1. Flink中的Transformation算子概述
Apache Flink 1.12 Documentation: Operators
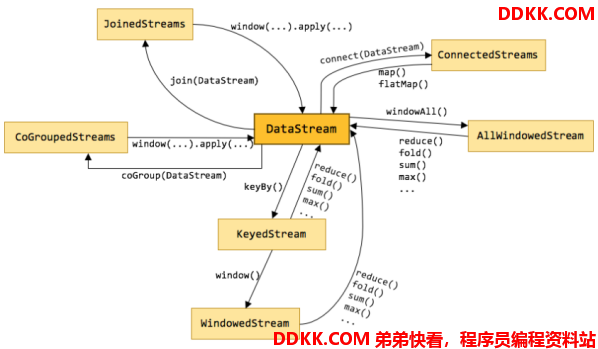
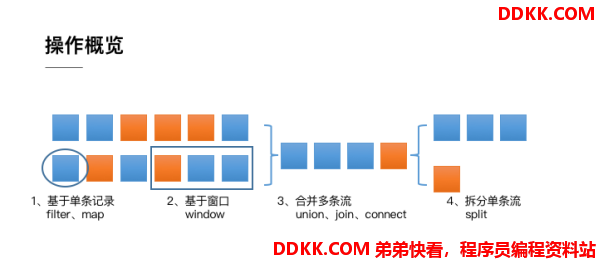
整体来说,流式数据上的操作可以分为四类:
1、 第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter操作),或者将每条记录都做一个转换(Map操作);
2、 第二类是对多条记录的操作比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起为了支持这种类型的操作,就得通过Window将需要的记录关联到一起进行处理;
3、 第三类是对多个流进行操作并转换为单个流例如,多个流可以通过Union、Join或Connect等操作合到一起这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作;
4、 最后,DataStream还支持与合并对称的拆分操作,即把一个流按一定规则拆分为多个流(Split操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理;
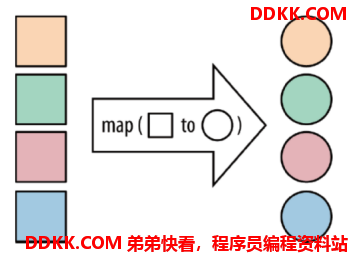
2. Map算子
map:将函数作用在集合中的每一个元素上,并返回作用后的结果
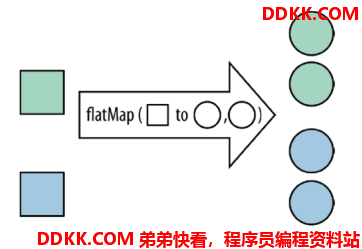
3. flatMap算子
将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
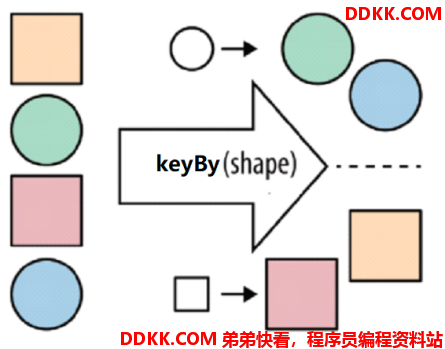
4. keyby算子
按照指定的key来对流中的数据进行分组,注意: 流处理中没有groupBy,而是keyBy
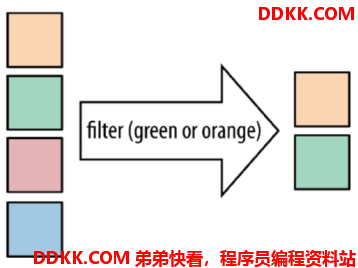
5. filter算子
按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
6. sum算子
照指定的字段对集合中的元素进行求和
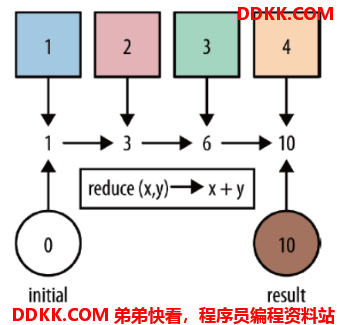
7. reduce算子
对集合中的元素进行聚合
8. 代码演示
使用了上述所有的基础算子,实现对流数据中的单词进行统计,排除敏感词heihei的功能
8.1. Java代码
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc
*/
public class TransformationDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStream<String> linesDS = env.socketTextStream("node1", 9999);
//3.处理数据-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
DataStream<String> filtedDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !value.equals("heihei");
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = filtedDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result1 = groupedDS.sum(1);
DataStream<Tuple2<String, Integer>> result2 = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value1.f1);
}
});
//4.输出结果-sink
result1.print("result1");
result2.print("result2");
//5.触发执行-execute
env.execute();
}
}
8.2. Scala代码
import com.ouyang.bean.SensorReading
import org.apache.flink.streaming.api.scala._
/**
* @ Date:2020/12/3
* @ Author:yangshibiao
* @ Desc:Flink中转换算子
*/
object TransformDemo {
def main(args: Array[String]): Unit = {
// 执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
// 获取数据,并转换成流
val fileStream: DataStream[String] = env.readTextFile("D:\\Project\\IDEA\\bigdata-study\\flink-demo\\src\\main\\resources\\source.txt")
// 1、map
val mapStream: DataStream[SensorReading] = fileStream.map(data => {
val fields: Array[String] = data.split(",")
SensorReading(fields(0).trim, fields(1).trim.toLong, fields(2).trim.toDouble)
})
// 2、filter
val filterStream: DataStream[SensorReading] = mapStream.filter(_.id == "sensor_1")
// 3、flatMap
val flatMapStream: DataStream[String] = fileStream.flatMap(_.split(","))
// 4、keyBy
val keyByStream: KeyedStream[SensorReading, String] = mapStream.keyBy(_.id)
// 5、Rolling Aggregation(滚动聚合算子,需要先进行keyBy,才进行聚合,包括sum,min,max,minBy,maxBy)
val sumStream: DataStream[SensorReading] = keyByStream.sum("temperature")
val maxStream: DataStream[SensorReading] = keyByStream.max(2)
// 6、reduce
val reduceStream: DataStream[SensorReading] = keyByStream.reduce((x, y) => SensorReading(x.id, y.timestamp, x.temperature + y.temperature))
// 7、Split 和 Select
val splitStream: SplitStream[SensorReading] = mapStream.split(sensorReading => {
if (sensorReading.temperature < 30) Seq("low") else Seq("high")
})
val lowStream: DataStream[SensorReading] = splitStream.select("low")
val highStream: DataStream[SensorReading] = splitStream.select("high")
val allStream: DataStream[SensorReading] = splitStream.select("low", "high")
// 8、Connect和 CoMap
val warning: DataStream[(String, Double)] = highStream.map(sonsorData => (sonsorData.id, sonsorData.temperature))
val connected: ConnectedStreams[(String, Double), SensorReading] = warning.connect(lowStream)
val connectedResult: DataStream[Product] = connected.map(
warningData => (warningData._1, warningData._2, "warning"),
lowData => (lowData.id, "healthy")
)
// 9、Union
val unionStream: DataStream[SensorReading] = lowStream.union(highStream)
// 打印数据
unionStream.print()
// 启动执行环境,开始任务
env.execute("TransformDemo")
}
}