1. 赫夫曼编码 - 最优二叉树
大幅减少字符串编码成二进制数的长度 – 比固定长度ASCII编码减少50%
字符编码:将字符转成二进制进行网络传输
字符编码方法
1、 纯ascii编码-每个字符都转成固定8位二进制--占用空间大;
2、 计算句子同样字符出现个数,自己定义不定长的二进制位数进行表示字符,一啊不般出现次数越多,位数越少-不固定编码,占用空间小,但编码会冲突;
3、 赫夫曼编码:利用赫夫曼树进行编码字符--不固定编码,大大减少空间,但编码不冲突;
赫夫曼编码流程
1、 计算目标字符串中各个字符出现的次数;
2、 将步骤1重构成最优二叉树-节点的每个权重代表字符出现的次数;
3、 字符编码:根节点到某个字符节点的路径(左为0、右为1);
4、 根据3步骤的字符编码,将目标字符串转成二进制编码;
OptimalBinaryTree.java
/**
* @Classname OptimalBinaryTree
* @Description
* @Date 2022/4/13 10:48
* @Created by lrc
*/
public class OptimalBinaryTree<T> {
//二叉树根节点 - 根据datas进行组建
Node<T> root;
//构造器传入的数据
T[] datas;
//传数组构造最优二叉树
OptimalBinaryTree(@NotNull T...datas) {
T[] copyData = Arrays.copyOf(datas, datas.length);
Arrays.sort(copyData);
// System.out.println(Arrays.toString(copyData));
datas = copyData;
createdOptimalBinaryTree(datas);
}
public Node<T> getRoot() {
return root;
}
// 最优二叉树 - 中序遍历
public String inOrder() {
StringBuilder sb = new StringBuilder();
sb.append("[");
//真正的中序遍历
root.inOrder(root,sb);
sb.replace(sb.lastIndexOf(", "), sb.length(), "");
sb.append("]");
return sb.toString();
}
// 最优二叉树 - 前序遍历
public String preOrder() {
StringBuilder sb = new StringBuilder();
sb.append("[");
//真正的前序遍历
root.preOrder(root,sb);
sb.replace(sb.lastIndexOf(", "), sb.length(), "");
sb.append("]");
return sb.toString();
}
@Override
public String toString() {
return preOrder();
}
private boolean createdOptimalBinaryTree(T[] datas) {
LinkedList<Node<T>> list = new LinkedList<>();
boolean flag = false;
Node<T> newNode;
for(T data : datas) {
newNode = new Node<>();
newNode.setData(data);
list.add( newNode );
}
while(true) {
//弹出两个子节点,构成左右子树
Node<T> lNode = list.pop();
Node<T> rNode = list.pop();
//父节点权重是上面两个子节点的权重
Node<T> parNode = new Node<>();
parNode.weight = lNode.weight + rNode.weight;
parNode.leftNode = lNode;
parNode.rightNode = rNode;
//父节点必须往链表头添加 - 否则遇到weigth相同时,组件二叉树会混乱
list.addFirst(parNode);
Collections.sort(list);
//打印当前链表情况
// System.out.println("遍历" + list);
//如果链表中只有一个元素,说明这个节点就是根节点
if(list.size() == 1) {
root = list.get(0);
flag = true;
break;
}
}
return flag;
}
protected class Node<T> implements Comparable<Node> {
T data;
Integer weight;
Node<T> leftNode;
Node<T> rightNode;
public T getData() {
return data;
}
public Node<T> getLeftNode() {
return leftNode;
}
public void setLeftNode(Node<T> leftNode) {
this.leftNode = leftNode;
}
public Node<T> getRightNode() {
return rightNode;
}
public void setRightNode(Node<T> rightNode) {
this.rightNode = rightNode;
}
public void preOrder(Node node, StringBuilder sb) {
sb.append(node.toString() + ", ");
if(node.leftNode != null) {
preOrder(node.leftNode, sb);
}
if(node.rightNode != null) {
preOrder(node.rightNode, sb);
}
}
public void inOrder(Node node, StringBuilder sb) {
if(node.leftNode != null) {
inOrder(node.leftNode, sb);
}
sb.append(node.toString() + ", ");
if(node.rightNode != null) {
inOrder(node.rightNode, sb);
}
}
public void setData(T data) {
this.data = data;
//节点的权重硬性规定为数据data内部的权重
try {
Field field = data.getClass().getDeclaredField("weight");
field.setAccessible(true);
weight = (Integer) field.get(data);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", weight=" + weight +
'}';
}
// node排序必须要实现这个函数 大于实参则大于0 小于则小于0 等于则等于0
@Override
public int compareTo(Node node) {
return this.weight - node.weight;
}
}
public static void main(String[] args) {
//1. 数据准备 - 为什么写那么麻烦,主要是写熟悉一些数组、链表之间的转换函数
Student student1 = new Student(1, "lrc", 8);
Student student2 = new Student(2, "qcj", 2);
Student student3 = new Student(3, "ert", 10);
Student student4 = new Student(4, "bfg", 5);
Student student5 = new Student(5, "ytu", 25);
Student[] stu = {
student1,student2,student3,student4,student5};
// 2 5 8 10 25
// 7 8 10 25
// 10 15 25
// 25 25
// 50
//2. 构造最优二叉树
OptimalBinaryTree<Student> tree = new OptimalBinaryTree(stu);
//3. 前序遍历二叉树
System.out.println(tree);
}
}
HuffmanCode.java
package top.linruchang.algorithm.tree;
import java.util.*;
/**
* @Classname HuffmanCode
* @Description
* @Date 2022/4/13 21:27
* @Created by lrc
*/
public class HuffmanCode {
// 根据data字符个数构建赫夫曼二叉树
OptimalBinaryTree<MyCharacter> tree;
//需要被赫夫曼编码的原字符串
String data;
//赫夫曼编码字符串data
String encodedData;
//压缩encodedData的数据
byte[] encodedDataArray;
//存储data字符串对应的每个字符个数记录
HashMap<Character, MyCharacter> charMap;
//根据tree获取对应字符的赫夫曼编码
HashMap<Character, String> codeMap = new HashMap<>();
HuffmanCode(String str) {
//需要被赫夫曼编码的原字符串
this.data = str;
// 1. 计算字符串各个字符出现的次数
initCharMap(str);
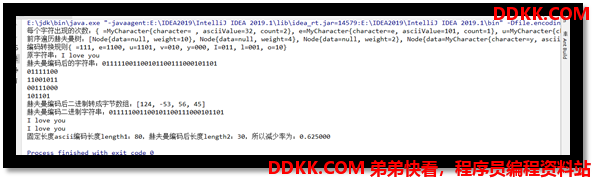
System.out.println("每个字符出现的次数:" + charMap);
// 2. 构造最优二叉树
MyCharacter[] myCharacters = new MyCharacter[charMap.size()];
charMap.values().toArray(myCharacters);
tree = new OptimalBinaryTree<>(myCharacters);
System.out.println("前序遍历赫夫曼树:" + tree);
//3. 根据tree获取对应字符的赫夫曼编码
initHuffmanCode(tree.getRoot(), "", new StringBuilder());
System.out.println("编码转换规则" + codeMap);
//4. 根据codeMap字符编码规则将data字符串转成二进制编码
EncodingData();
System.out.println("原字符串:" + data);
System.out.println("赫夫曼编码后的字符串:" + encodedData);
//5. 压缩encodedData
zipCode();
}
public HashMap<Character, String> getCodeMap() {
return codeMap;
}
/**
* 解码
* @param binaryMessg 字节数组
* @param codeMap 赫夫曼编码规则
* @return 返回原字符串
*/
public static String decode(byte[] binaryMessg, Map< Character, String> codeMap) {
String encodedDataByBytes = getEncodedDataByBytes(binaryMessg, codeMap);
return decode(encodedDataByBytes, codeMap);
}
/**
*
* @param binaryMessg 二进制字符串
* @param codeMap 赫夫曼编码规则
* @return 返回原字符串
*/
public static String decode(String binaryMessg, Map< Character, String> codeMap) {
StringBuilder textContent = new StringBuilder();
Set<Map.Entry<Character, String>> entries = codeMap.entrySet();
Integer startIndex = 0;
while(true) {
String code;
Integer tempEndIndex;
for(Map.Entry<Character, String> map: entries) {
code = map.getValue();
tempEndIndex = startIndex + code.length();
if(tempEndIndex > binaryMessg.length()) {
continue;
}
String substr = binaryMessg.substring(startIndex, tempEndIndex);
if(code.equals(substr)) {
textContent.append(map.getKey());
startIndex = tempEndIndex;
break;
}
}
if(startIndex >= binaryMessg.length()) {
break;
}
}
return textContent.toString();
}
/**
*
* @param bytes 字节数组 - 存储了赫夫曼编码的信息
* @param codeMap 匹配规则
* @return 返回赫夫曼编码的二进制信息 - 根据这段信息进行解码
*/
public static String getEncodedDataByBytes(byte[] bytes, Map< Character, String> codeMap) {
StringBuilder sb = new StringBuilder();
int j = 0;
for(byte b : bytes) {
String binStr = Integer.toBinaryString(b);
if(binStr.length() <= 8) {
if(j == bytes.length -1) {
sb = adjustString(sb, new StringBuilder(binStr), codeMap);
break;
}
for(int i = 0; i<8-binStr.length(); i++) {
sb.append("0");
}
sb.append(binStr);
}
if(binStr.length() > 8) {
sb.append(binStr.substring(binStr.length()-8));
}
j++;
}
return sb.toString();
}
/**
* 这段代码别看了,实在是太冗余,写完我都不想在看它,懒得重构
* 修改最后一段二进制与前面一段二进制 - 因为Integer.toBinaryString得到的补码会忽略到前面的0,故需要补全
* @param prefixSb
* @param suffixSb
* @param codeMap
* @return
*/
public static StringBuilder adjustString(StringBuilder prefixSb, StringBuilder suffixSb, Map< Character, String> codeMap) {
//1. 找到前半段没有匹配的二进制字符
Integer startIndex = 0;
Integer endIndex = 0;
String prefixStr = prefixSb.toString();
String suffixStr = suffixSb.toString();
Collection<String> codes = codeMap.values();
Integer count = 0;
while(true) {
++count;
//遍历查询前缀字符对应赫夫曼编码
//说明持续验证最后一段都不能找到对应的赫夫曼编码
if(count == 2) {
break;
}
for(String code : codes) {
Integer curEndIndex = startIndex + code.length();
//截图的结束索引大于被截取字段本身 - 则忽略该次查询
if(curEndIndex > prefixSb.length()) {
continue;
}
String substr = prefixStr.substring(startIndex, curEndIndex);
if(code.equals(code)) {
startIndex = curEndIndex;
endIndex = curEndIndex;
count = 0;
break;
}
}
//前半段都符合编码情况
if(startIndex >= prefixSb.length()) {
break;
}
}
// 2.找到赫夫曼编码符合修复条件的几个编码
String waitPrefixStr = null;
List<String> waitPrefixStrs = new ArrayList<String>();
if(startIndex != prefixStr.length()) {
waitPrefixStr = prefixStr.substring(startIndex);
System.out.println("waitPrefix:" + waitPrefixStr);
//查找修复前缀字段等待字段
for(String code : codes) {
//只有短过赫夫曼编码的才是需要被修复,否则不用修复
if(code.length() > waitPrefixStr.length()) {
boolean isMatch = code.substring(0,waitPrefixStr.length()).matches(waitPrefixStr);
if(isMatch) {
//waitPrefixStr只有末尾等于有0才用修复,否则不用修复
if(code.charAt(waitPrefixStr.length()) == '0') {
waitPrefixStrs.add(code);
}
}
}
}
}
//3. 真正的修复前半段 - 利用waitPrefixStrs进行依依比对
if(waitPrefixStrs.size() > 0) {
String copyWaitPrefixStr = new String(waitPrefixStr);
for(String repairTarget : waitPrefixStrs) {
for(int index = waitPrefixStr.length(); index < repairTarget.length(); index++) {
if(repairTarget.charAt(index) == '0') {
copyWaitPrefixStr += "0";
}else {
break;
}
}
String tempSuffixStr = copyWaitPrefixStr + suffixStr;
Integer sufixStartIndex = 0;
Integer suffixCount = 0;
//验证当前的copyWaitPrefixStr是否是需要的
boolean isValid = false;
while(true) {
++suffixCount;
if(suffixCount == 2) {
break;
}
for(String code : codes) {
Integer curSuffixEndIndex = sufixStartIndex + code.length();
if(curSuffixEndIndex > tempSuffixStr.length()) {
continue;
}
if(tempSuffixStr.substring(sufixStartIndex, curSuffixEndIndex).equals(code)) {
sufixStartIndex = curSuffixEndIndex;
suffixCount = 0;
break;
}
}
if(sufixStartIndex == tempSuffixStr.length()) {
isValid = true;
break;
}
}
if(isValid) {
for(int index = waitPrefixStr.length(); index < repairTarget.length(); index++) {
if(repairTarget.charAt(index) == '0') {
prefixSb.append("0");
}else {
break;
}
}
break;
}
}
}
return prefixSb.append(suffixSb);
}
public String getEncodedData() {
return encodedData;
}
private void zipCode() {
byte[] bytes;
//1.获取数组长度
Integer length = encodedData.length();
if (length % 8 == 0) {
bytes = new byte[length / 8];
} else {
bytes = new byte[length / 8 + 1];
}
//2.每8位截取一段字符(补码),将其转成10进制
Integer startIndex = 0;
Integer endIndex = 8;
Integer byteIndex = 0;
while (startIndex < length - 1) {
String binaryNum = encodedData.substring(startIndex, endIndex);
System.out.println(binaryNum);
Integer num = Integer.valueOf(binaryNum, 2);
bytes[byteIndex++] = num.byteValue();
startIndex += 8;
endIndex += 8;
if (endIndex > length) {
endIndex = length;
}
}
//3.返回字节数组
encodedDataArray = bytes;
}
public byte[] getEncodedDataBytes() {
return encodedDataArray;
}
public void EncodingData() {
char[] chars = new char[data.length()];
data.getChars(0, data.length(), chars, 0);
StringBuilder sb = new StringBuilder();
for (char curChar : chars) {
String code = codeMap.get(curChar);
sb.append(code);
}
encodedData = sb.toString();
}
/**
* 根据赫夫曼树 - 获取字符赫夫曼编码
*
* @param node 当前节点
* @param signLR 标记是左节点还是右节点 0:左节点 1:右节点
* @param sb 存储到达路径 --根据上述signLR存储 -- 字符赫夫曼编码
*/
private void initHuffmanCode(OptimalBinaryTree.Node node, String signLR, StringBuilder sb) {
StringBuilder sb2 = new StringBuilder(sb);
sb2.append(signLR);
if (node != null) {
if (node.data == null) {
initHuffmanCode(node.leftNode, "0", sb2);
initHuffmanCode(node.rightNode, "1", sb2);
} else {
Character curCharacter = ((MyCharacter) node.getData()).getCharacter();
codeMap.put(curCharacter, sb2.toString());
}
}
}
//计算原字符串各个字符出现的次数
private void initCharMap(String str) {
char[] chars = new char[str.length()];
str.getChars(0, str.length(), chars, 0);
charMap = new HashMap<>();
for (char curChar : chars) {
boolean hasKey = charMap.containsKey(curChar);
MyCharacter curCharacter;
if (hasKey) {
curCharacter = charMap.get(curChar);
Integer count = curCharacter.getCount();
curCharacter.setCount(++count);
} else {
curCharacter = new MyCharacter();
curCharacter.setCharacter(curChar);
curCharacter.setCount(1);
charMap.put(curChar, curCharacter);
}
}
}
//内部类 - 用来存储原字符串对应的字符以及出现次数、以及节点权重
private class MyCharacter implements Comparable<MyCharacter> {
Character character;
Integer asciiValue;
Integer count;
Integer weight;
public Character getCharacter() {
return character;
}
public void setCharacter(Character character) {
this.character = character;
this.asciiValue = (int) character.charValue();
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
this.weight = count;
}
@Override
public String toString() {
return "MyCharacter{" +
"character=" + character +
", asciiValue=" + asciiValue +
", count=" + count +
'}';
}
@Override
public int compareTo(MyCharacter orderCharacter) {
return this.count - orderCharacter.count;
}
}
public static void main(String[] args) {
// String str = "abcfdef tratr egcs";
String str = "I love you";
HuffmanCode code = new HuffmanCode(str);
System.out.println("赫夫曼编码后二进制转成字节数组:" + Arrays.toString(code.getEncodedDataBytes()));
//通过字节数组进行节码
byte[] bytes = code.getEncodedDataBytes();
//将字节数组转成二进制字符串 - 通过二进制字符串转成原字符串明文
String encodeStr = HuffmanCode.getEncodedDataByBytes(bytes, code.getCodeMap());
System.out.println("赫夫曼编码二进制字符串:" + encodeStr);
System.out.println(code.decode(encodeStr, code.getCodeMap()));
System.out.println(code.decode(bytes, code.getCodeMap()));
Integer length1 = str.length() * 8;
Integer length2 = code.getEncodedData().length();
double redPer = (length1 - length2) / (double) length1;
System.out.printf("固定长度ascii编码长度length1:%d,赫夫曼编码后长度length2:%d,所以减少率为:%f\n", length1, length2, redPer);
}
}