1. Hadoop Archive归档
HDFS 并不擅长存储小文件,因为每个文件最少一个 block,每个 block 的元数据都会在 NameNode 占用内存,如果存在大量的小文件,它们会吃掉 NameNode 节点的大量内存。如下所示,模拟小文件场景:
[hadoop@hadoop1 input]$ hadoop fs -mkdir /smallfile
[hadoop@hadoop1 input]$ echo 1 > 1.txt
[hadoop@hadoop1 input]$ echo 2 > 2.txt
[hadoop@hadoop1 input]$ echo 3 > 3.txt
[hadoop@hadoop1 input]$ hadoop fs -put 1.txt 2.txt 3.txt /smallfile
Hadoop Archives可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
1.1 创建Archive
Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>
其中-archiveName是指要创建的存档的名称。比如test.har,archive 的名字的扩展名应该是*.har。 -p参数指定文件存档文件(src)的相对路径。
举个例子:-p /foo/bar a/b/c e/f/g,这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
例如:如果你只想存档一个目录/smallfile下的所有文件:
hadoop archive -archiveName test.har -p /smallfile /outputdir
这样就会在/outputdir目录下创建一个名为test.har的存档文件。
**注意:**Archive 归档是通过 MapReduce 程序完成的,需要启动 YARN 集群。
1.2 查看Archive
1.2.1 查看归档之后的样子
首先我们来看下创建好的 har 文件。使用如下的命令:
hadoop fs -ls /outputdir/test.har

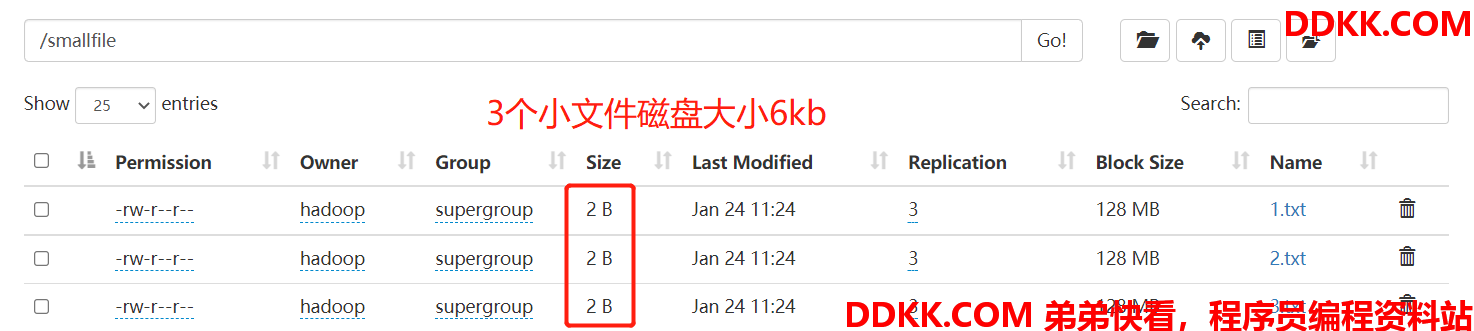
这里可以看到 har 文件包括:两个索引文件,多个 part 文件(本例只有一个)以及一个标识成功与否的文件。part文件是多个原文件的集合, 通过 index 文件可以去找到原文件。
例如上述的三个小文件 1.txt 2.txt 3.txt 内容分别为 1,2,3。进行 archive 操作之后,三个小文件就归档到 test.har 里的 part-0 一个文件里。

1.2.2 查看归档之前的样子
在查看 har 文件的时候,如果没有指定访问协议,默认使用的就是 hdfs://,此时所能看到的就是归档之后的样子。
此外,Archive 还提供了自己的 har uri 访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
Hadoop Archives 的 URI 是:
har://scheme-hostname:port/archivepath/fileinarchive
scheme-hostname 格式为hdfs-域名:端口

hadoop fs -ls har://hdfs-node1:8020/outputdir/test.har/
hadoop fs -ls har:///outputdir/test.har
hadoop fs -cat har:///outputdir/test.har/1.txt
1.3 提取Archive
按顺序解压存档(串行):
hadoop fs -cp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
hadoop fs -mkdir /smallfile1
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
hadoop fs -ls /smallfile1

要并行解压存档,请使用 DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
hadoop distcp har:///outputdir/test.har/* /smallfile2
1.4 Archive使用注意事项
1、 Hadooparchives是特殊的档案格式一个Hadooparchive对应一个文件系统目录Hadooparchive的扩展名是*.har;
2、 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令;
3、 创建archive文件要消耗和原文件一样多的硬盘空间;
4、 archive文件不支持压缩,尽管archive文件看起来像已经被压缩过;
5、 archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日;
6、 当创建archive时,源文件不会被更改或删除;
2. Sequence File
2.1 Sequence File介绍
Sequence File是 Hadoop API 提供的一种二进制文件支持。这种二进制文件直接将<key, value>键值对序列化到文件中。

2.2 Sequence File优缺点
-
优点
-
二级制格式存储,比文本文件更紧凑。
-
支持不同级别压缩(基于 Record 或 Block 压缩)。
-
文件可以拆分和并行处理,适用于 MapReduce。
-
缺点
-
二进制格式文件不方便查看。
-
特定于 hadoop,只有 Java API 可用于与之件进行交互。尚未提供多语言支持。
2.3 Sequence File格式
Hadoop Sequence File 是一个由二进制键/值对组成的。根据压缩类型,有 3 种不同的 Sequence File 格式:未压缩格式、record压缩格式、block压缩格式。
Sequence File 由一个header和一个或多个record组成。以上三种格式均使用相同的 header 结构,如下所示:

前3 个字节为 SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如 SEQ4 或 SEQ6)。Header 中其他也包括 key、value class 名字、 压缩细节、metadata、Sync marker。Sync Marker 同步标记,用于可以读取任意位置的数据。
2.3.1 未压缩格式
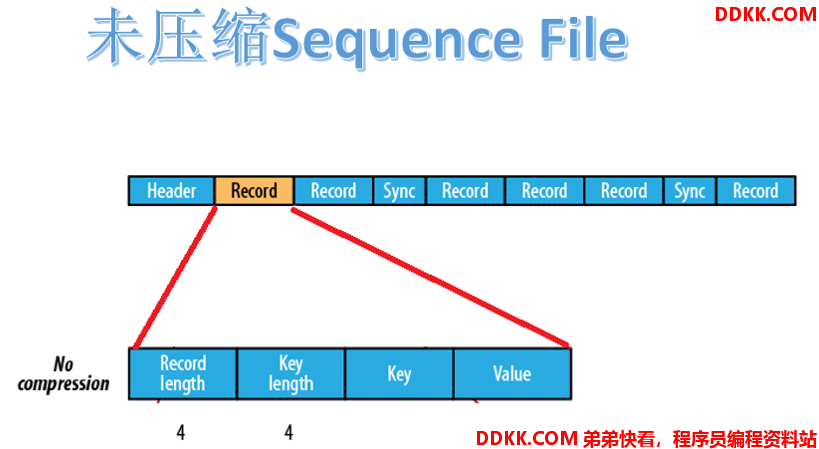
未压缩的 Sequence File 文件由 header、record、sync 三个部分组成。其中 record 包含了 4 个部分:record length(记录长度)、key length(键长)、key、value。
每隔几个 record(100字节左右)就有一个同步标记。
2.3.2 基于record压缩格式
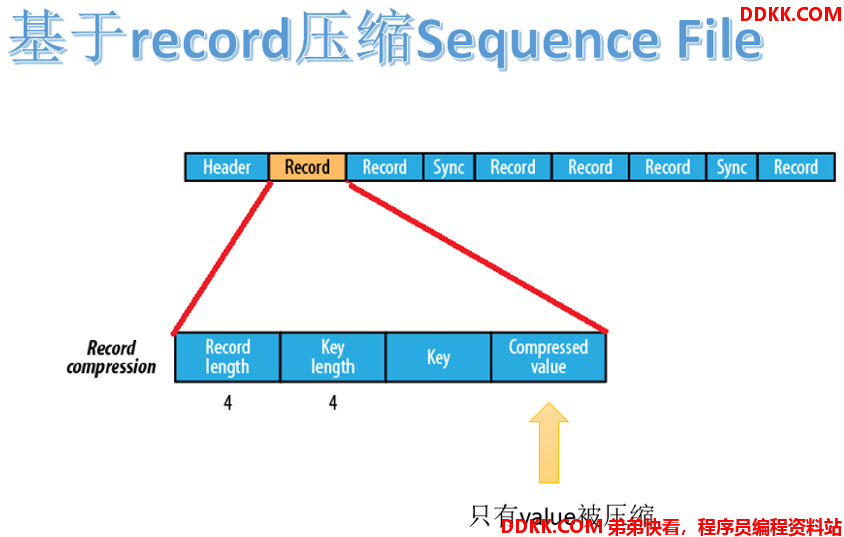
基于 record 压缩的 Sequence File 文件由 header、record、sync 三个部分组成。其中 record 包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
每隔几个 record(100字节左右)就有一个同步标记。
2.3.3 基于block压缩格式
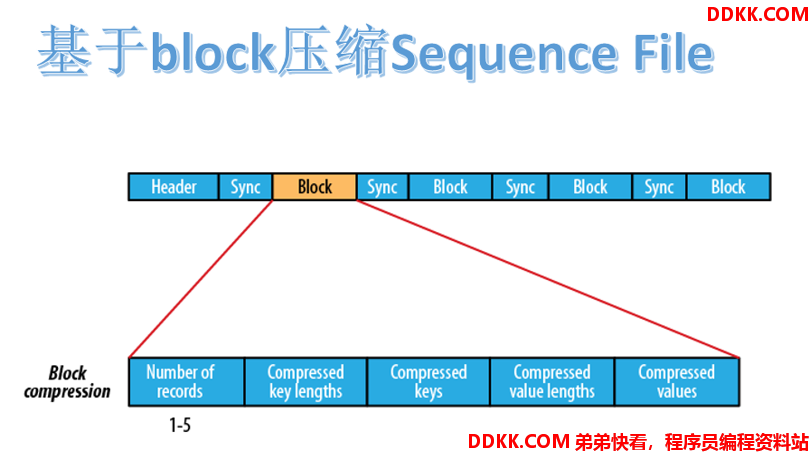
基于 block 压缩的 Sequence File 文件由 header、block、sync 三个部分组成。
block指的是record block,可以理解为多个record记录组成的块。注意,这个 block 和 HDFS 中分块存储的 block(128M)是不同的概念。
Block 中包括:record 条数、压缩的 key 长度、压缩的 keys、压缩的 value 长度、压缩的 values。每隔一个 block 就有一个同步标记。
block 压缩比 record 压缩提供更好的压缩率。使用 Sequence File 时,通常首选块压缩。
2.4 Sequence File文件读写
2.4.1 开发环境构建
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
2.4.2 SequenceFileWrite
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
public class SequenceFileWrite {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws Exception {
//设置客户端运行身份 以root去操作访问HDFS
System.setProperty("HADOOP_USER_NAME","hadoop");
//Configuration 用于指定相关参数属性
Configuration conf = new Configuration();
//sequence file key、value
IntWritable key = new IntWritable();
Text value = new Text();
//构造Writer参数属性
SequenceFile.Writer writer = null;
CompressionCodec Codec = new GzipCodec();
SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(new Path("hdfs://192.168.68.101:8020/seq.out"));
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(value.getClass());
SequenceFile.Writer.Option optCom = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD,Codec);
try {
writer = SequenceFile.createWriter( conf, optPath, optKey, optVal, optCom);
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
运行结果:

最终输出的文件如下:

2.4.3 SequenceFileRead
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
public class SequenceFileRead {
public static void main(String[] args) throws IOException {
//设置客户端运行身份 以root去操作访问HDFS
System.setProperty("HADOOP_USER_NAME","hadoop");
//Configuration 用于指定相关参数属性
Configuration conf = new Configuration();
SequenceFile.Reader.Option option1 = SequenceFile.Reader.file(new Path("hdfs://192.168.68.101:8020/seq.out"));
SequenceFile.Reader.Option option2 = SequenceFile.Reader.length(174);//这个参数表示读取的长度
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(conf,option1,option2);
Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";//是否返回了Sync Mark同步标记
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
运行结果:
2.5 案例:使用Sequence File合并小文件
2.5.1 理论依据
可以使用 Sequence File 对小文件合并,即将文件名作为key,文件内容作为value序列化到大文件中。例如,假设有 10,000 个 100KB 文件,那么我们可以编写一个程序将它们放入单个 Sequence File 中,如下所示,可以在其中使用 filename 作为键,并使用 content 作为值。
2.5.2 具体值
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MergeSmallFilesToSequenceFile {
private Configuration configuration = new Configuration();
private List<String> smallFilePaths = new ArrayList<String>();
//定义方法用来添加小文件的路径
public void addInputPath(String inputPath) throws Exception{
File file = new File(inputPath);
//给定路径是文件夹,则遍历文件夹,将子文件夹中的文件都放入smallFilePaths
//给定路径是文件,则把文件的路径放入smallFilePaths
if(file.isDirectory()){
File[] files = FileUtil.listFiles(file);
for(File sFile:files){
smallFilePaths.add(sFile.getPath());
System.out.println("添加小文件路径:" + sFile.getPath());
}
}else{
smallFilePaths.add(file.getPath());
System.out.println("添加小文件路径:" + file.getPath());
}
}
//把smallFilePaths的小文件遍历读取,然后放入合并的sequencefile容器中
public void mergeFile() throws Exception{
Writer.Option bigFile = Writer.file(new Path("D:\\datasets\\bigfile"));
Writer.Option keyClass = Writer.keyClass(Text.class);
Writer.Option valueClass = Writer.valueClass(BytesWritable.class);
//构造writer
Writer writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);
//遍历读取小文件,逐个写入sequencefile
Text key = new Text();
for(String path:smallFilePaths){
File file = new File(path);
long fileSize = file.length();//获取文件的字节数大小
byte[] fileContent = new byte[(int)fileSize];
FileInputStream inputStream = new FileInputStream(file);
inputStream.read(fileContent, 0, (int)fileSize);//把文件的二进制流加载到fileContent字节数组中去
String md5Str = DigestUtils.md5Hex(fileContent);
System.out.println("merge小文件:"+path+",md5:"+md5Str);
key.set(path);
//把文件路径作为key,文件内容做为value,放入到sequencefile中
writer.append(key, new BytesWritable(fileContent));
}
writer.hflush();
writer.close();
}
//读取大文件中的小文件
public void readMergedFile() throws Exception{
Reader.Option file = Reader.file(new Path("D:\\bigfile.seq"));
Reader reader = new Reader(configuration, file);
Text key = new Text();
BytesWritable value = new BytesWritable();
while(reader.next(key, value)){
byte[] bytes = value.copyBytes();
String md5 = DigestUtils.md5Hex(bytes);
String content = new String(bytes, Charset.forName("GBK"));
System.out.println("读取到文件:"+key+",md5:"+md5+",content:"+content);
}
}
public static void main(String[] args) throws Exception {
MergeSmallFilesToSequenceFile msf = new MergeSmallFilesToSequenceFile();
//合并小文件
msf.addInputPath("D:\\datasets\\smallfile");
msf.mergeFile();
//读取大文件
// msf.readMergedFile();
}
}