1. FlinkCDC1.x中存在的痛点
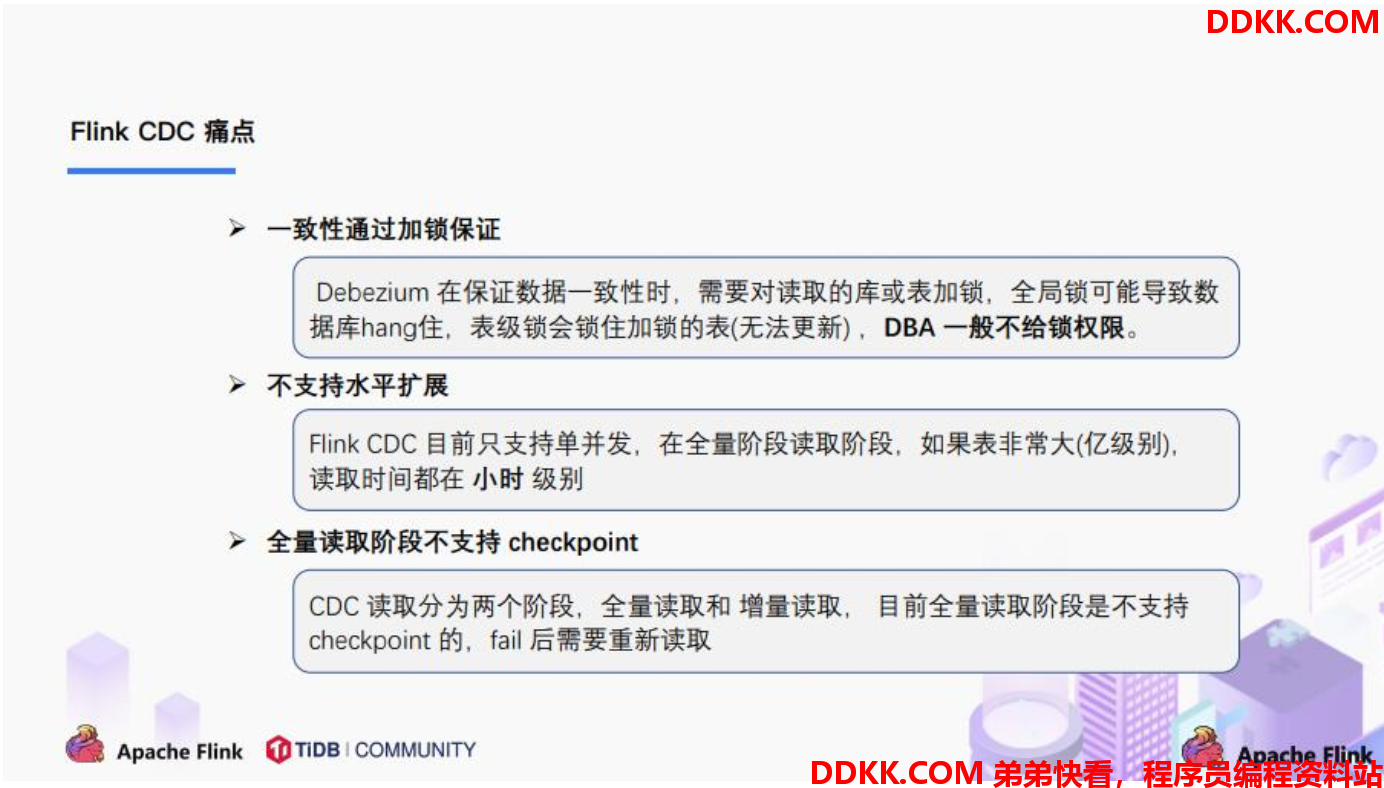
2. FlinkCDC2.x的设计目标

3. FlinkCDC2.x的设计实现
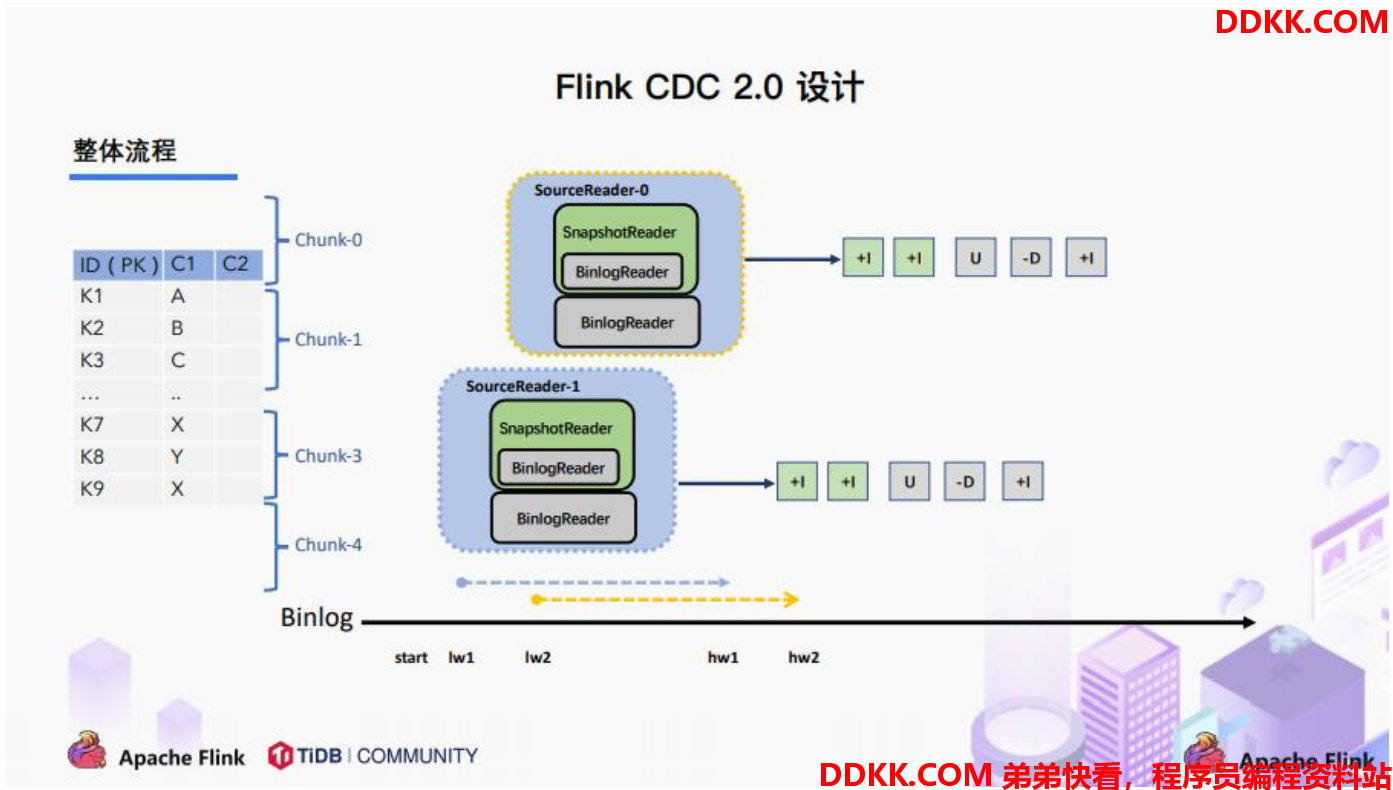
3.1. 整体概览
在对于有主键的表做初始化模式,整体的流程主要分为 5 个阶段:
1、 Chunk切分;
2、 Chunk分配;(实现并行读取数据&CheckPoint);
3、 Chunk读取;(实现无锁读取);
4、 Chunk汇报;
5、 Chunk分配;
3.2. Chunk切分
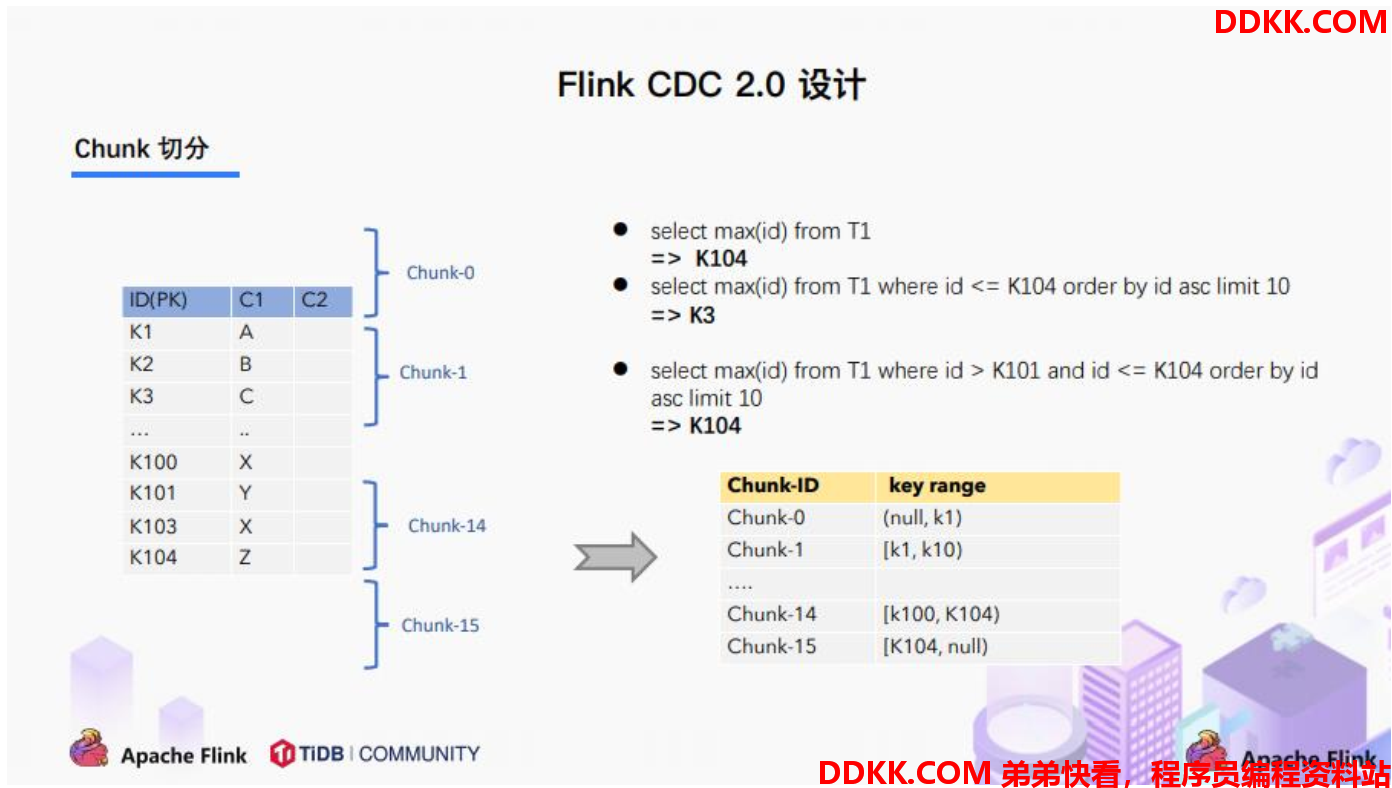
根据Netflix DBlog 的论文中的无锁算法原理,对于目标表按照主键进行数据分片,设置每个切片的区间为左闭右开或者左开右闭来保证数据的连续性。
3.3. Chunk分配
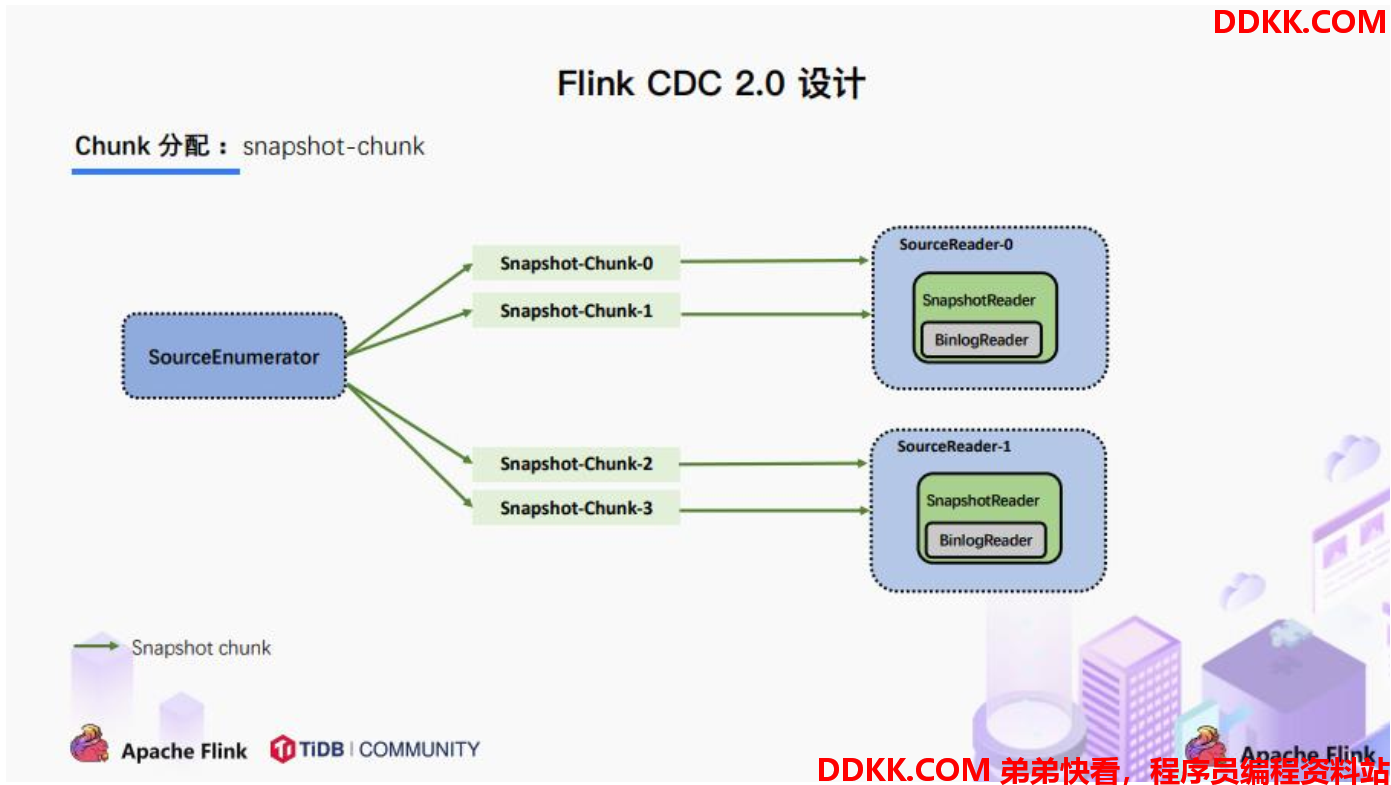
将划分好的 Chunk 分发给多个 SourceReader,每个 SourceReader 读取表中的一部分数据, 实现了并行读取的目标。
同时在每个 Chunk 读取的时候可以单独做 CheckPoint,某个 Chunk 读取失败只需要单独执行该 Chunk 的任务,而不需要像 1.x 中失败了只能从头读取。
若每个SourceReader 保证了数据一致性,则全表就保证了数据一致性。
3.4. Chunk读取
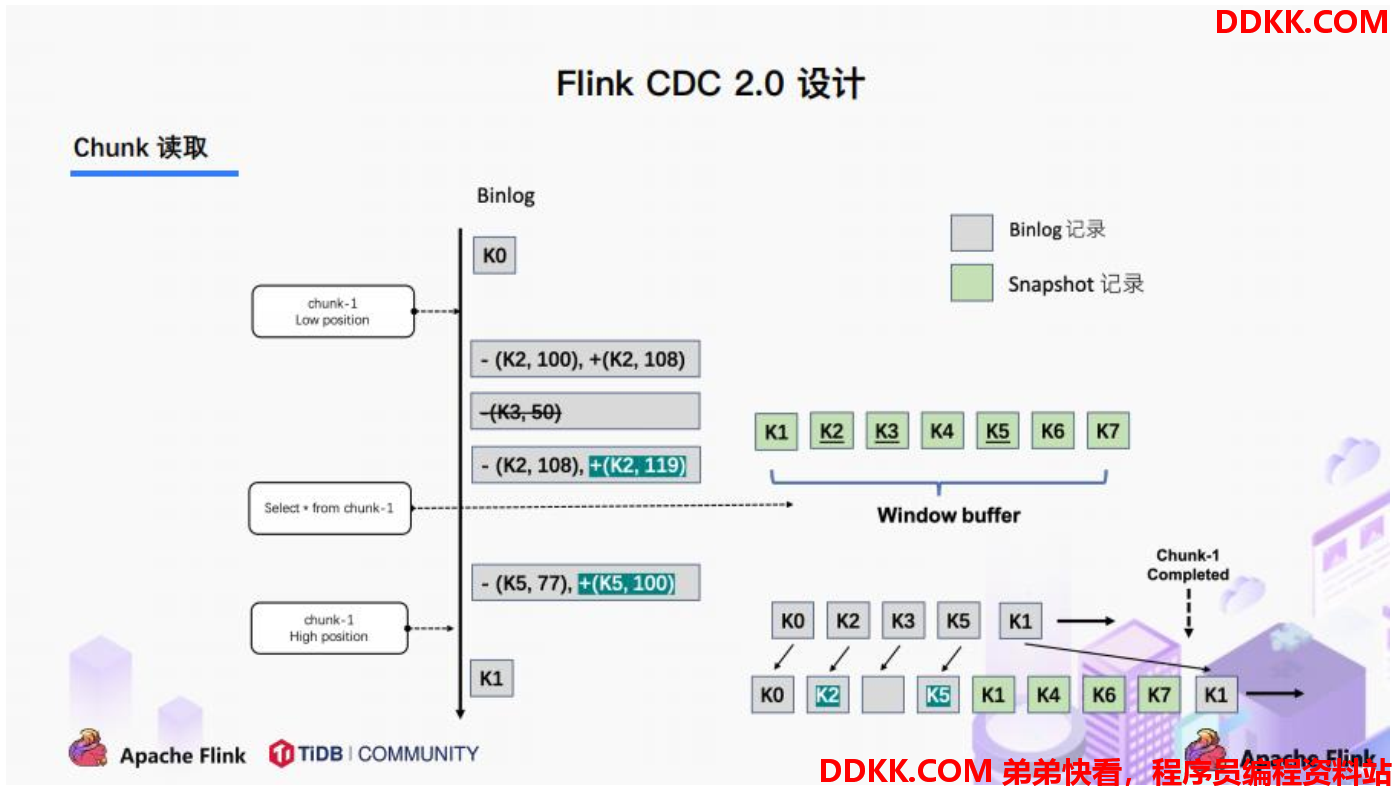
读取可以分为 5 个阶段:
1、 SourceReader读取表数据之前先记录当前的Binlog位置信息记为低位点;
2、 SourceReader将自身区间内的数据查询出来并放置在buffer中;
3、 查询完成之后记录当前的Binlog位置信息记为高位点;
4、 在增量部分消费从低位点到高位点的Binlog;
5、 根据主键,对buffer中的数据进行修正并输出;
通过以上5个阶段可以保证每个Chunk最终的输出就是在高位点时该Chunk中最新的数据,但是目前只是做到了保证单个 Chunk 中的数据一致性。
3.5. Chunk汇报
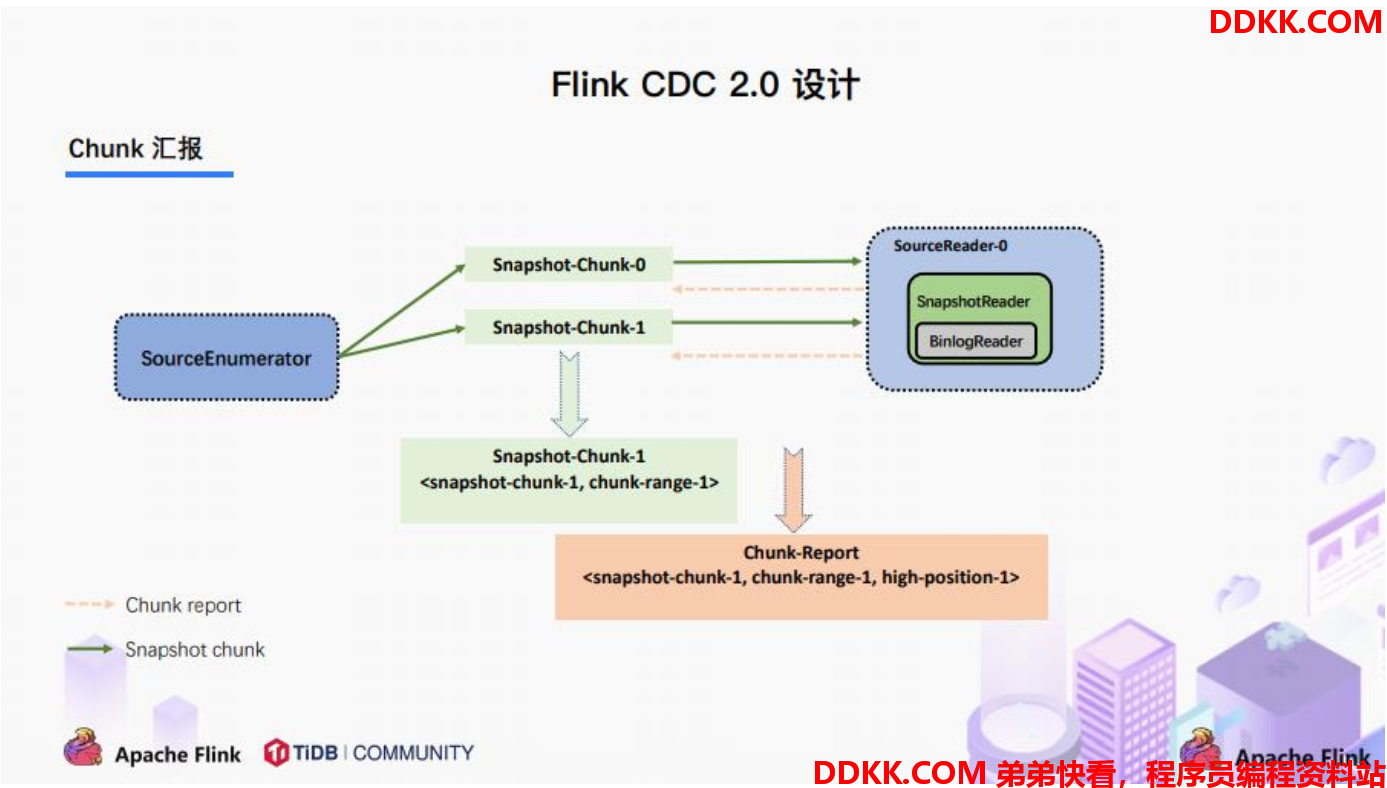
在Snapshot Chunk 读取完成之后,有一个汇报的流程,如上图所示,即 SourceReader 需要将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。
3.6. Chunk分配
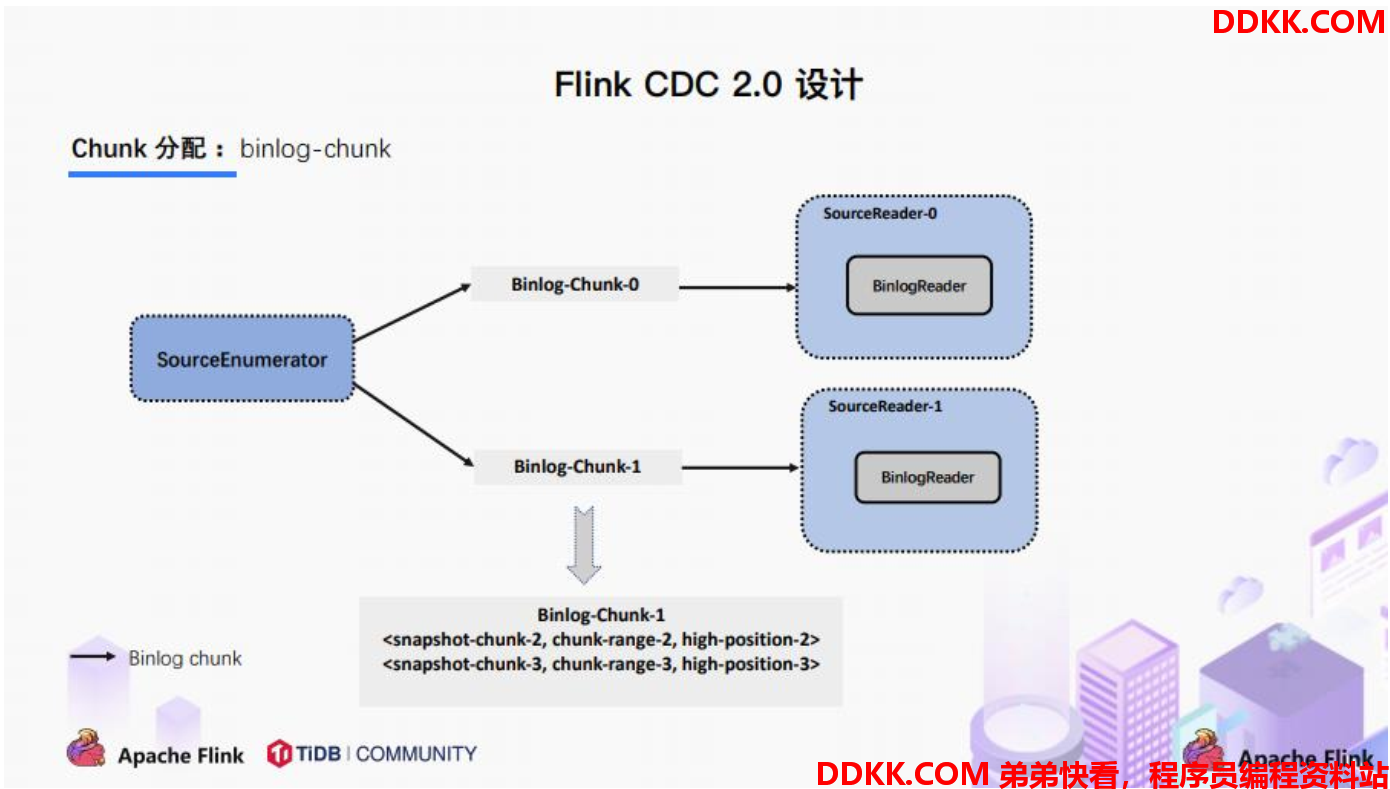
FlinkCDC 是支持全量+增量数据同步的,在 SourceEnumerator 接收到所有的 SnapshotChunk 完成信息之后,还有一个消费增量数据(Binlog) 的任务,此时是通过下发 Binlog Chunk给任意一个 SourceReader 进行单并发读取来实现的。
4. FlinkCDC2.x的核心原理分析
4.1. Binlog Chunk 中开始读取位置源码
MySqlHybridSplitAssigner
private MySqlBinlogSplit createBinlogSplit()\ {
final List < MySqlSnapshotSplit > assignedSnapshotSplit = snapshotSplitAssigner
.getAssignedSplits()
.values()
.stream()
.sorted(Comparator.comparing(MySqlSplit::splitId))
.collect(Collectors.toList());
Map < String, BinlogOffset > splitFinishedOffsets = snapshotSplitAssigner.getSplitFinishedOffsets();
final List < FinishedSnapshotSplitInfo > finishedSnapshotSplitInfos = new ArrayList < > ();
final Map < TableId, TableChanges.TableChange > tableSchemas = new HashMap < > ();
BinlogOffset minBinlogOffset = BinlogOffset.INITIAL\ _OFFSET;
for (MySqlSnapshotSplit split: assignedSnapshotSplit)\ {
// find the min binlog offset
BinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());
if (binlogOffset.compareTo(minBinlogOffset) < 0)\ {
minBinlogOffset = binlogOffset;
}
finishedSnapshotSplitInfos.add(
new FinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));
tableSchemas.putAll(split.getTableSchemas());
\
}
final MySqlSnapshotSplit lastSnapshotSplit = assignedSnapshotSplit.get(assignedSnapshotSplit.size() - 1).asSnapshotSplit();
return new MySqlBinlogSplit(
BINLOG\ _SPLIT\ _ID,
lastSnapshotSplit.getSplitKeyType(),
minBinlogOffset,
BinlogOffset.NO\ _STOPPING\ _OFFSET,
finishedSnapshotSplitInfos,
tableSchemas
);
}
4.2. 读取低位点到高位点之间的Binlog
BinlogSplitReader
/**
* Returns the record should emit or not.
*
* <p>The watermark signal algorithm is the binlog split reader only sends the binlog event
* that
* belongs to its finished snapshot splits. For each snapshot split, the binlog event is valid
* since the offset is after its high watermark.
*
* <pre> E.g: the data input is :
* snapshot-split-0 info : [0, 1024) highWatermark0
* snapshot-split-1 info : [1024, 2048) highWatermark1
* the data output is:
* only the binlog event belong to [0, 1024) and offset is after highWatermark0
* should send,
* only the binlog event belong to [1024, 2048) and offset is after highWatermark1 should
* send.
* </pre>
*/
private boolean shouldEmit(SourceRecord sourceRecord) {
if (isDataChangeRecord(sourceRecord)) {
TableId tableId = getTableId(sourceRecord);
BinlogOffset position = getBinlogPosition(sourceRecord);
// aligned, all snapshot splits of the table has reached max highWatermark
if (position.isAtOrBefore(maxSplitHighWatermarkMap.get(tableId))) {
return true;
}
Object[] key =
getSplitKey(
currentBinlogSplit.getSplitKeyType(),
sourceRecord,
statefulTaskContext.getSchemaNameAdjuster()
);
for (FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)) {
if (RecordUtils.splitKeyRangeContains(
key, splitInfo.getSplitStart(), splitInfo.getSplitEnd())
&& position.isAtOrBefore(splitInfo.getHighWatermark())) {
return true;
}
}
// not in the monitored splits scope, do not emit
return false;
}
// always send the schema change event and signal event
// we need record them to state of Flink
return true;
}
注 :此博文为介绍FlinkCDC2.x的相关知识,对应FlinkCDC的详细使用可以查看Flink(58):Flink之FlinkCDC(上)
注 :此博文中的相关内容和图片截取至网上Flink相关公开内容