摘要
并查集可以快速查找多个点之间是否连接,以及快速连接多个点。并且并查集使用数组的数据结构实现。那么如何利用数组的结构实现?以及为什么能够快速查找和连接呢?文章将给出答案。
假如有n个村庄,有些村庄之间有连接的路,有些村庄之间没有连接的路。那么如何快速地查询其中的两个村庄是否有连接的路?如何快速地连接两个村庄之间的路呢?
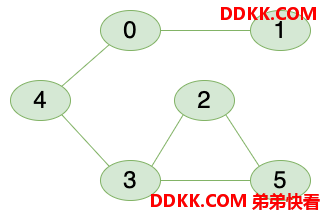
并查集就能办到这种快速查找和连接的问题。它的查询和连接的均摊时间复杂度都是O(a(n)),a(n) < 5,是解决这种问题首先要选择的数据结构。
使用数组、链表、平衡二叉树或者集合(Set)也是可以实现,但是在查询和连接的时间复杂度上都是 O(n),远低于并查集的时间复杂度。
通过字面意思看出,并查集的两个核心操作就是查找、合并:
- 查找(Find):查找元素所在的集合(集合不是只 Set 这样的数据结构,而是广义的数据集合)
- 合并(Union):将两个元素所在的集合合并成一个集合。
在并查集中实现查找和合并有2种不同的思路:
1、 Find优先,达到Find的时间复杂度为O(1),但Union的时间复杂度为O(n);
2、 Union优先,达到Union的时间复杂度为O(logn),同时Find的时间复杂度也能达到O(logn),甚至可以优化到O(a(n)),a(n)<5的情况;
这两种思路的本质就在于存储数据的方式不同,造成的不同的时间复杂度,两种思路没有高低之分,使用哪一种,要根据实际的应用场景来决定。
存储数据
假设并查集处理的数据都是整型,那么就可以用整型数组来存储数据,如下图所示的集合:

通过图中可以看出,0、1、3属于同一集合,2单独属于一个集合,4、5、6、7属于同一集合。上图展示的是 Find 优先思路存储的数据。
由图中可以看出,并查集是可以用数组实现的树形结构。
如果看过前几期的文章,会发现之间实现的二叉堆、优先级队列也是用数组来实现的。
用代码实现并查集之前,需要先定义一些接口:
1、 查找v所属的集合(根节点);
int find(int v);
1、 合并v1、v2所属的集合;
void union(int v1, int v2);
1、 检查v1、v2是否属于同一个集合;
boolean isSame(int v1, int v2)
因为已经有查找 v 所属的集合接口,那么检查 v1、v2 是否属于同一个集合的代码就很好实现:
public boolean isSame(int v1, int v2) {
return find(v1) == find(v2);
}
最后一项准备工作,就是确定好初始化的规则,这里规定,当初始化时,数组中的每一个元素都各自属于自己的集合,如下图:

实现的代码如下:
// 数组
protected int[] parents;
protected UnionFind(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("capacity mush be >= 1");
}
parents = new int[capacity];
for (int i = 0; i < parents.length; i++) {
parents[i] = i;
}
}
代码中的 capacity 是确定集合的容量,并按照这个容量初始化一个数组。
Quick Find
以上面初始化的数组为例(数组中有0到4的元素),Quick Find 为了让 Find 的时间复杂度成为 O(1)。所以在合并的时候,就尽量保证元素到所属的集合(即根节点)路径短一些。为了达到这个目标,在将一个集合合并到其中一个集合中时,就直接将其中的一个集合根节点指向另外一个集合的根节点。
比如在已经初始化的数组中,0 所在的集合是 0(即根节点是 0),1 所在的集合是 1…4 所在的集合是4,之后执行如下 union 函数时:
1、union(1,0):1->0,0->0;
2、union(1,2):1->2,0->2;;
3、union(3,4):3->4,4->4;;
4、union(0,3):0->4,1->4,2->4,3->4,4->4;;
由上面流程可以看出,当一个元素的集合A合并到两外一个元素的集合B是,会把集合A中的所有元素都指向集合B的根节点(这就是 O(n) 的本质)。
在写代码之间,需要统一一下做法,若 0 的根节点是 0,即数组中 0 索引存放的元素是 0。
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
// 将 p1 集合中的元素都指向 p2(根节点)
for (int i = 0; i < parents.length; i++) {
if (parents[i] == p1) {
parents[i] = p2;
}
}
}
代码中可以看到 find() 函数,这个是查找元素所在集合的函数。因为集合中的元素都直接指向根节点,所以就可以通过索引来获取根节点(这也是 O(1) 本质):
public int find(int v) {
rangeCheck(v);
return parents[v];
}
代码中的 rangeCheck() 函数是检查元素 v 是否合法:
void rangeCheck(int v) {
if (v < 0 || v >= parents.length) {
throw new IllegalArgumentException("v is out of bounds");
}
}
Quick Union
Quick Union 是保证合并和查找尽量均衡,所以当两个集合合并的时候,是把一个集合的根节点指向另外一个集合的根节点。
还是以0到4的数组为例:
1、union(1,0):1->0,0->0;;
2、union(1,2):1->0->2,2->2;;
3、union(3,4):3->4,4->4;;
4、union(3,1):3->4->2,1->0->2;;
通过流程可以看出,当集合A合并到集合B时,集合A的根节点直接指向集合B的根节点:
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
// p1 指向 p2
parents[p1] = p2;
}
下面看一下 find() 函数的代码实现:
public int find(int v) {
rangeCheck(v);
while (v != parents[v]) {
// 当索引和存放的元素相等时,就是根节点
v = parents[v];
}
return v;
}
查看合并和查找代码时,可以看出最消耗时间的是查找。但是整个集合的结构类似树结构,所以查找的耗时可以缩短到 O(logn)。
总结
- 并查集可以解决多点之间的连接和查询问题;
- 可以优先查找或者优先合并,带来的时间复杂度都是不同的,两者没有优劣之分;
- 并查集可以通过数组来实现。