1. Hadoop概述
1.1 Hadoop是什么
Hadoop 是一个由Apache基金会所开发的分布式系统基础架构
主要解决海量数据的存储和海量数据的分析计算问题
广义上来说,Hadoop 通常是指一个更广泛的概念——Hadoop生态圈
1.2 Hadoop发展简史
Hadoop 是 Apache Lucene 创始人 Doug Cutting 创建的。最早起源于 Nutch,它是 Lucene 的子项目。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
2003 年 Google 发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
2004 年 Google 发表论文向全世界介绍了谷歌版的MapReduce系统。
同时期,以谷歌的论文为基础,Nutch 的开发人员完成了相应的开源实现 HDFS 和 MAPREDUCE,并从 Nutch 中剥离成为独立项目 HADOOP,到 2008 年 1 月,HADOOP 成为 Apache 顶级项目,迎来了它的快速发展期。
2006 年 Google 发表了论文是关于BigTable的,这促使了后来的 Hbase 的发展。
因此,Hadoop 及其生态圈的发展离不开 Google 的贡献。
1.2 Hadoop三大发行版本
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks
免费开源版本 Apache,Apache版本是最原始(最基础)的版本,对于入门学习最好——2006年
优点:
拥有全世界的开源贡献者,代码更新迭代版本比较快
缺点:
版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到
免费开源版本HortonWorks,Hortonworks 文档最好,对应产品HDP(ambari)(Hortonworks 现已被 Cloudera 公司收购,推出新的品牌CDP)——2011年
软件收费版本 Cloudera,Cloudera 内部集成了很多大数据框架,对应产品CDH——2008年
cloudera 主要是美国一家大数据公司在 apache 开源 hadoop 的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题
1、ApacheHadoop;
下载地址:https://hadoop.apache.org/releases.html
2、ClouderaHadoop;
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
3、HortonworksHadoop;
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
1.3 Hadoop优势
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
高容错性: 能够自动将失败的任务重新分配。
成本低:Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
1.4 Hadoop的组成
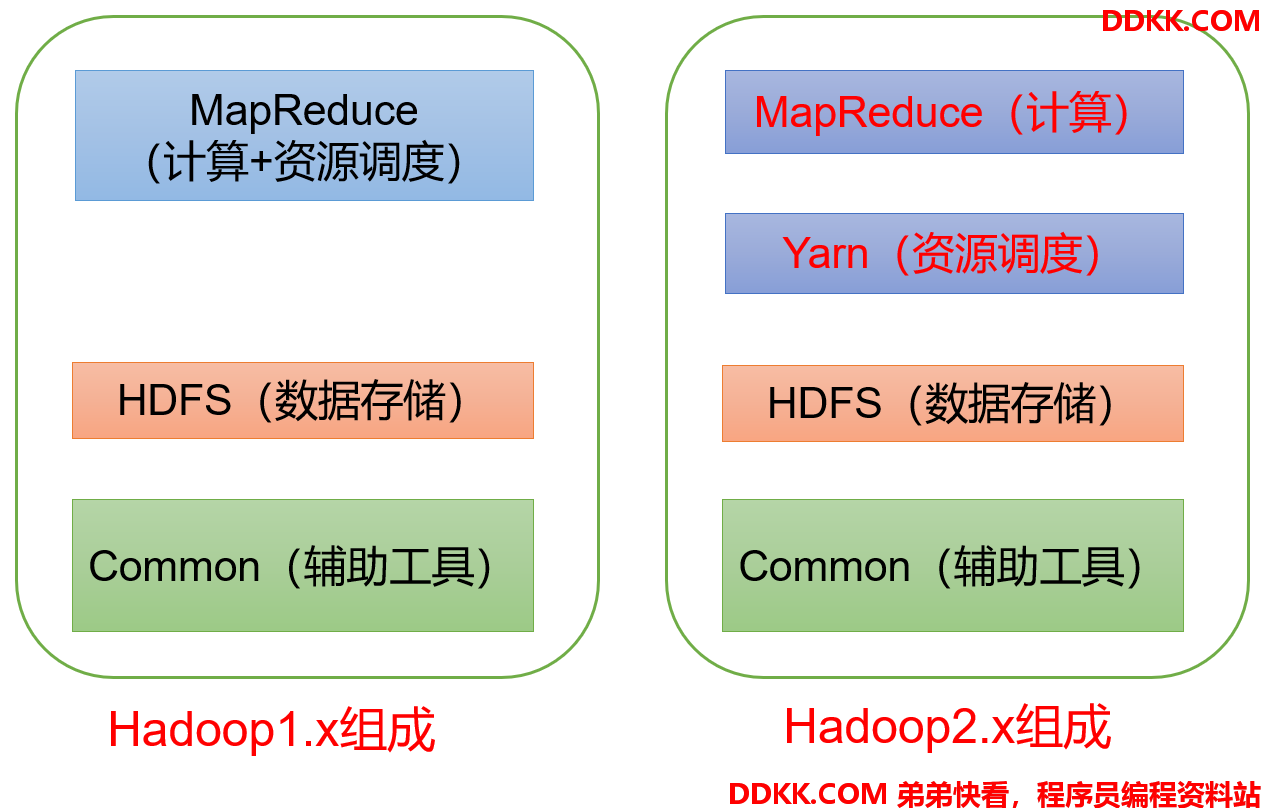
1.4.1 Hadoop1.x、2.x、3.x区别
在Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。
Hadoop3.x 在组成上没有变化(3.x 的新特性后面再开新章节单独说)。
1.4.2 HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统,用来解决海量数据存储的问题。
1、 NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等;
2、 DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验;
3、 SecondaryNameNode(2nm):每隔一段时间对NameNode元数据备份;
1.4.3 YARN架构概述
Yet Another Resource Negotiator 简称YARN,另一种资源协调者,是Hadoop的资源管理器,用来解决资源任务调度的问题。
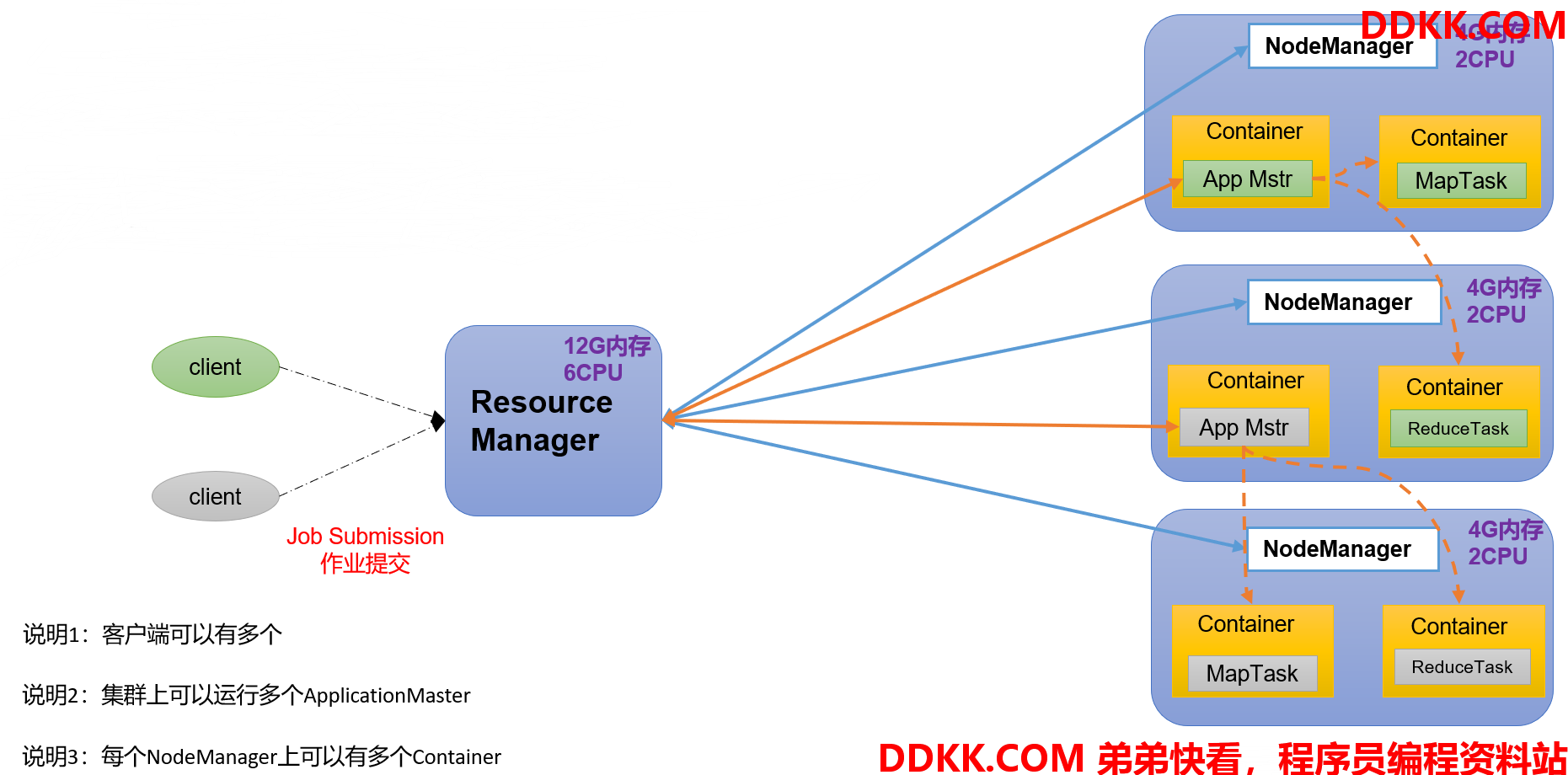
1、 ResourceManager(RM):整个集群资源(内存、CPU等)的老大;
2、 NodeManager(NM):单个节点服务器资源老大;
3、 ApplicationMaster(AM):单个任务运行的老大;
4、 Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等;
1.4.4 MapReduce架构概述
MapReduce 是一个分布式运算编程框架,将计算过程分为两个阶段:Map 和 Reduce,用来解决海量数据计算的问题。
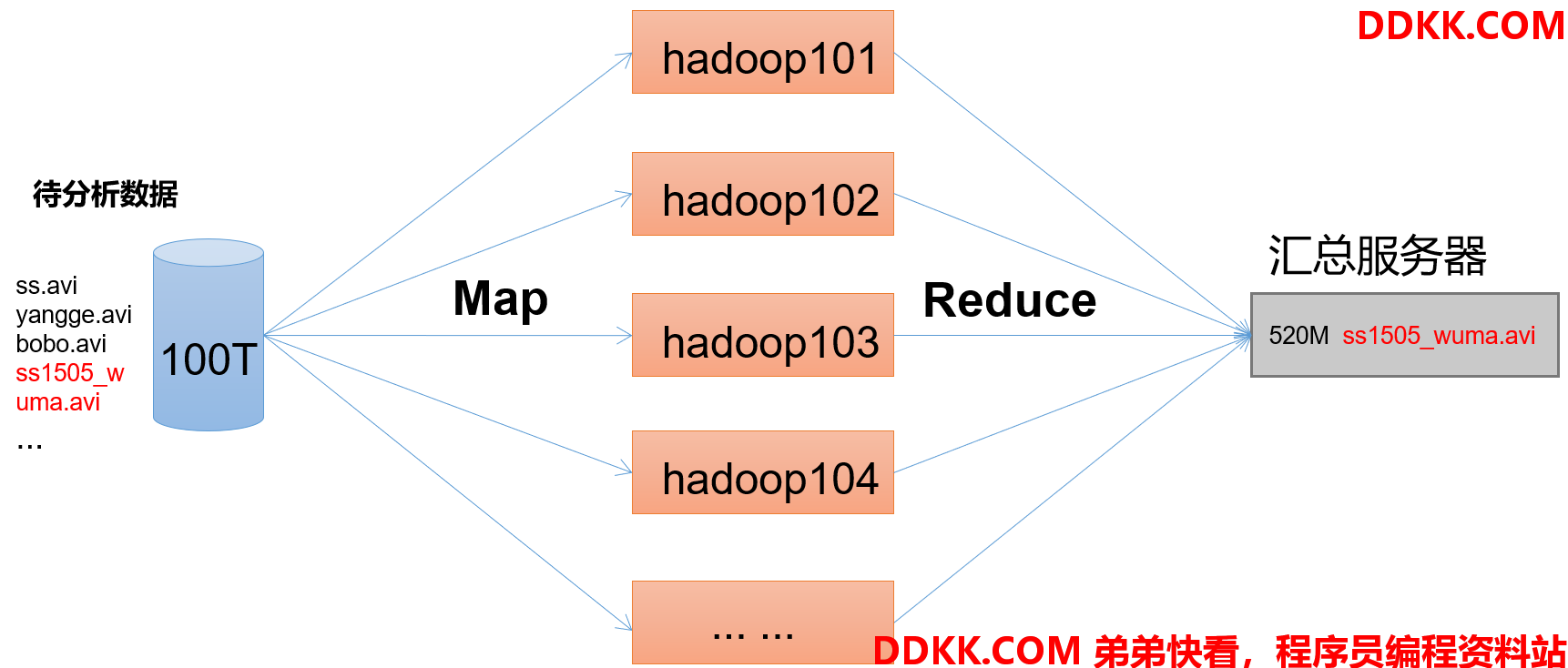
1、 Map阶段并行处理输入数据;
2、 Reduce阶段对Map结果进行汇总;
1.4.5 HDFS、YARN、MapReduce三者关系
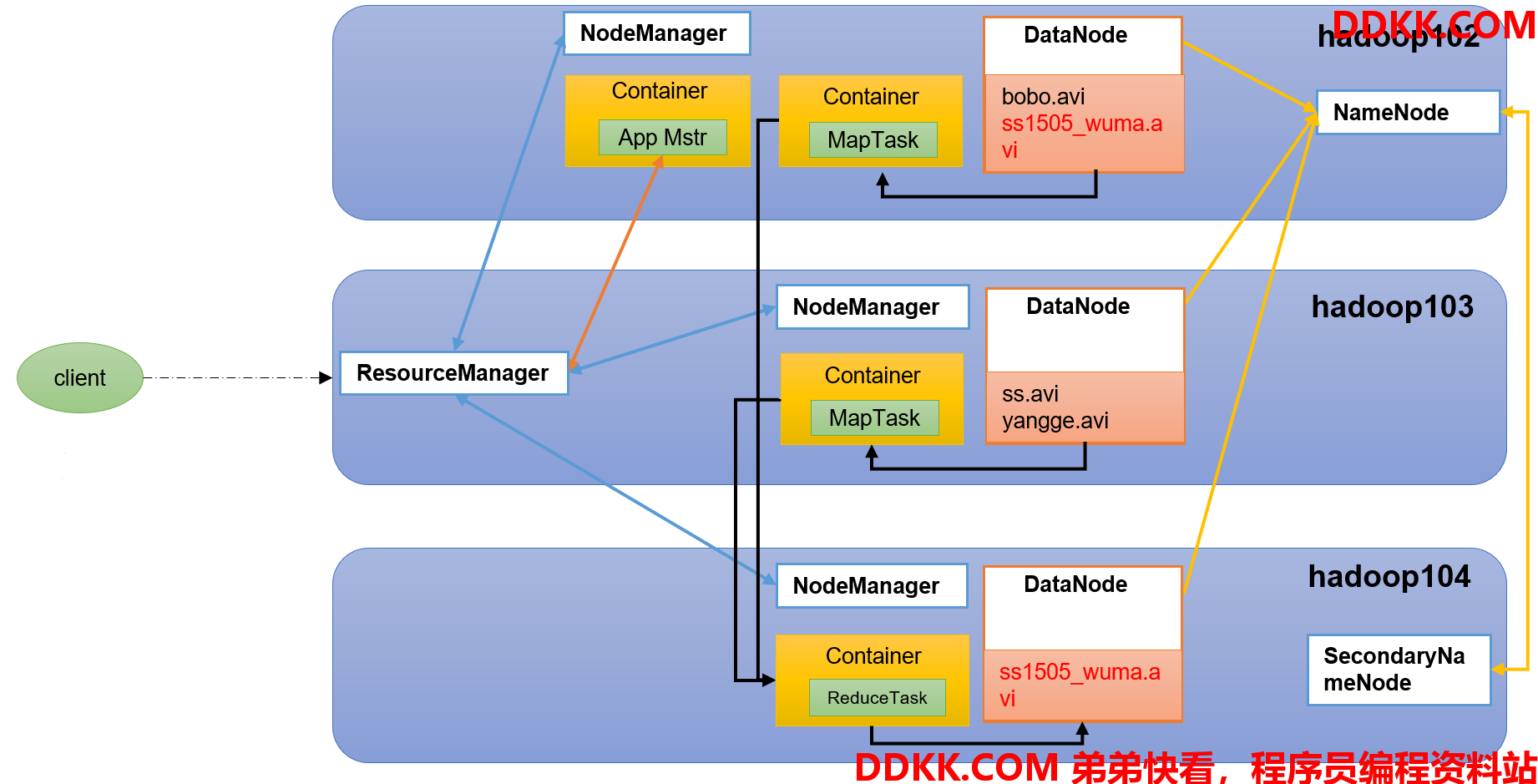
当下的 Hadoop 已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 Hadoop 是很好的补充或者更高层的抽象。比如:
| 框架 | 用途 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式运算程序开发框架 |
| ZooKeeper | 分布式协调服务基础组件 |
| HIVE | 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作 |
| FLUME | 日志数据采集框架 |
| oozie | 工作流调度框架 |
| Sqoop | 工作流调度框架 |
| Impala | 基于hive的实时sql查询分析 |
| Mahout | 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
东西比较多,博主后面再慢慢更新这些框架的详细介绍和用法。
1.5 Hadoop运行模式
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式(standalone mode): 单机运行,仅 1 个机器运行1个java进程,主要用于调试
- 伪分布式模式(Pseudo-Distributed mode): 也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境,主要用于调试
- 完全分布式模式/集群模式(Cluster mode): 多台服务器组成分布式环境,生产环境使用
2. Hadoop的搭建
2.1 集群部署
完全分布式模式部署教程:《Hadoop3.x在centos上的完全分布式部署(包括免密登录、集群测试、历史服务器、日志聚集、常用命令、群起脚本)》
2.2 安装目录结构说明
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
2.3 Hadoop配置文件详解
-
hadoop-env.sh
-
文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME 是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
-
core-site.xml
-
Hadoop 的核心配置文件,有默认的配置项 core-default.xml。
-
core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
-
hdfs-site.xml
-
HDFS 的核心配置文件,主要配置 HDFS 相关参数,有默认的配置项 hdfs-default.xml。
-
hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
-
mapred-site.xml
-
MapReduce 的核心配置文件,Hadoop 默认只有一个模板文件 mapred-site.xml.template,需要使用该文件复制出来一份 mapred-site.xml 文件
-
yarn-site.xml
-
YARN 的核心配置文件
-
workers
-
workers文件里面记录的是集群主机名。一般有以下两种作用:
- 配合一键启动脚本如 start-dfs.sh、stop-yarn.sh 用来进行集群启动。这时候 slaves 文件里面的主机标记的就是从节点角色所在的机器
- 可以配合 hdfs-site.xml 里面 dfs.hosts 属性形成一种白名单机制。dfs.hosts 指定一个文件,其中包含允许连接到 NameNode 的主机列表。必须指定文件的完整路径名,那么所有在 workers中 的主机才可以加入的集群中。如果值为空,则允许所有主机。
3. HDFS基准测试
实际生产环境当中,Hadoop 的环境搭建完成之后,第一件事情就是进行压力测试,测试 Hadoop 集群的读取和写入速度,测试网络带宽是否足够等一些基准测试。
3.1 测试写入速度
向HDFS 文件系统中写入数据,10 个文件,每个文件 10MB,文件存放到/benchmarks/TestDFSIO中。
1、 执行下面命令,启动写入基准测试;
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
1、 MapReduce程序运行成功后,就可以查看测试结果了;

可以看到目前虚拟机的 IO 吞吐量为:3.92MB/s
3.2 测试读取速度
测试 HDFS 的读取文件性能,在 HDFS 文件系统中读入 10 个文件,每个文件 10M。
1、 执行下面命令,启动读取基准测试;
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
1、 查看读取结果;

可以看到读取的吞吐量为:53.85MB/s
3.3 清除测试数据
测试期间,会在 HDFS 集群上创建/benchmarks目录,测试完毕后,我们可以清理该目录。
1、hdfsdfs-ls-R/benchmarks;
 2、 执行清理命令;
2、 执行清理命令;
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -clean
1、 删除命令会将/benchmarks目录中内容删除;
