1. 重启策略配置方式
①配置文件中
在flink-conf.yml中可以进行配置,示例如下:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
②代码中
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 延迟时间间隔
))
2. 重启策略分类
2.1. 默认重启策略
如果配置了Checkpoint,而没有配置重启策略,那么代码中出现了非致命错误时,程序会无限重启
2.2. 无重启策略
Job直接失败,不会尝试进行重启
设置方式1:
restart-strategy: none
设置方式2:
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())
2.3. 固定延迟重启策略
在开发中经常使用
设置方式1:
重启策略可以配置flink-conf.yaml的下面配置参数来启用,作为默认的重启策略:
例子:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
设置方式2:
也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 最多重启3次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))
上面的设置表示:如果job失败,重启3次, 每次间隔10
2.4. 失败率重启策略
在开发中偶尔使用
设置方式1:
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
例子:
restart-strategy:failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
设置方式2:
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
))
上面的设置表示:如果5分钟内job失败不超过三次,自动重启, 每次间隔10s (如果5分钟内程序失败超过3次,则程序退出)
3. 代码演示
package com.ddkk.checkpoint;
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* Author ddkk.com 弟弟快看,程序员编程资料站
* Desc 演示Checkpoint+重启策略
*/
public class CheckpointDemo02_RestartStrategy {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//===========Checkpoint参数设置====
//===========类型1:必须参数=============
//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!
env.enableCheckpointing(1000);
//设置State状态存储介质
/*if(args.length > 0){
env.setStateBackend(new FsStateBackend(args[0]));
}else {
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
}*/
if(SystemUtils.IS_OS_WINDOWS){
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
}else{
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
}
//===========类型2:建议参数===========
//设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)
//如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//默认是0
//设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);//默认值为0,表示不容忍任何检查点失败
//设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===========类型3:直接使用默认的即可===============
//设置checkpoint的执行模式为EXACTLY_ONCE(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。
env.getCheckpointConfig().setCheckpointTimeout(60000);//默认10分钟
//设置同一时间有多少个checkpoint可以同时执行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//默认为1
//=============重启策略===========
//-1.默认策略:配置了Checkpoint而没有配置重启策略默认使用无限重启
//-2.配置无重启策略
//env.setRestartStrategy(RestartStrategies.noRestart());
//-3.固定延迟重启策略--开发中使用!
//重启3次,每次间隔10s
/*env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, //尝试重启3次
Time.of(10, TimeUnit.SECONDS))//每次重启间隔10s
);*/
//-4.失败率重启--偶尔使用
//5分钟内重启3次(第3次不包括,也就是最多重启2次),每次间隔10s
/*env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 每次重启的时间间隔
));*/
//上面的能看懂就行,开发中使用下面的代码即可
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));
//2.Source
DataStream<String> linesDS = env.socketTextStream("node1", 9999);
//3.Transformation
//3.1切割出每个单词并直接记为1
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//value就是每一行
String[] words = value.split(" ");
for (String word : words) {
if(word.equals("bug")){
System.out.println("手动模拟的bug...");
throw new RuntimeException("手动模拟的bug...");
}
out.collect(Tuple2.of(word, 1));
}
}
});
//3.2分组
//注意:批处理的分组是groupBy,流处理的分组是keyBy
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOneDS.keyBy(t -> t.f0);
//3.3聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4.sink
result.print();
//5.execute
env.execute();
}
}
4. 手动重启并恢复
步骤一 :把程序打包

步骤二 :启动Flink集群(本地单机版,集群版都可以)
/export/server/flink/bin/start-cluster.sh
步骤三 :访问webUI
http://node1:8081/#/overview
http://node2:8081/#/overview
步骤四 :使用FlinkWebUI提交(注意输入启动类)
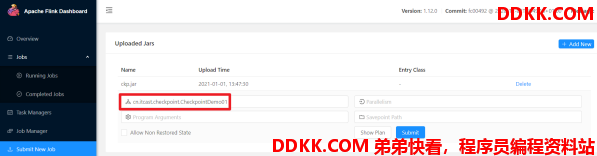
步骤五 :取消任务

步骤六 :重新启动任务并指定从哪恢复(注意输入启动类和恢复的Checkpoint地址)
com.ddkk.checkpoint.CheckpointDemo01
hdfs://node1:8020/flink-checkpoint/checkpoint/9e8ce00dcd557dc03a678732f1552c3a/chk-34
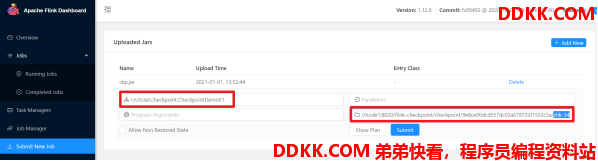
步骤七 :关闭/取消任务

步骤八:关闭集群
/export/server/flink/bin/stop-cluster.sh
5. 选择一个状态后端并配置重启策略
- MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上;而将checkpoint存储在JobManager的内存中。
- FsStateBackend
将checkpoint存到远程的持久化文件系统(FileSystem)上。而对于本地状态,跟MemoryStateBackend一样,也会存在TaskManager的JVM堆上。
- RocksDBStateBackend
将所有状态序列化后,存入本地的RocksDB中存储。
注意:RocksDB的支持并不直接包含在flink中,需要引入依赖:
<!-- 导入rocksdb依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.10.0</version>
</dependency>
// 设置状态后端为FsStateBackend并配置重启策略
val env = StreamExecutionEnvironment.getExecutionEnvironment
val checkpointPath: String = ???
val backend = new RocksDBStateBackend(checkpointPath)
env.setStateBackend(backend)
env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints"))
env.enableCheckpointing(1000)
// 配置重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60, Time.of(10, TimeUnit.SECONDS)))