1. 原理
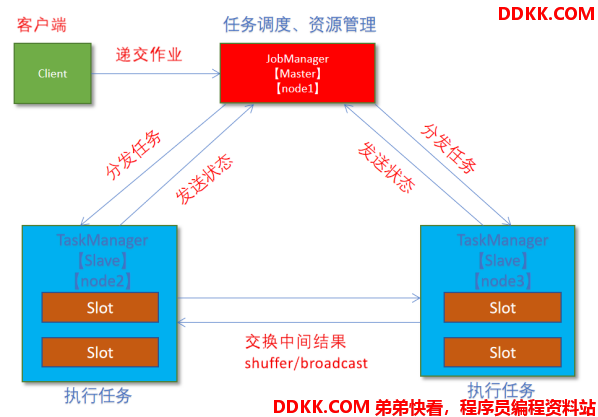
- client客户端提交任务给JobManager
- JobManager负责申请任务运行所需要的资源并管理任务和资源,
- JobManager分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
2. 操作
2.1. 集群规划
-服务器: node1(Master + Slave): JobManager + TaskManager
-服务器: node2(Slave): TaskManager
-服务器: node3(Slave): TaskManager
2.2. 修改flink-conf.yaml
# 编辑flink-conf.yaml文件
vim /export/server/flink/conf/flink-conf.yaml
# 在flink-conf.yaml文件中修改如下内容
jobmanager.rpc.address: node1
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
# 在flink-conf.yaml文件中配置历史服务器
jobmanager.archive.fs.dir: hdfs://node1:8020/flink/completed-jobs/
historyserver.web.address: node1
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://node1:8020/flink/completed-jobs/
2.3. 修改masters
vim/export/server/flink/conf/masters
node1:8081
2.4. 修改slaves
vim/export/server/flink/conf/workers
node1
node2
node3
2.4. 添加HADOOP_CONF_DIR环境变量
vim/etc/profile
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
2.5. 分发
scp -r /export/server/flink node2:/export/server/flink
scp -r /export/server/flink node3:/export/server/flink
scp /etc/profile node2:/etc/profile
scp /etc/profile node3:/etc/profile
或
for i in {2..3}; do scp -r flink node$i:$PWD; done
2.6. 在所有机器上source环境变量
source /etc/profile
3. 测试
3.1. 启动集群
在node1上执行如下命令
/export/server/flink/bin/start-cluster.sh
或者单独启动
/export/server/flink/bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all
/export/server/flink/bin/taskmanager.sh start|start-foreground|stop|stop-all
3.2. 启动历史服务器
/export/server/flink/bin/historyserver.sh start
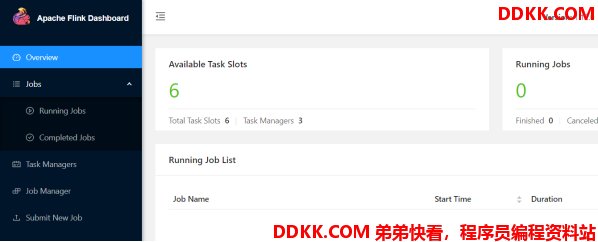
3.3. 访问Flink UI界面或使用jps查看
TaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少
3.4. 执行官方测试案例
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar --input hdfs://node1:8020/wordcount/input/words.txt --output hdfs://node1:8020/wordcount/output/result.txt --parallelism 2
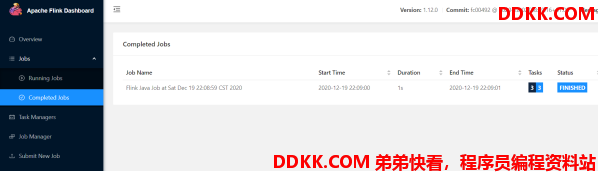
3.5. 查看历史日志
http://node1:50070/explorer.html#/flink/completed-jobs
3.6. 停止Flink集群
/export/server/flink/bin/stop-cluster.sh