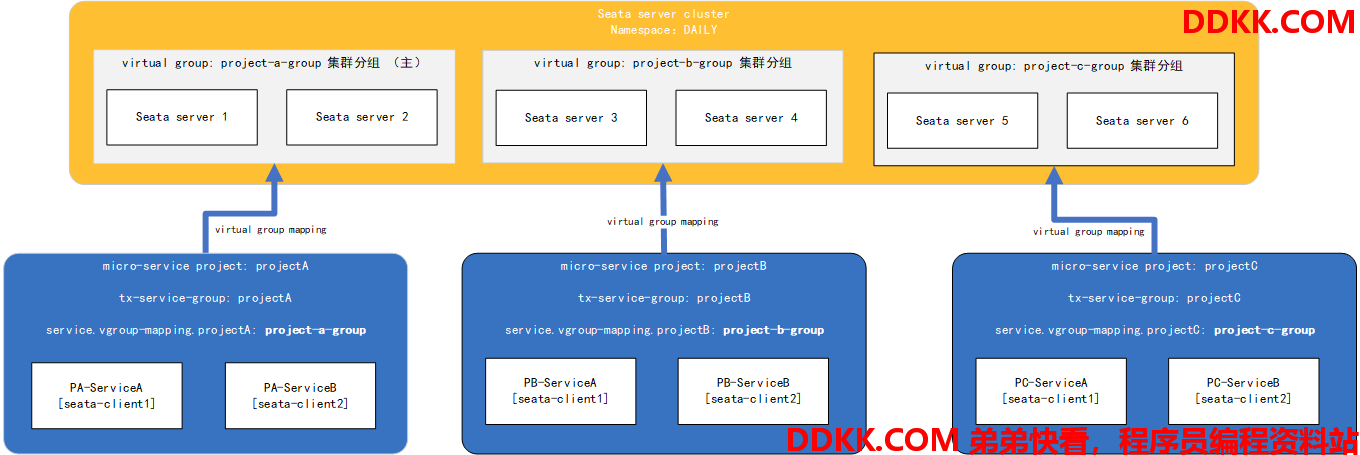
- 假设现在开发环境(或预发/生产)中存在一整套seata集群
- seata集群要服务于不同的微服务架构项目projectA、projectB、projectC
- projectA、projectB、projectC之间相对独立
我们将seata集群中的六个实例两两分组,使其分别服务于projectA、projectB与projectC,那么此时seata-server端的配置如下(以nacos注册中心为例):
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
同理在其他几个分组seata-server实例配置 project-b-group / project-c-group
cluster = "project-a-group"
username = "username"
password = "password"
}
}
client端的配置如下:
seata.tx-service-group=projectA
#同理,projectB与projectC配置 project-b-group / project-c-group
seata.service.vgroup-mapping.projectA=project-a-group
完成配置启动后,对应事务分组的TC单独为其应用服务,整体部署图如下:
最佳实践3:client的精细化控制
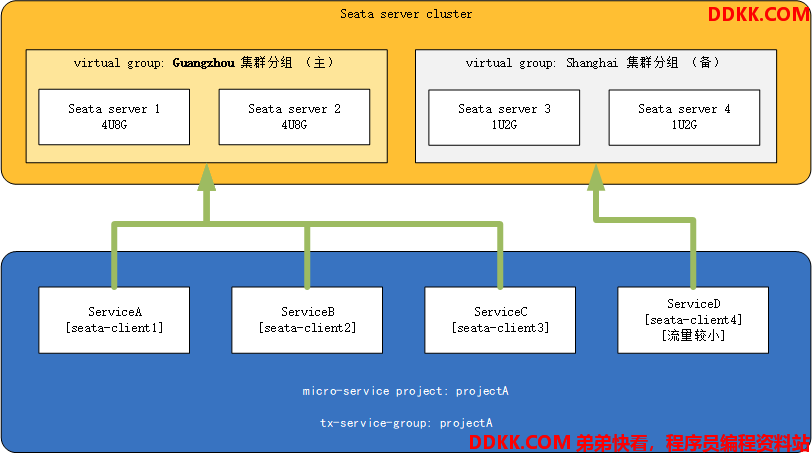
- 假定现在存在seata集群,Guangzhou机房实例运行在性能较高的机器上,Shanghai集群运行在性能较差的机器上
- 现存微服务架构项目projectA、projectA中有微服务ServiceA、ServiceB、ServiceC与ServiceD
- 其中ServiceD的流量较小,其余微服务流量较大
那么此时,我们可以将ServiceD微服务引流到Shanghai集群中去,将高性能的服务器让给其余流量较大的微服务(反之亦然,若存在某一个微服务流量特别大,我们也可以单独为此微服务开辟一个更高性能的集群,并将该client的virtual group指向该集群,其最终目的都是保证在流量洪峰时服务的可用)
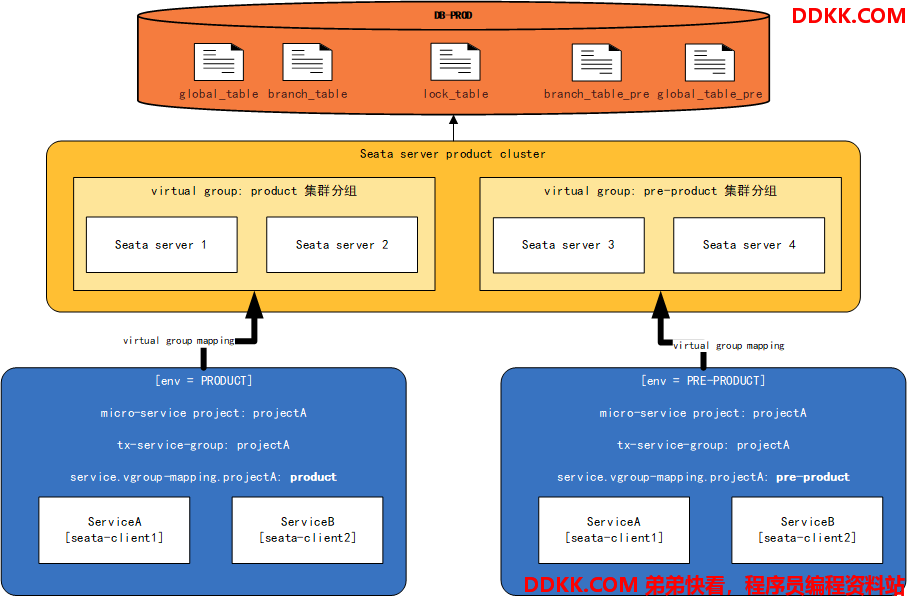
最佳实践4:Seata的预发与生产隔离
- 大多数情况下,预发环境与生产环境会使用同一套数据库。基于这个条件,预发TC集群与生产TC集群必须使用同一个数据库保证全局事务的生效(即生产TC集群与预发TC集群使用同一个lock表,并使用不同的branch_table与global_table的情况)
- 我们记生产使用的branch表与global表分别为:global_table与branch_table;预发为global_table_pre,branch_table_pre
- 预发与生产共用lock_table
此时,seata-server的 file.conf 配置如下
store {
mode = "db"
db {
datasource = "druid"
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "username"
password = "password"
minConn = 5
maxConn = 100
globalTable = "global_table" ----> 预发为 "global_table_pre"
branchTable = "branch_table" ----> 预发为 "branch_table_pre"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
seata-server的 registry.conf 配置如下(以nacos为例):
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
cluster = "pre-product" -->同理生产为 "product"
username = "username"
password = "password"
}
}
其部署图如下所示: