1. 资源调度与隔离
在YARN 中,资源管理由 ResourceManager 和 NodeManager 共同完成,其中,ResourceManager 中的调度器负责资源的分配,而 NodeManager 则负责资源的供给和隔离。
资源调度: ResourceManager 将某个 NodeManager 上的资源分配给任务;
资源隔离: NodeManager 需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证;
Hadoop YARN 同时支持内存和 CPU 两种资源的调度,先品味一下内存和 CPU 这两种资源的特点,这是两种性质不同的资源。内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败; 相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
1.2 Memory资源
YARN 允许用户配置每个节点上可用的物理内存资源,注意,这里是 “可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给 YARN,一部分给 HDFS,一部分给 HBase 等,YARN 配置的只是自己可以使用的,配置参数如下:
参数一:yarn.nodemanager.resource.memory-mb
该节点上 YARN 可使用的物理内存总量,默认是8192 (MB);
如果设置为 -1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true时,将会自动计算操作系统内存进行设置。
参数二:yarn.nodemanager.vmem-pmem-ratio
任务每使用 1MB 物理内存,最多可使用虚拟内存量,默认是 2.1
参数三:yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true。
参数四:yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true。
参数五:yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是 1024 (MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
参数六:yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是 8192 (MB)。
默认情况下,YARN 采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于 Cgroups 对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报 OOM),而 Java 进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此 YARN 未提供 Cgroups 内存隔离机制。
1.2 CPU资源
在YARN 中,CPU 资源的组织方式仍在探索中,当前只是非常粗粒度的实现方式。CPU被划分成虚拟CPU(CPU virtual Core),此处的虚拟 CPU 是 YARN 自己引入的概念,初衷是,考虑到不同节点的 CPU 性能可能不同,每个 CPU 具有的计算能力也是不一样的,比如某个物理 CPU 的计算能力可能是另外一个物理 CPU 的 2 倍,此时可以通过为第一个物理 CPU 多配置几个虚拟 CPU 弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟 CPU 个数。
在YARN 中,CPU 相关配置参数如下:
-
参数一:yarn.nodemanager.resource.cpu-vcores
-
该节点上 YARN 可使用的虚拟 CPU 个数,默认是 8,注意,目前推荐将该值设值为与物理 CPU 核数数目相同。如果你的节点 CPU 核数不够 8 个,则需要调减小这个值。
-
如果设置为 -1,并且
yarn.nodemanager.resource.detect-hardware-capabilities为 true 时,将会自动计算操作系统 CPU 核数进行设置。 -
参数二:yarn.scheduler.minimum-allocation-vcores
-
单个任务可申请的最小虚拟 CPU 个数,默认是 1,如果一个任务申请的 CPU 个数少于该数,则该对应的值改为这个数。
-
参数三:yarn.scheduler.maximum-allocation-vcores
-
单个任务可申请的最多虚拟 CPU 个数,默认是 4。
由于 CPU 资源的独特性,目前这种 CPU 分配方式仍然是粗粒度的。
2. 资源调度器
2.1 概述
在YARN 中,负责给应用分配资源的就是 Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,YARN 提供了多种调度器和可配置的策略供选择。
在YARN 中有三种调度器可以选择:FIFO Scheduler(先进先出调度器) ,Capacity Scheduler(容量调度器),Fair Scheduler(公平调度器)。

默认情况下,Apache 版本 YARN 使用的是Capacity调度器。如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置,具体的配置方式如下:

在YARN WebUI 界面:http://hadoop123:8088/cluster
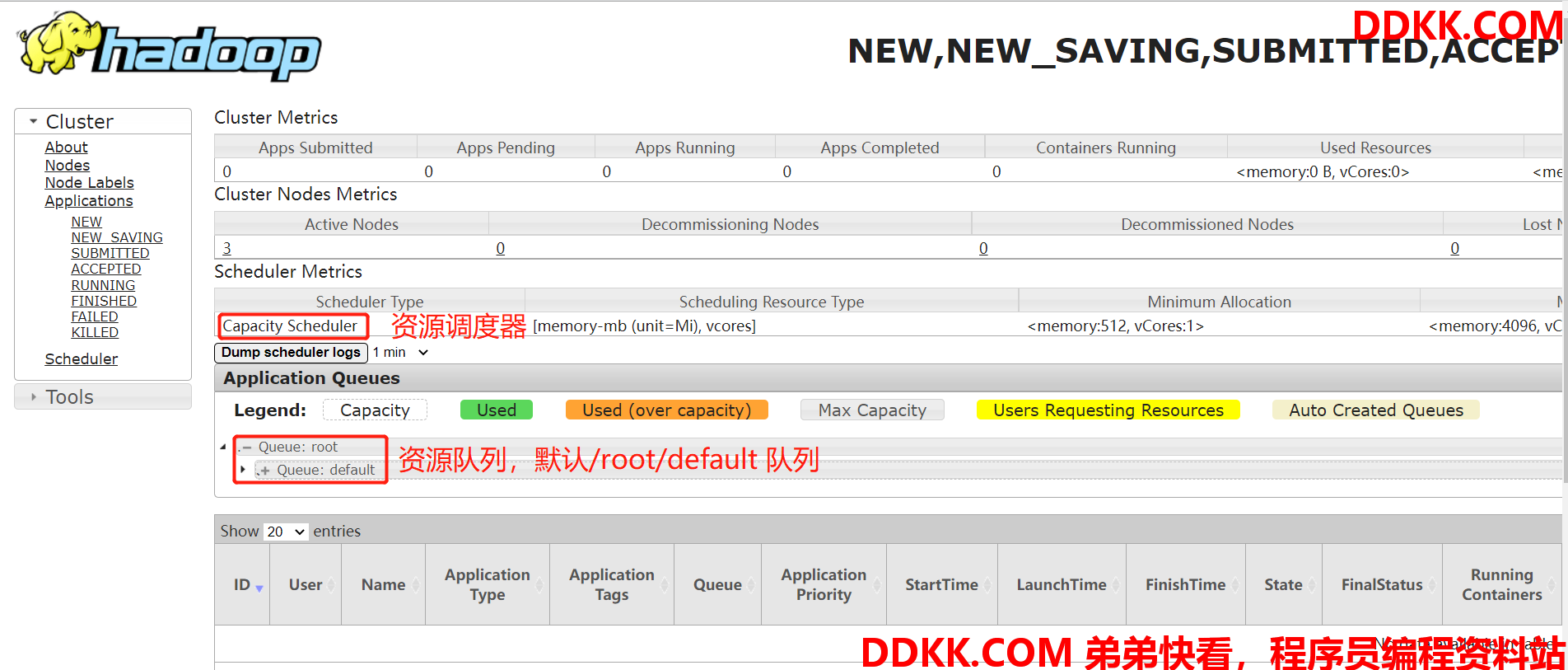
在YARN 中,有层级队列组织方法,它们构成一个树结构,且根队列叫做root。所有的应用都运行在叶子队列中(即树结构中的非叶子节点只是逻辑概念,本身并不能运行应用)。对于任何一个应用,都可以显式地指定它属于的队列,也可以不指定从而使用username或者default队列。下图就是一个队列的结构:

2.2 FIFO Scheduler(先进先出调度器)
FifoScheduler 是 MRv1 中 JobTracker 原有的调度器实现,此调度器在 YARN 中保留了下来。FifoScheduler是一个先进先出的思想,即先来的Application先运行。调度工作不考虑优先级和范围,适用于负载较低的小规模集群。当使用大型共享集群时,它的效率较低且会导致一些问题。
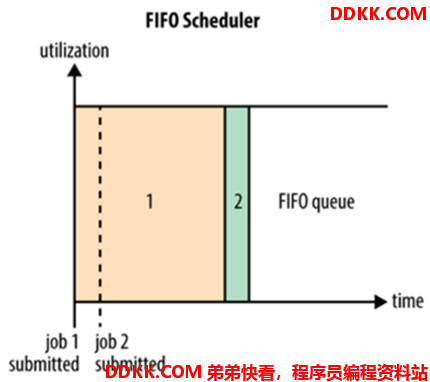
FifoScheduler 拥有一个控制全局的队列 queue,默认queue名称为default,该调度器会获取当前集群上所有的资源信息作用于这个全局的 queue。
FifoScheduler 将所有的Application按照提交时候的顺序来执行,只有当上一个 Job 执行完成之后后面的 Job 才会按照队列的顺序依次被执行。虽然单一的 FIFO 调度实现简单,但是对于很多实际的场景并不能满足要求,催发了 Capacity 调度器和 Fair 调度器的出现。
2.3 Capacity Scheduler(容量调度器)
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。
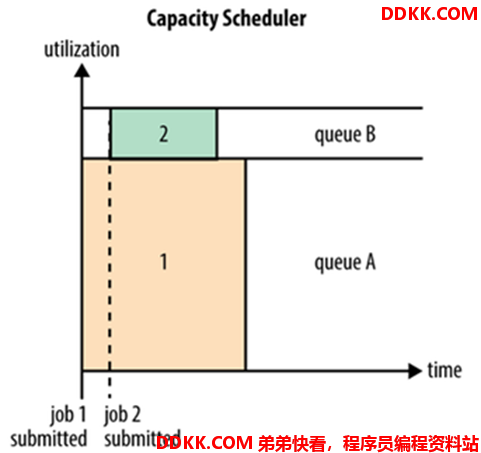
Capacity调度器可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
2.3.1 什么是Capacity Scheduler
Capacity Scheduler 调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的,如下图:
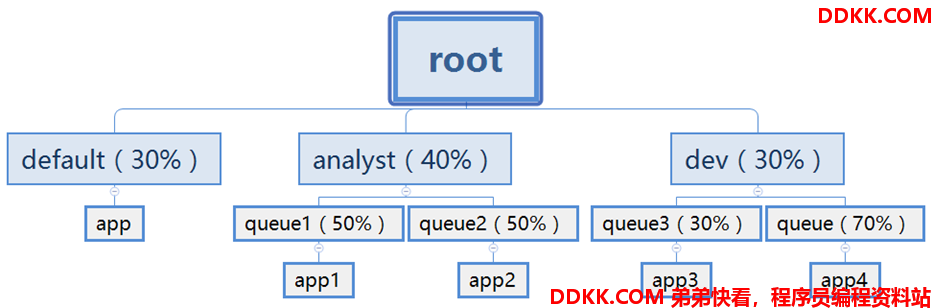
default 队列占30%资源,analyst 和 dev 分别占 40% 和 30% 资源;类似的,analyst 和 dev 各有两个子队列,子队列在父队列的基础上再分配资源。
- 队列里的应用以 FIFO 方式调度,每个队列可设定一定比例的资源最低保证和使用上限;
- 每个用户也可以设定一定的资源使用上限以防止资源滥用;
- 而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
2.3.2 调度器特性
CapacityScheduler 是一个可插拔调度程序,它被设计为以队列为单位划分资源、易于操作的方式在多租户模式下安全的共享大型集群,同时能保证每个组所需资源的保证,当容量不够用时还可以使用其他组多余的容量。这种方式最大程度地提高集群的吞吐量和利用率,以便在分配的容量约束下及时为其应用程序分配资源。CapacityScheduler 的特性如下:
-
层次化的队列设计(Hierarchical Queues)
-
层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
容量保证(Capacity Guarantees)
- 队列上都会设置一个资源的占比,可以保证每个队列都不会占用整个集群的资源。
安全(Security )
- 每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
弹性分配(Elasticity )
- 空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
多租户租用(Multi-tenancy)
- 通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
操作性(Operability)
- Yarn 支持动态修改调整容量、权限等的分配,可以在运行时直接修改;
提供管理员界面,显示当前的队列状况;管理员可以在运行时,添加一个队列;但是不能删除一个队列; - 管理员可以在运行时暂停某个队列,可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了 stopped,那么就不能向它或者子队列上提交任务了。
基于资源的调度(Resource-based Scheduling)
- 协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
基于用户/组的队列隐射(Queue Mapping based on User or Group)
- 允许用户基于用户或者组去映射一个作业到特定队列。
2.3.3 调度器配置
CapacityScheduler 的配置项包括两部分,其中一部分在yarn-site.xml中,主要用于配置 YARN 集群使用的调度器;另一部分在capacity-scheduler.xml配置文件中,主要用于配置各个队列的资源量、权重等信息。
2.3.3.1 开启调度器
在ResourceManager 中配置使用的调度器,修改HADOOP_CONF/yarn-site.xml,设置属性:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
2.3.3.2 配置队列
调度器的核心就是队列的分配和使用,修改HADOOP_CONF/capacity-scheduler.xml可以配置队列。Capacity 调度器默认有一个预定义的队列:root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用.来进行分割,比如:

案例:root 下面有三个子队列

2.3.3.3 队列属性
- 队列的资源容量占比(百分比):

系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是 100%。
队列资源的使用上限

系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是 -1,即禁用。
每个任务占用的最少资源

比如,设置成 25%。那么如果有两个用户提交任务,那么每个任务资源不超过 50%。如果 3 个用户提交任务,那么每个任务资源不超过 33%。如果 4 个用户提交任务,那么每个任务资源不超过 25%。如果 5 个用户提交任务,那么第五个用户需要等待才能提交。默认是 100,即不去做限制。
每个用户最多使用的队列资源占比

如果设置为 50,那么每个用户使用的资源最多就是 50%。
2.3.3.4 运行和提交应用限制
设置系统中可以同时运行和等待的应用数量,默认是10000

设置有多少资源可以用来运行app master,即控制当前激活状态的应用,默认是10%

2.3.3.5 队列管理
- 队列的状态,可以使RUNNING或者STOPPED

如果队列是STOPPED状态,那么新应用不会提交到该队列或者子队列。同样,如果 root 被设置成 STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭。 - 访问控制列表ACL:控制谁可以向该队列提交任务

限定哪些 Linux用户/用户组 可向给定队列中提交应用程序。如果一个用户可以向该队列提交,那么也可以提交任务到它的子队列。配置该属性时,用户之间或用户组之间用 “,” 分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。 - 设置队列的管理员的ACL控制

为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。
2.3.3.6 基于用户/组的队列映射
- 映射单个用户或者用户组到一个队列

语法:[u or g]:[name]:[queue_name][,next_mapping]*,列表可以多个,之间以逗号分隔。%user 放在 [name] 部分,表示已经提交应用的用户。如果队列名称和用户一样,那可以使用 %user 表示队列。如果队列名称和用户主组一样,可以使用 %primary_group 表示队列。u:%user:%user表示已经提交应用的用户,映射到和用户名称一样的队列上。u:user2:%primary_group表示 user2 提交的应用映射到 user2 主组名称一样的队列上。如果用户组并不多,队列也不多,建议还是使用简单的语法,而不要使用带 % 的。 - 定义针对特定用户的队列是否可以被覆盖,默认值为false

2.3.3.7 其他属性
- 资源计算方法

默认是org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和 CPU。 - 调度器尝试进行调度的次数

节点局部性延迟,在容器企图调度本地机栈容器后(失败),还可以错过错过多少次的调度次数。一般都是跟集群的节点数量有关。默认 40(一个机架上的节点数)一旦设置完这些队列属性,就可以在 web ui 上看到了。
2.3.3.8 修改队列配置
如果想要修改队列或者调度器的配置,可以修改HADOOP_CONF_DIR/capacity-scheduler.xml,修改完成后,需要执行下面的命令:
HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues
注意事项:
- 队列不能被删除,只能新增;
- 更新队列的配置需要是有效的值;
- 同层级的队列容量限制相加需要等于 100%;
- 在 MapReduce 中,可以通过mapreduce.job.queuename属性指定要用的队列。如果队列不存在,在提交任务时就会收到错误。如果没有定义任何队列,所有的应用将会放在一个default队列中。
2.3.4 案例:Capacity调度器配置
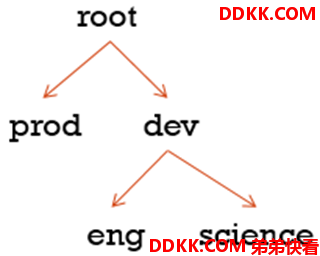
假设有如下层次的队列:

2.3.4.1 Capacity Scheduler配置
上图中队列的一个调度器配置文件HADOOP_CONF/capacity-scheduler.xml:
<?xml version="1.0"?>
<configuration>
<!-- 分为两个队列,分别为prod和dev -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<!-- dev继续分为两个队列,分别为eng和science -->
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<!-- 设置prod队列40% -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<!-- 设置dev队列60% -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<!-- 设置dev队列可使用的资源上限为75% -->
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<!-- 设置eng队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<!-- 设置science队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>
相关属性说明如下所示:
- dev队列又被分成了eng和science两个相同容量的子队列;
- dev的maximum-capacity属性被设置成了 75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有 25% 的可用资源用来应急;
- eng和science两个队列没有设置maximum-capacity属性,也就是说eng或science队列中的 job 可能会用到整个dev队列的所有资源(最多为集群的 75%);
- 而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源;
- 对于Capacity调度器,队列名必须是队列树中的最后一部分,如果使用队列树则不会被识别。比如,在上面配置中,使用prod和eng作为队列名是可以的,但是如果用root.dev.eng或者dev.eng是无效的。
2.3.4.2 测试运行
上述配置队列形式如下所示:
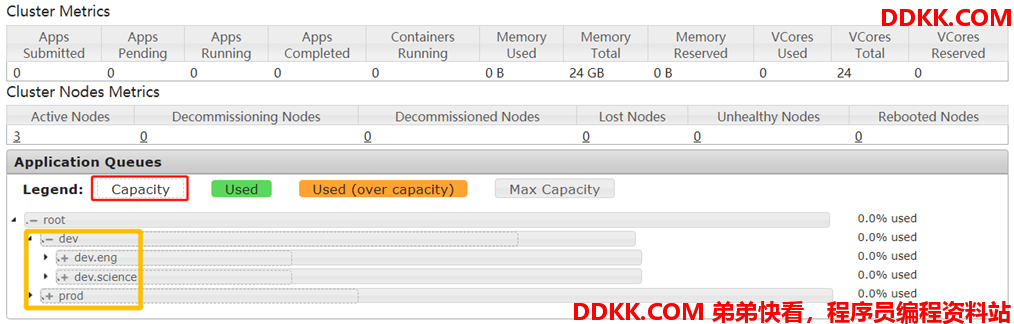
启动 ResouceManager,打开 8088 页面:
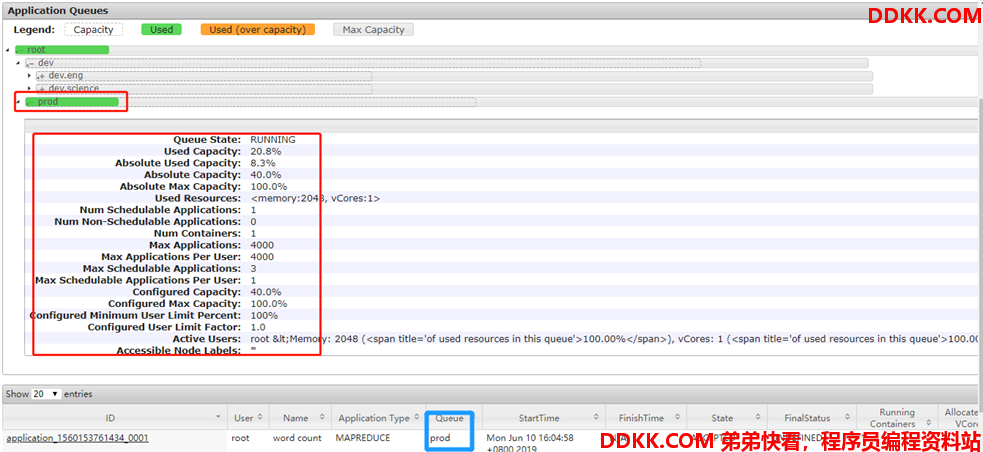
运行 MapReduce 中 WordCount 程序,指定运行队列 prod
HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
-Dmapreduce.job.queuename=prod \
datas/input.data /datas/output
查看 8088 界面如下所示:
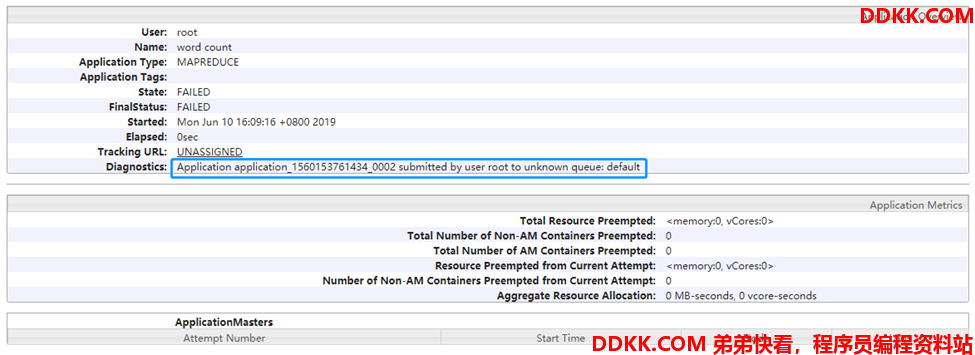
不指定运行队列,默认运行在default队列,如果找不到default队列将会报如下错误。
HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
datas/input.data /datas/output2
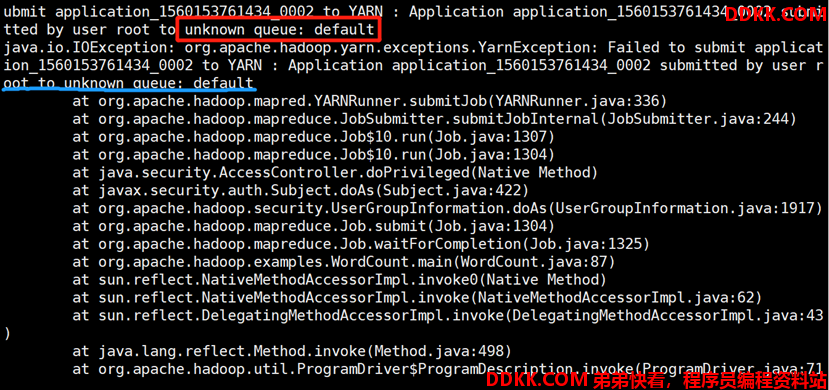
查看 8088 界面如下所示:
还有一个 Fair Scheduler 公平调度器下一篇博客再详细说,因为这个要说的东西比较多。(这篇博客太长了,csdn编辑面板总是崩)