1. FlinkSQL整合Hive介绍
官网介绍:Apache Flink 1.12 Documentation: Hive
知乎案例:Flink集成Hive之快速入门--以Flink1.12为例 - 知乎
使用Hive构建数据仓库已经成为了比较普遍的一种解决方案。目前,一些比较常见的大数据处理引擎,都无一例外兼容Hive。Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在Flink1.10版本中,标志着对 Blink的整合宣告完成,对 Hive 的集成也达到了生产级别的要求。值得注意的是,不同版本的Flink对于Hive的集成有所差异,接下来将以最新的Flink1.12版本为例,实现Flink集成Hive。
2. 集成Hive的基本方式
2.1. 持久化元数据
Flink利用 Hive 的 MetaStore 作为持久化的 Catalog,我们可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。例如,我们可以使用HiveCatalog将其 Kafka的数据源表存储在 Hive Metastore 中,这样该表的元数据信息会被持久化到Hive的MetaStore对应的元数据库中,在后续的 SQL 查询中,我们可以重复使用它们。
2.2. 利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive表。不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
3. 准备工作
1、添加hadoop_classpath,在 /etc/profile 环境变量中增加如下配置
编辑/etc/profile文件
vim /etc/profile
增加如下配置
export HADOOP_CLASSPATH=hadoop classpath
刷新配置
source /etc/profile
2、下载jar并上传至flink/lib目录
下载网址:Apache Flink 1.12 Documentation: Hive
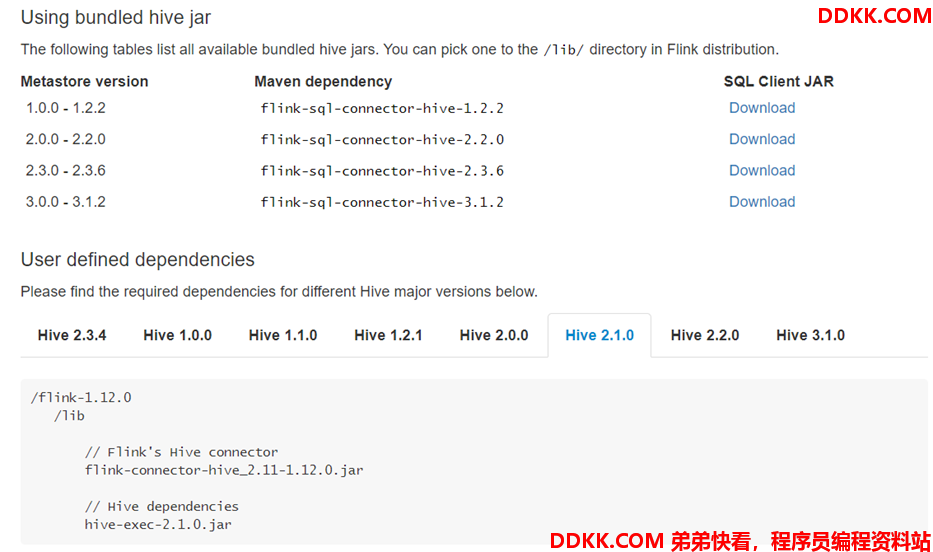
3、修改hive配置
编辑如下文件
vim /export/server/hive/conf/hive-site.xml
在其中增加如下配置
<property
<namehive.metastore.uris</name
<valuethrift://node3:9083</value
</property
4、重新启动hive元数据服务
nohup /export/server/hive/bin/hive --service metastore &
4. SQL CLI
1、修改flinksql集群的sql-client-defaults.yaml配置文件,并新增如下配置
修改如下配置文件
vim /export/server/flink/conf/sql-client-defaults.yaml
增加如下配置
catalogs:
- name: myhive
type: hive
hive-conf-dir: /export/server/hive/conf
default-database: default
2、启动flink集群
/export/server/flink/bin/start-cluster.sh
3、启动flink-sql客户端
/export/server/flink/bin/sql-client.sh embedded
4、执行如下sql
show catalogs;
use catalog myhive;
show tables;
select * from person;
5. 代码演示
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* Desc
*/
public class HiveDemo {
public static void main(String[] args){
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "./conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//注册catalog
tableEnv.registerCatalog("myhive", hive);
//使用注册的catalog
tableEnv.useCatalog("myhive");
//向Hive表中写入数据
String insertSQL = "insert into person select * from person";
TableResult result = tableEnv.executeSql(insertSQL);
System.out.println(result.getJobClient().get().getJobStatus());
}
}