1. 原理
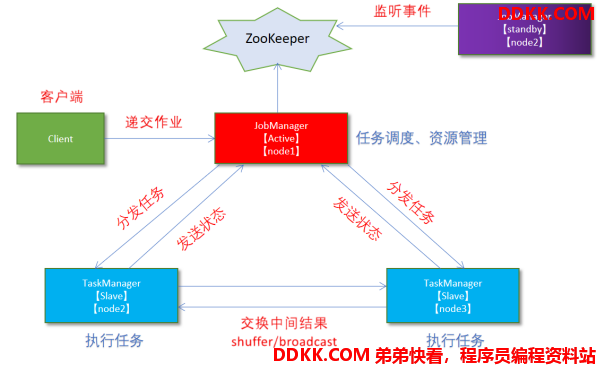
从之前的架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF,single point of failure)。JobManager 肩负着任务调度以及资源分配,一旦 JobManager 出现意外,其后果可想而知。
在Zookeeper 的帮助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
2. 操作
步骤一:集群规划
-服务器: node1(Master + Slave): JobManager + TaskManager
-服务器: node2(Master + Slave): JobManager + TaskManager
-服务器: node3(Slave): TaskManager
步骤二:启动Zookeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh start
步骤三:启动HDFS
/export/serves/hadoop/sbin/start-dfs.sh
步骤四:停止Flink集群
/export/server/flink/bin/stop-cluster.sh
步骤五:修改flink-conf.yaml
vim/export/server/flink/conf/flink-conf.yaml
增加如下内容:
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://node1:8020/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://node1:8020/flink/ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
配置解释:
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://node1:8020/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://node1:8020/flink/ha/
# 配置ZK集群地址
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
步骤六:修改masters
vim/export/server/flink/conf/masters
node1:8081
node2:8081
步骤七:同步
scp -r /export/server/flink/conf/flink-conf.yaml node2:/export/server/flink/conf/
scp -r /export/server/flink/conf/flink-conf.yaml node3:/export/server/flink/conf/
scp -r /export/server/flink/conf/masters node2:/export/server/flink/conf/
scp -r /export/server/flink/conf/masters node3:/export/server/flink/conf/
步骤八:修改node2上的flink-conf.yaml
vim/export/server/flink/conf/flink-conf.yaml
jobmanager.rpc.address: node2
步骤九:重新启动Flink集群,node1上执行
/export/server/flink/bin/stop-cluster.sh
/export/server/flink/bin/start-cluster.sh
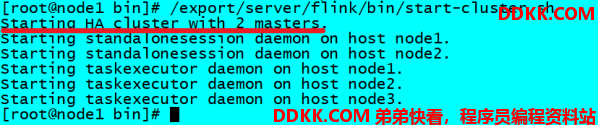
步骤十:使用jps命令查看
发现没有Flink相关进程被启动
步骤十一:查看日志
cat/export/server/flink/log/flink-root-standalonesession-0-node1.log
发现如下错误:
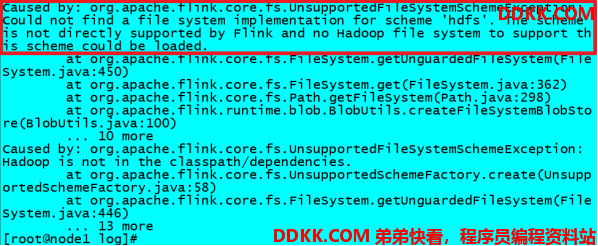
因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar
步骤十二:下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作

步骤十三:放入lib目录并分发
cd/export/server/flink/lib
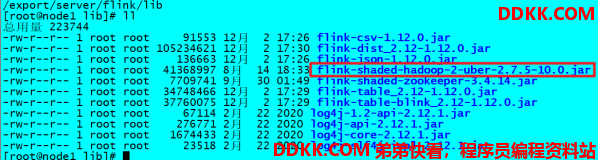
分发:
for i in {2..3}; do scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar node$i:$PWD; done
步骤十四:重新启动Flink集群并在所有机器上使用jps命令查看
# 在node1上执行
/export/server/flink/bin/start-cluster.sh
# 在所有机器上执行
jps
3. 测试
步骤一:访问WebUI
http://node1:8081/#/job-manager/config
http://node2:8081/#/job-manager/config
步骤二:执行wc
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
步骤三:kill掉其中一个master
步骤四:重新执行wc,还是可以正常执行
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
步骤五:停止集群
/export/server/flink/bin/stop-cluster.sh