1. Hadoop常用文件存储格式
1.1 传统系统常见文件存储格式
在Windows 有很多种文件格式,例如:JPEG 文件用来存储图片、MP3 文件用来存储音乐、DOC 文件用来存储 WORD 文档。每一种文件存储某一类的数据,例如:我们不会用文本来存储音乐、不会用文本来存储图片。Windows 上支持的存储格式是非常的多。
1.1.1 文件系统块大小
- 在服务器/电脑上,有多种块设备(Block Device),例如:硬盘、CDROM、软盘等等。
- 每个文件系统都需要将一个分区拆分为多个块,用来存储文件。不同的文件系统块大小不同。
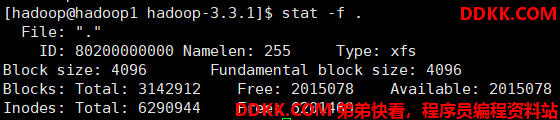
例如:我们看到该文件系统的块大小为:4096字节 = 4KB。如果我们需要在磁盘中存储 5 个字节的数据,也会占据 4096 字节的空间。
1.2 Hadoop中文件存储格式
Hadoop 上的文件存储格式,肯定不会像 Windows 这么丰富,因为目前我们用 Hadoop 来存储、处理数据。我们不会用 Hadoop 来听歌、看电影、或者打游戏。
-
文件格式是定义数据文件系统中存储的一种方式,可以在文件中存储各种数据结构,特别是 Row、Map,数组以及字符串,数字等。
-
在 Hadoop 中,没有默认的文件格式,格式的选择取决于其用途。而选择一种优秀、适合的数据存储格式是非常重要的。
-
后续我们要讲的,使用 HDFS 的应用程序(例如 MapReduce 或 Spark、Flink)性能中的最大问题、瓶颈是在特定位置查找数据的时间和写入到另一个位置的时间,而且管理大量数据的处理和存储也很复杂(例如:数据的格式会不断变化,原来一行有 12 列,后面要存储 20 列)。
-
Hadoop 文件格式发展了好一段时间,这些文件存储格式可以解决大部分问题。我们在开发大数据中,选择合适的文件格式可能会带来一些明显的好处:
-
可以保证写入的速度
-
可以保证读取的速度
-
文件是可被切分的
-
对压缩支持友好
-
支持schema的更改
-
某些文件格式是为通用设计的(如 MapReduce 或 Spark、Flink),而其他文件则是针对更特定的场景,有些在设计时考虑了特定的数据特征。因此,确实有很多选择。
1.3 BigData File Viewer工具
1.3.1 介绍
- 一个跨平台(Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如 Parquet,ORC,AVRO 等。支持本地文件系统,HDFS,AWS S3 等。
GitHub地址:https://github.com/Eugene-Mark/bigdata-file-viewer
1.3.2 功能
- 打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等。
- 将二进制格式的数据转换为文本格式的数据,例如CSV
- 支持复杂的数据类型,例如数组,映射,结构等
- 支持Windows,MAC和Linux等多种平台
- 代码可扩展以涉及其他数据格式
1.4 Hadoop丰富的存储格式
1.4.1 Text File
1.4.1.1 简介
- 文本文件在非 Hadoop 领域很常见,在 Hadoop 领域也很常见。
- 数据一行一行到排列,每一行都是一条记录。以典型的 UNIX 方式以换行符\n终止。
- 文本文件是可以被切分的,但如果对文本文件进行压缩,则必须使用支持切分文件的压缩编解码器,例如 BZIP2。因为这些文件只是文本文件,压缩时会对所有内容进行编码。
- 可以将每一行成为 JSON 文档,可以让数据带有结构。
1.4.1.2 应用场景
仅在需要从 Hadoop 中直接提取数据,或直接从文件中加载大量数据的情况下,才建议使用纯文本格式或 CSV。
1.4.1.3 优缺点
-
优点
-
简单易读、轻量级
-
缺点
-
读写速度慢。
-
不支持块压缩,在 Hadoop 中对文本文件进行压缩/解压缩会有较高的读取成本,因为需要将整个文件全部压缩或者解压缩。
-
无法切分压缩文件(会导致较大的 map task)。
1.4.2 Sequence File
1.4.2.1 简介
- Sequence 最初是为 MapReduce 设计的,因此和 MapReduce 集成很好。
- 在 Sequence File 中,每个数据都是以一个 key 和一个 value 进行序列化存储,仅此而已。
- Sequence File 中的数据是以二进制格式存储,这种格式所需的存储空间小于文本的格式。与文本文件一样,Sequence File 内部也不支持对键和值的结构指定格式编码。
1.4.2.2 应用场景
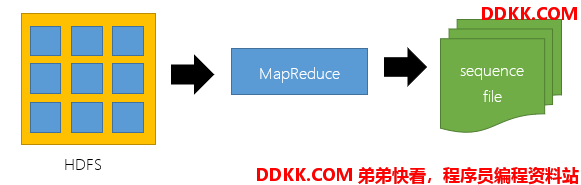
通常把 Sequence file 作为中间数据存储格式。例如:将大量小文件合并放入到一个 SequenceFIle 中
1.4.2.3 结构
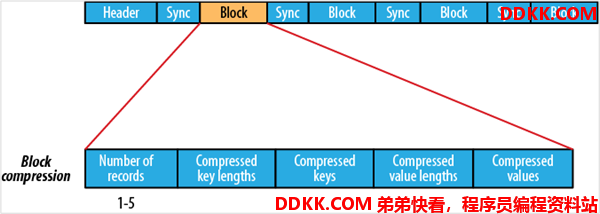
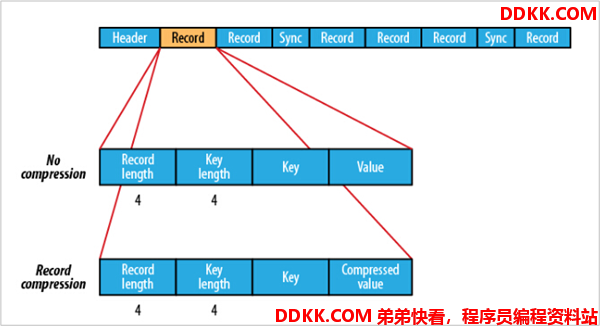
1.4.2.4 优缺点
-
优点
-
与文本文件相比更紧凑,支持块级压缩。
- 压缩文件内容的同时,支持将文件切分。
- 序列文件在 Hadoop 和许多其他支持 HDFS 的项目支持很好,例如:Spark。
- 它是让我们摆脱文本文件迈出第一步。
-
它可以作为大量小文件的容器。
-
缺点
-
对于具有 SQL 类型的 Hive 支持不好,需要读取和解压缩所有字段。
-
不存储元数据,并且对 schema 扩展中的唯一方式是在末尾添加新字段。
1.4.3 Avro File
1.4.3.1 简介
- Apache Avro 是与语言无关的序列化系统,由 Hadoop 创始人 Doug Cutting开发
- Avro 是基于行的存储格式,它在每个文件中都包含 JSON 格式的 schema 定义,从而提高了互操作性并允许 schema 的变化(删除列、添加列)。 除了支持可切分以外,还此次块压缩。
- Avro 是一种自描述格式,它将数据的 schema 直接编码存储在文件中,可以用来存储复杂结构的数据。
- Avro 可以进行快速序列化,生成的序列化数据也比较小。
1.4.3.2 应用场景
- 适合于一次性需要将大量的列(数据比较宽)、写入频繁的场景
- 随着更多存储格式的发展,常用于 Kafka 和 Druid 中
1.4.3.3 结构
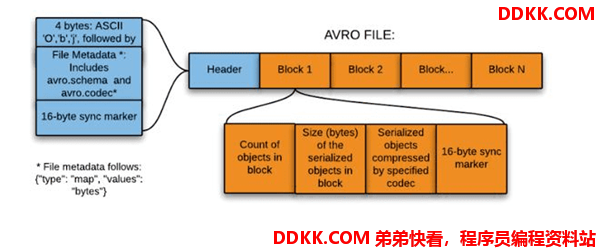
直接将一行数据序列化在一个block中
1.4.3.4 优缺点
-
优点
-
Avro 是与语言无关的数据序列化系统。
-
Avro 将 schema 存储在 header 中,数据是自描述的。
-
序列化和反序列化速度很快。
-
Avro 文件是可切分的、可压缩的,非常适合在 Hadoop 生态系统中进行数据存储。
-
缺点
-
如果我们只需要对数据文件中的少数列进行操作,行式存储效率较低。例如:我们读取 15 列中的 2 列数据,基于行式存储就需要读取数百万行的 15 列。而列式存储就会比行式存储方式高效
-
列式存储因为是将同一列(类)的数据存储在一起,压缩率要比方式存储高
1.4.4 RCFile
1.4.4.1 简介
- RCFile 是为基于 MapReduce 的数据仓库系统设计的数据存储结构。它结合了行存储和列存储的优点,可以满足快速数据加载和查询,有效利用存储空间以及适应高负载的需求。
- RCFile 是由二进制键/值对组成的flat文件,它与 sequence file 有很多相似之处。
- 在数仓中执行分析时,这种面向列的存储非常有用。当我们使用面向列的存储类型时,执行分析很容易。
注: 无法将数据直接加载到 RCFile 中。首先需要将数据加载到另一个表中,然后将其覆盖写入到新创建的 RCFile 中。
1.4.4.2 应用场景
- 常用在Hive中
1.4.4.3 结构
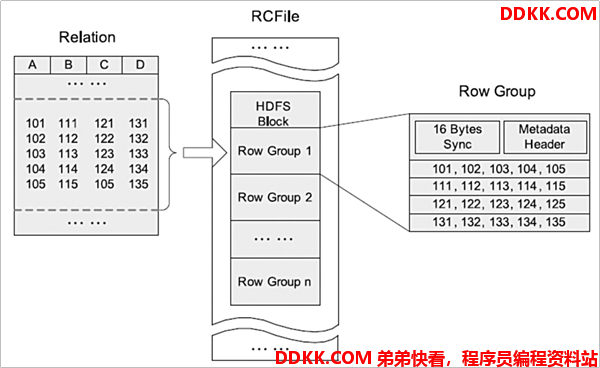
- RCFile 可将数据分为几组行,并且在其中将数据存储在列中。
- RCFile 首先将行水平划分为行拆分(Row Group),然后以列方式垂直划分每个行拆分(Columns)。
- RCFile 将行拆分的元数据存储为 record 的 key,并将行拆分的所有数据存储 value。
- 作为行存储,RCFile 保证同一行中的数据位于同一节点中。
- 作为列存储,RCFile 可以利用列数据压缩,并跳过不必要的列读取。
1.4.4.4 优缺点
-
优点
-
基于列式的存储,更好的压缩比。
-
利用元数据存储来支持数据类型。
-
支持 Split。
-
缺点
-
RC 不支持 schema 扩展,如果要添加新的列,则必须重写文件,这会降低操作效率。
1.4.5 ORC File
1.4.5.1 简介
- Apache ORC(Optimized Row Columnar,优化行列)是 Apache Hadoop 生态系统面向列的开源数据存储格式,它与 Hadoop 环境中的大多数计算框架兼容。
- ORC 代表“优化行列”,它以比 RC 更为优化的方式存储数据,提供了一种非常有效的方式来存储关系数据,然后存储 RC 文件。
- ORC 将原始数据的大小最多减少 75%,数据处理的速度也提高了。
1.4.5.2 应用场景
- 常用在 Hive 中
1.4.5.3 结构
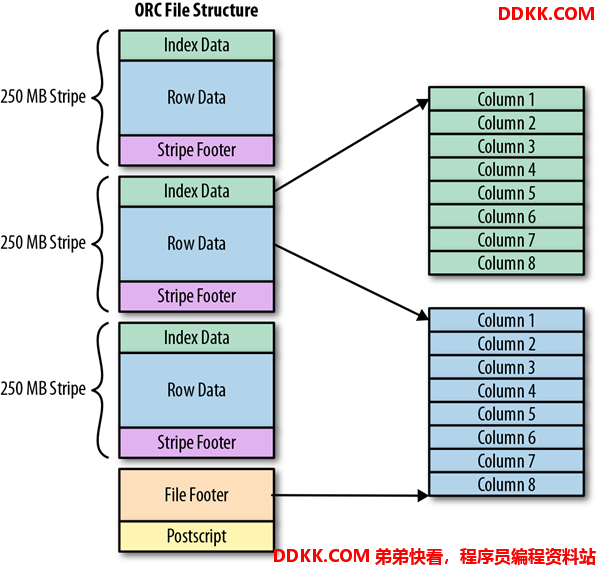
1.4.5.4 优缺点
-
优点
-
比 TextFile,Sequence File 和 RC File 具备更好的的性能。
-
列数据单独存储。
-
带类型的数据存储格式,使用类型专用的编码器。
-
轻量级索引。
-
缺点
-
与 RC 文件一样,ORC 也是不支持列扩展的。
1.4.6 Parquet File
1.4.6.1 简介
- Parquet File 是另一种列式存储的结构,来自于 Hadoop 的创始人 Doug Cutting 的 Trevni 项目。
- 和 ORCFile 一样,Parquet 也是基于列的二进制存储格式,可以存储嵌套的数据结构。
- 当指定要使用列进行操作时,磁盘输入/输出操效率很高。
- Parquet 与 Cloudera Impala 兼容很好,并做了大量优化。
- 支持块压缩。
- 与 RC 和 ORC 文件不同,Parquet serdes 支持有限的 schema 扩展。在 Parquet 中,可以在结构的末尾添加新列。
关于 Hive 对 Parquet 文件的支持的一个注意事项: Parquet 列名必须小写,这一点非常重要。如果 Parquet 文件包含大小写混合的列名,则 Hive 将无法读取该列。
1.4.6.2 结构
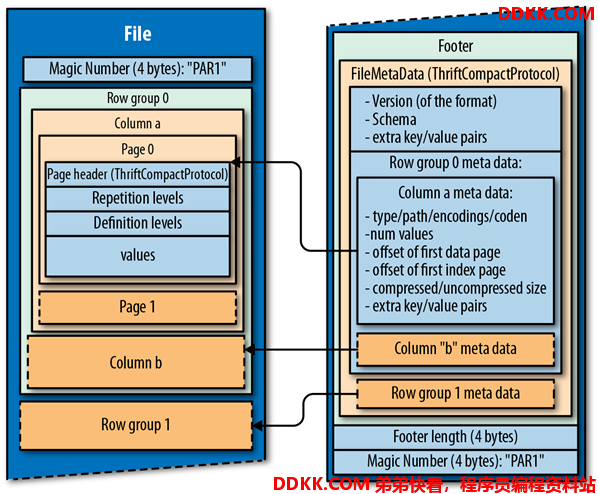
1.4.6.3 优缺点
-
优点
-
和 ORC 文件一样,它非常适合进行压缩,具有出色的查询性能,尤其是从特定列查询数据时,效率很高
-
缺点
-
与 RC 和 ORC 一样,Parquet 也具有压缩和查询性能方面的优点,与非列文件格式相比,写入速度通常较慢。
1.5 Parquet VS ORC
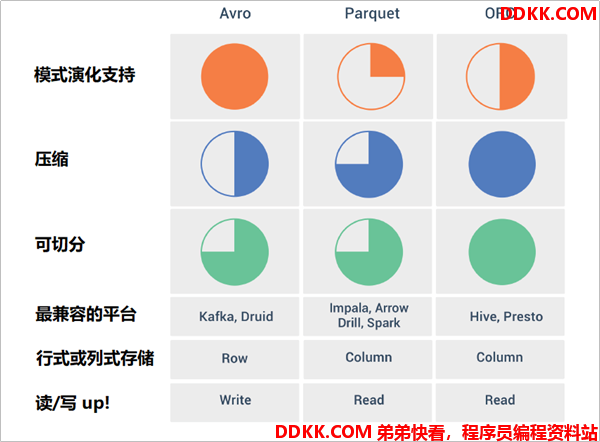
- ORC 文件格式压缩比 parquet 要高,parquet 文件的数据格式 schema 要比 ORC 复杂,占用的空间也就越高。
- ORC 文件格式的读取效率要比 parquet 文件格式高。
- 如果数据中有嵌套结构的数据,则 Parquet 会更好。
- Hive 对 ORC 的支持更好,对 parquet 支持不好,ORC 与 Hive 关联紧密。
- ORC 还可以支持 ACID、Update 操作等。
- Spark 对 parquet 支持较好,对 ORC 支持不好。
- 为了数据能够兼容更多的查询引擎,Parquet 也是一种较好的选择。
1.6 ProtoBuf和Thrift
由于 Protobuf 和 Thrift 是不可 split 的,因此它们在 HDFS 中并不流行。
1.7 扩展:Apache Arrow
1.7.1 Arrow简介
- Apache Arrow 是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。Apache Arrow 在 2016 年 2 月 17 日作为顶级 Apache 项目引入。
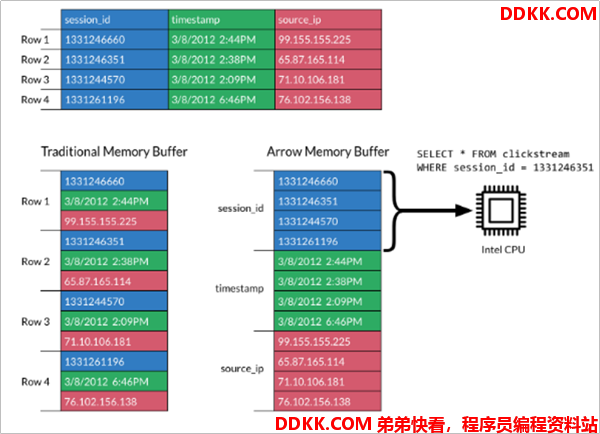
- Apache Arrow 发展非常迅速,并且在未来会有更好的发展空间。 它可以在系统之间进行高效且快速的数据交换,而无需进行序列化,而这些成本已与其他系统(例如 Thrift,Avro 和 Protocol Buffers)相关联。
- 每一个系统实现,它的方法(method)都有自己的内存存储格式,在开发中,70%-80%的时间浪费在了序列化和反序列化上。
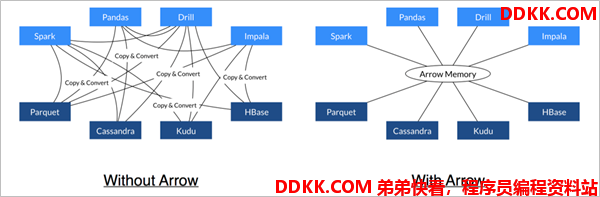
- Arrow 促进了许多组件之间的通信。 例如,使用Python(pandas)读取复杂的文件并将其转换为Spark DataFrame。
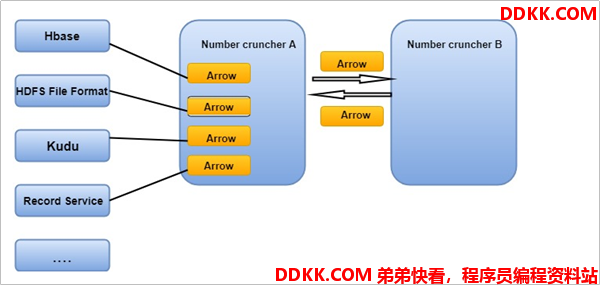
1.7.2 Arrow是如何提升数据移动性能的
- 利用 Arrow 作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark 可以使用 Python 进程发送 Arrow 数据来执行用户定义的函数。
- 无需进行反序列化,可以直接从启用了 Arrow 的数据存储系统中接收 Arrow 数据。 例如,Kudu 可以将 Arrow 数据直接发送到 Impala 进行分析。
- Arrow 的设计针对嵌套结构化数据(例如在 Impala 或 Spark Data 框架中)的分析性能进行了优化。
2. 文件压缩格式
在Hadoop 中,一般存储着非常大的文件,以及在存储 HDFS 块或运行 MapReduce 任务时,Hadoop 集群中节点之间的存在大量数据传输。 如果条件允许时,尽量减少文件大小,这将有助于减少存储需求以及减少网络上的数据传输。
2.1 Hadoop支持的压缩算法
Haodop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口,所有的实现类都在org.apache.hadoop.io.compress包下。
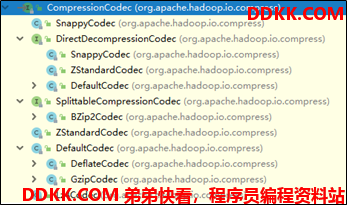
2.1.1 压缩算法比较
有不少的压缩算法可以应用到 Hadoop 中,但不同压缩算法有各自的特点。
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码/解码器 |
|---|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | DEFAULT | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
存放数据到 HDFS 中,可以选择指定的压缩方式,在 MapReduce 程序读取时,会根据扩展名自动解压。例如:如果文件扩展名为.snappy,Hadoop 框架将自动使用 SnappyCodec 解压缩文件。
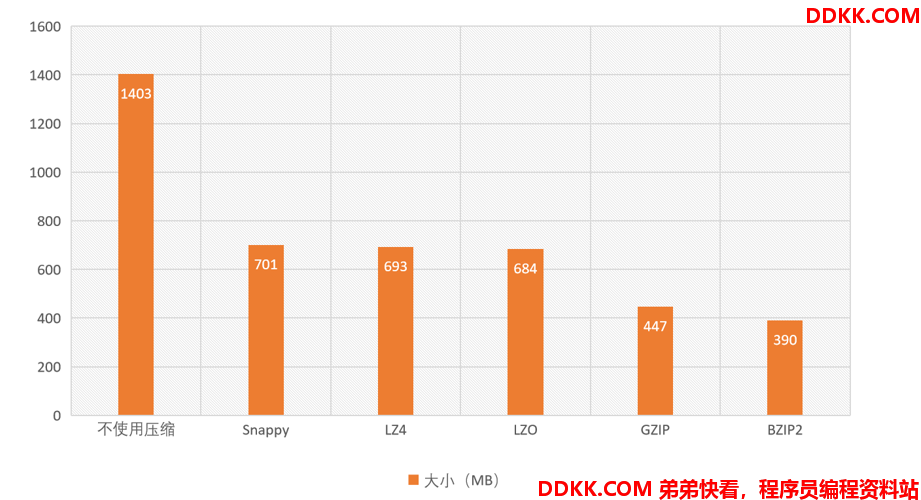
通过上图,我们可以看到哪些压缩算法压缩比更高。整体排序如下:
Snappy < LZ4 < LZO < GZIP < BZIP2,但压缩比越高,压缩的时间也会更长。以下是部分参考数据:
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
2.2 HDFS压缩如何抉择
既然压缩能够节省空间、而且可以提升 IO 效率,那么能否将所有数据都以压缩格式存储在 HDFS 中呢?例如:bzip2,而且文件是支持切分的。
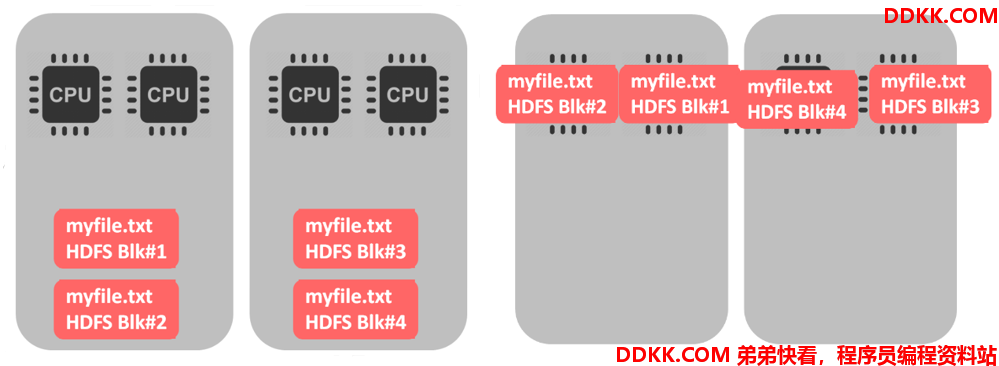
如果选择 GZIP,就会出现以下情况:
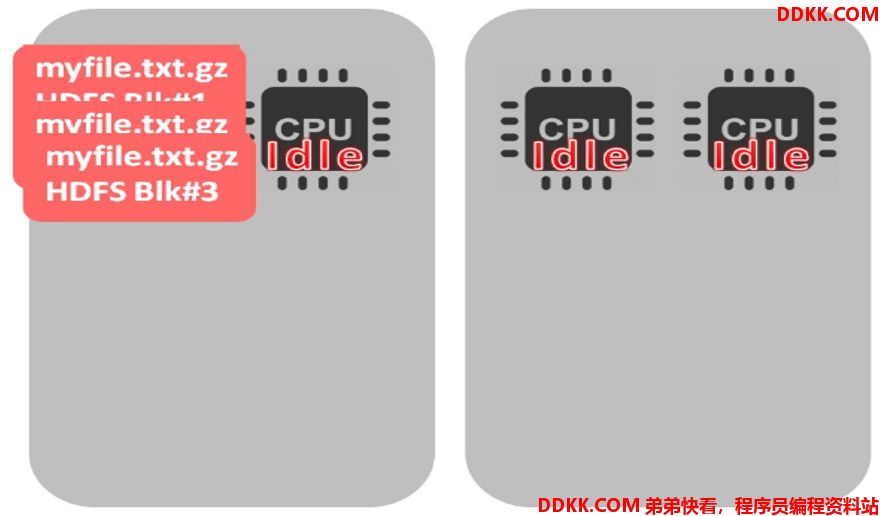
- 如果文件是不可切分的,只有一个 CPU 在处理所有的文件,其他的 CPU 都是空闲的。如果 HDFS 中的 block 和文件大小差不多还好,一个文件、一个块、一个 CPU。如果是一个很大的文件就会出现问题了。
- bzip2 在压缩和解压缩数据方面实际上平均比 Gzip 差 3 倍,这对性能是有一定的影响的。如果我们需要频繁地查询数据,数据压缩一定会影响查询效率。
- 如果不关心查询性能(没有任何 SLA)并且很少选择此数据,则 bzip2 可能是不错的选择。最好是对自己的数据进行基准测试,然后再做决定。
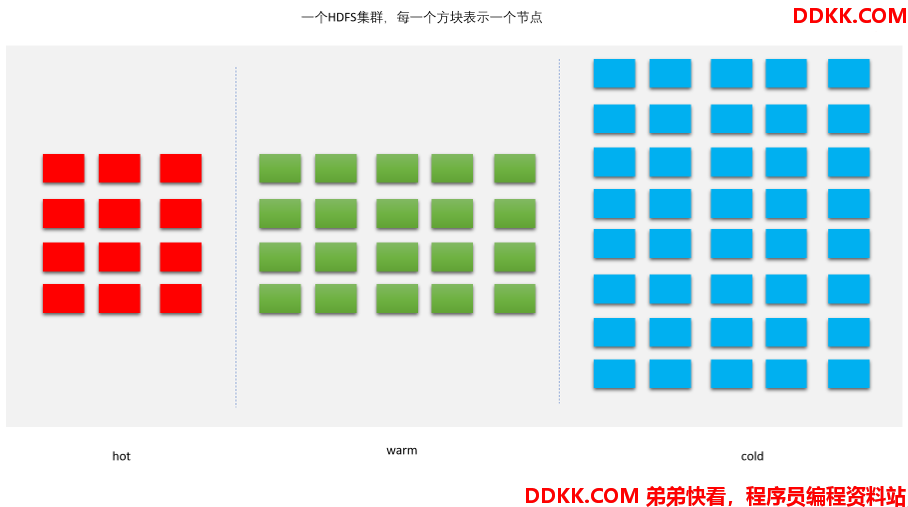
3. HDFS存储类型和存储策略
3.1 介绍
- Archive 存储(档案存储)是一种将增长的存储容量与计算容量解耦的解决方案。
- 可以将一些需要存储、但计算需求很少的数据放在低成本的存储节点中,这些节点用于集群中冷数据的存储。
- 根据策略,热数据可以转移到冷节点存储。在冷区域中加入更多的节点可以使存储与集群中的计算容量无关。
- 异构存储和归档存储提供的框架将 HDFS 体系结构概括为包括其他类型的存储介质,包括:SSD 和内存。用户可以选择将数据存储在 SSD 或内存中以获得更好的性能。
3.2 存储类型和存储策略
3.2.1 多种多样的存储类型
大家考虑一个问题:我们可以将数据保存在什么样的存储类型中呢?
-
硬盘
-
SSD
-
SATA
-
内存
-
NAS
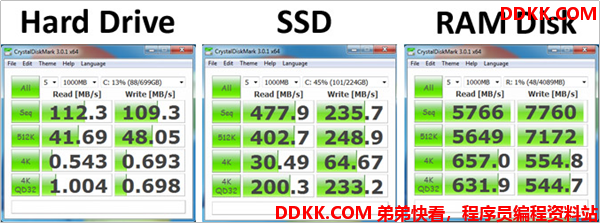
3.2.2 速率对比
RAM 比 SSD 快几个数量级。普通的磁盘大致的速度为 30-150MB,比较快的 SSD 可以实现 500MB/秒 的实际写入速度。 RAM 的理论上最大速度可以达到 SSD 实际性能的 30 倍。
以下是一个实际对比图:
3.2.3 存储类型
之前在hdfs-site.xml中配置,是将数据保存在 Linux 中的本地磁盘。
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop-3.3.1/data/datanode</value>
</property>
以上配置跟下面的配置是一样的:
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]:/data/hadoop-3.3.1/data/datanode</value>
</property>
在HDFS 中,可以给不同的存储介质分配不同的存储类型:
- DISK:默认的存储类型,磁盘存储。
- ARCHIVE:具有存储密度高(PB级),但计算能力小的特点,可用于支持档案存储。
- SSD:固态硬盘。
- RAM_DISK:DataNode 中的内存空间。
3.2.4 存储策略介绍
HDFS 中提供热、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence 等存储策略。为了根据不同的存储策略将文件存储在不同的存储类型中,引入了一种新的存储策略概念。HDFS 支持以下存储策略:
-
热(hot)
-
用于大量存储和计算。
-
当数据经常被使用,将保留在此策略中。
-
当 block 是 hot 时,所有副本都存储在磁盘中。
-
冷(cold)
-
仅仅用于存储,只有非常有限的一部分数据用于计算。
-
不再使用的数据或需要存档的数据将从热存储转移到冷存储中。
-
当 block 是 cold 时,所有副本都存储在 Archive 中。
-
温(warm)
-
部分热,部分冷。
-
当一个块是 warm 时,它的一些副本存储在磁盘中,其余的副本存储在 Archive 中。
-
全SSD
-
将所有副本存储在 SSD 中。
-
单SSD
-
在 SSD 中存储一个副本,其余的副本存储在磁盘中。
-
懒持久
-
用于编写内存中只有一个副本的块。副本首先写在 RAM_Disk 中,然后惰性地保存在磁盘中。
3.2.5 HDFS中的存储策略
HDFS存储策略由以下字段组成:
1、 策略ID(PolicyID);
2、 策略名称(PolicyName);
3、 块放置的存储类型列表(BlockPlacement);
4、 用于创建文件的后备存储类型列表(Fallbackstoragesforcreation);
5、 用于副本的后备存储类型列表(Fallbackstoragesforreplication);
当有足够的空间时,块副本将根据 #3 中指定的存储类型列表存储。当列表 #3 中的某些存储类型耗尽时,将分别使用 #4 和 #5 中指定的后备存储类型列表来替换空间外存储类型,以便进行文件创建和副本。
以下是一个典型的存储策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | - | ARCHIVE |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | - | - |
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事项:
1、 Lazy_Persistence策略仅对单个副本块有用对于具有多个副本的块,所有副本都将被写入磁盘,因为只将一个副本写入RAM_Disk并不能提高总体性能;
2、 对于带条带的擦除编码文件,合适的存储策略是ALL_SSD、HOST、CORD因此,如果用户为EC文件设置除上述之外的策略,在创建或移动块时不会遵循该策略;
3.2.6 存储策略方案
-
创建文件或目录时,其存储策略为未指定状态。可以使用:storagepolicies -setStoragePolicy命令指定
-
文件或目录的有效存储策略由以下规则解析:
-
如果使用存储策略指定了文件或目录,则返回该文件或目录。
-
对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略
-
可以使用 storagepolicies –getStoragePolicy 命令获取有效的存储策略。
3.2.7 配置
-
dfs.storage.policy.enabled
-
启用/禁用存储策略功能。默认值是 true
-
dfs.datanode.data.dir
-
在每个数据节点上,应当用逗号分隔的存储位置标记它们的存储类型。这允许存储策略根据策略将块放置在不同的存储类型上。
注意:
1、 磁盘上的DataNode存储位置/grid/dn/disk0应该配置为[DISK]file:///grid/dn/disk0;
2、 SSD上的DataNode存储位置/grid/dn/ssd0应该配置为[SSD]file:///grid/dn/ssd0;
3、 存档上的DataNode存储位置/grid/dn/Archive0应该配置为[ARCHIVE]file:///grid/dn/archive0;
4、 将RAM_磁盘上的DataNode存储位置/grid/dn/ram0配置为[RAM_DISK]file:///grid/dn/ram0;
5、 如果DataNode存储位置没有显式标记存储类型,它的默认存储类型将是磁盘;
3.3 存储策略命令
3.3.1 列出存储策略
列出所有存储策略命令:
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
3.3.2 设置存储策略
为一个文件或目录设置存储策略:
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
| -policy | 存储策略的名称 |
3.3.3 取消存储策略
取消文件或目录的存储策略。在执行 unset 命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
hdfs storagepolicies -unsetStoragePolicy -path <path>
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
3.3.4 获取存储策略
获取文件或目录的存储策略:
hdfs storagepolicies -getStoragePolicy -path <path>
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
3.4 冷热温三阶段数据存储
为了更加充分的利用存储资源,我们可以将数据分为冷、热、温三个阶段来存储。
| /data/hdfs-test/data_phase/hot | 热阶段数据 |
| /data/hdfs-test/data_phase/warm | 温阶段数据 |
| /data/hdfs-test/data_phase/cold | 冷阶段数据 |
3.4.1 配置DataNode存储目录
为了能够支撑不同类型的数据,我们需要在 hdfs-site.xml 中配置不同存储类型数据的位置。
1、 进入到Hadoop配置目录,编辑hdfs-site.xml;
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///data/hadoop-3.3.1/data/datanode,[ARCHIVE]file:///data/hadoop-3.3.1/data/archive</value>
<description></description>
</property>
1、 分发到另外两个节点;
scp hdfs-site.xml 192.168.68.102:$PWD
scp hdfs-site.xml 192.168.68.103:$PWD
1、 重启HDFS集群;
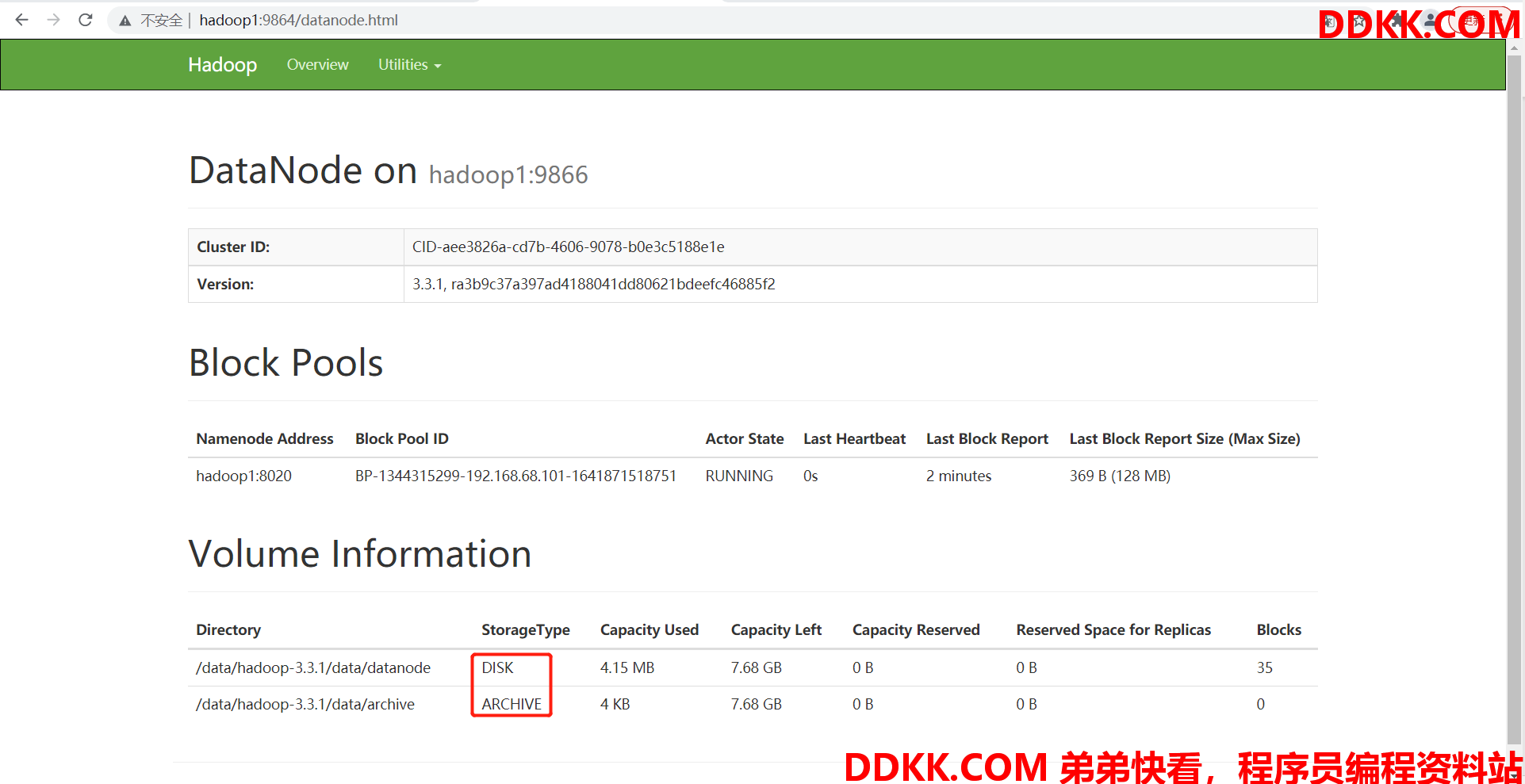
配置好后,我们在 WebUI 的 Datanodes 页面中点击任意一个 DataNode 节点:
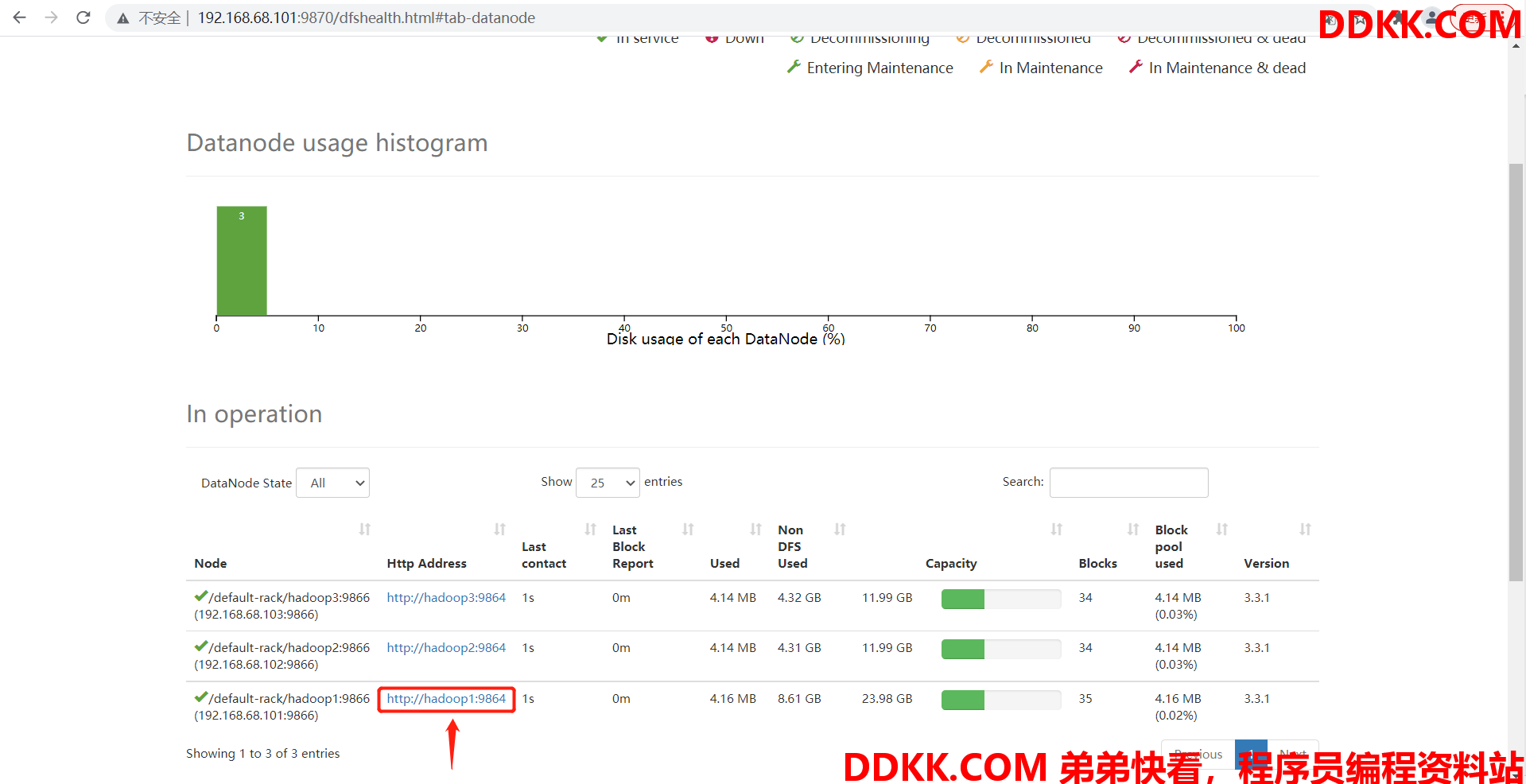
可以看到,现在配置的是两个目录,一个 StorageType 为 ARCHIVE、一个 StorageType 为 DISK。
3.4.2 配置策略
1、 创建测试目录结构;
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold
1、 查看当前HDFS支持的存储策略;
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
1、 分别设置三个目录的存储策略;
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD
1、 查看三个目录的存储策略;
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
The storage policy of /data/hdfs-test/data_phase/hot:
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
The storage policy of /data/hdfs-test/data_phase/warm:
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold
The storage policy of /data/hdfs-test/data_phase/cold:
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
3.4.3 上传测试
1、 分别上传文件到三个目录中测试;
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold
1、 查看不同存储策略文件的block位置;
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fhot%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/hot/profile at Thu Jan 13 14:50:08 CST 2022
/data/hdfs-test/data_phase/hot/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
3. BP-1344315299-192.168.68.101-1641871518751:blk_1073741967_1143 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.103:9866,DS-ba9340ea-d242-4cea-b005-74b64e34ac39,DISK], DatanodeInfoWithStorage[192.168.68.101:9866,DS-e9f568d7-2eac-43b7-aed0-683514a8c41c,DISK], DatanodeInfoWithStorage[192.168.68.102:9866,DS-f23db2c4-f076-49e0-a721-c4c0aff89e8d,DISK]]
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/warm/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fwarm%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/warm/profile at Thu Jan 13 14:52:18 CST 2022
/data/hdfs-test/data_phase/warm/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
0. BP-1344315299-192.168.68.101-1641871518751:blk_1073741968_1144 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.103:9866,DS-c54b6721-9962-4f13-a472-bca18c495dd0,ARCHIVE], DatanodeInfoWithStorage[192.168.68.102:9866,DS-1e50ee7c-eca0-49a4-b453-e9890759f328,ARCHIVE], DatanodeInfoWithStorage[192.168.68.101:9866,DS-e9f568d7-2eac-43b7-aed0-683514a8c41c,DISK]]
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/cold/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fcold%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/cold/profile at Thu Jan 13 14:53:05 CST 2022
/data/hdfs-test/data_phase/cold/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
0. BP-1344315299-192.168.68.101-1641871518751:blk_1073741969_1145 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.102:9866,DS-1e50ee7c-eca0-49a4-b453-e9890759f328,ARCHIVE], DatanodeInfoWithStorage[192.168.68.103:9866,DS-c54b6721-9962-4f13-a472-bca18c495dd0,ARCHIVE], DatanodeInfoWithStorage[192.168.68.101:9866,DS-0f356fed-83d9-4dc9-9f3e-ac52ce649236,ARCHIVE]]
可以看到:
- hot目录中的block,3个block都在DISK磁盘
- warm目录中的block,1个block在DISK磁盘,另外两个在archive磁盘
- cold目录中的block,3个block都在archive磁盘
3.5 HDFS中的内存存储支持
3.5.1 介绍
- HDFS 支持写入由 DataNode 管理的堆外内存
- DataNode 异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘 IO 操作,这种写入称之为懒持久写入。
- HDFS 为懒持久化写做了较大的持久性保证。在将副本保存到磁盘之前,如果节点重新启动,有非常小的几率会出现数据丢失。应用程序可以选择使用懒持久化写,以减少写入延迟。
该特性从 Apache Hadoop 2.6.0 开始支持。
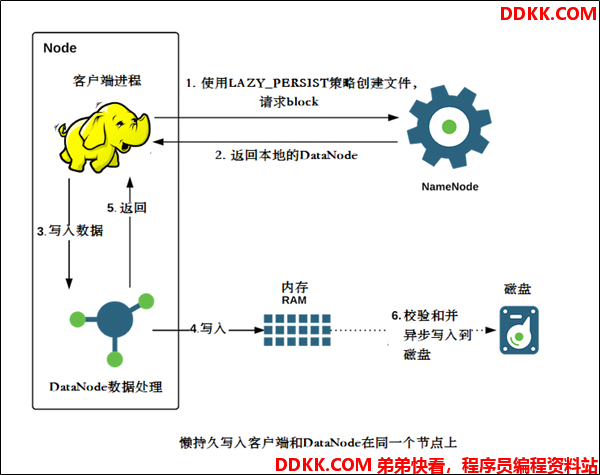
- 比较适用于,当应用程序需要往 HDFS 中以低延迟的方式写入相对较低数据量(从几GB到十几GB,取决于可用内存)的数据时。
- 内存存储适用于在集群内运行,且运行的客户端与 HDFS DataNode 处于同一节点的应用程序。使用内存存储可以减少网络传输的开销。
- 如果内存不足或未配置,使用懒持久化写入的应用程序将继续工作,会继续使用磁盘存储。
3.5.2 配置内存存储支持
3.5.2.1 设置能够使用的内存空间
确定用于存储在内存中的副本内存量
- 在指定 DataNode 的 hdfs-site.xml 设置 dfs.datanode.max.locked.memory
- DataNode 将确保懒持久化的内存不超过 dfs.datanode.max.locked.memory
- 例如,为内存中的副本预留 32 GB
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>
在设置此值时,请记住,还需要内存中的空间来处理其他事情,例如数据节点和应用程序 JVM 堆以及操作系统页缓存。如果在与数据节点相同的节点上运行 YARN 节点管理器进程,则还需要 YARN 容器的内存。
3.5.2.2 DataNode设置基于内存的存储
- 在每个 DataNode 节点上初始化一个 RAM 磁盘
- 通过选择 RAM 磁盘,可以在 DataNode 进程重新启动时保持更好的数据持久性
下面的设置可以在大多数 Linux 发行版上运行,目前不支持在其他平台上使用 RAM 磁盘。
3.5.3 选择tmpfs(VS ramfs)
- Linux 支持使用两种类型的 RAM 磁盘:tmpfs 和 ramfs
- tmpfs 的大小受 linux 内核的限制,而 ramfs 可以使用所有系统可用的内存
- tmpfs 可以在内存不足情况下交换到磁盘上。但是,许多对性能要求很高的应用运行时都禁用内存磁盘交换
- HDFS 当前支持 tmpfs 分区,而对 ramfs 的支持正在开发中
3.5.4 挂载RAM磁盘
- 使用 Linux 中的 mount 命令来挂载内存磁盘。例如:挂载32GB的tmpfs分区在 /mnt/dn-tmpfs
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/ - 建议在/etc/fstab创建一个入口,在 DataNode 节点重新启动时,将自动重新创建 RAM 磁盘
- 另一个可选项是使用/dev/shm下面的子目录。这是 tmpfs 默认在大多数 Linux 发行版上都可以安装
- 确保挂载的大小大于或等于dfs.datanode.max.locked.memory,或者写入到/etc /fstab
- 不建议使用多个 tmpfs 对懒持久化写入的每个 DataNode 节点进行分区
3.5.5 设置RAM_DISK存储类型tmpfs标签
- 标记 tmpfs 目录中具有 RAM_磁盘存储类型的目录
- 在hdfs-site.xml中配置dfs.datanode.data.dir。例如,在具有三个硬盘卷的 DataNode 上,/grid/0,/grid/1以及/grid/2和一个 tmpfs 挂载在/mnt/dn-tmpfs,dfs.datanode.data.dir必须设置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
- 这一步至关重要。如果没有 RAM_DISK 标记,HDFS 将把 tmpfs 卷作为非易失性存储,数据将不会保存到持久存储,重新启动节点时将丢失数据
3.5.6 确保启用存储策略
确保全局设置中的存储策略是已启用的。默认情况下,此设置是打开的。
3.5.7 使用懒持久化存储策略
- 指定 HDFS 使用 LAZY_PERSIST 策略,可以对文件使用懒持久化写入
可以通过以下三种方式之一进行设置:
3.5.7.1 在目录上执行hdfs storagepolicies命令
- 在目录上设置㽾策略,将使其对目录中的所有新文件生效
- 这个 HDFS 存储策略命令可以用于设置策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
3.5.7.2 在目录上执行setStoragePolicy方法
Apache Hadoop 2.8.0 后,应用程序可以通过编程方式将存储策略设置FileSystem.setStoragePolicy。
fs.setStoragePolicy(path, "LAZY_PERSIST");
3.5.7.3 创建文件的时候指定CreateFlag
当创建文件时,应用程序调用FileSystem.create方法,传递CreateFlag#LAZY_PERSIST实现。
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);