1. 在生产环境怎么创建队列
1)调度器默认就1个default队列,不能满足生产要求。
2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
3)按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
2. 创建多队列的好处
1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。比如双十一、618等
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
3. 需求
需求1:default队列占总内存的40%,最大资源容量占总资源60%,hive队列占总内存的60%,最大资源容量占总资源80%。
需求2:配置队列优先级
4. 配置多队列的容量调度器
1)在capacity-scheduler.xml中配置如下:
a.修改如下配置
<!-- 指定多队列,增加hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- 降低default队列资源额定容量为40%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- 降低default队列资源最大容量为60%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
b.为新加队列添加必要属性:
<!-- 指定hive队列的资源额定容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
<!-- 用户最多可以使用队列多少资源,1表示 -->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定hive队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
</property>
<!-- 启动hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<!-- 哪些用户有权向队列提交作业 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId appId -updateLifetime Timeout
参考资料:https://blog.cloudera.com/enforcing-application-lifetime-slas-yarn/ -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够指定的最大超时时间不能超过该值。 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没指定超时时间,则用default-application-lifetime作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
</property>
2)分发配置文件
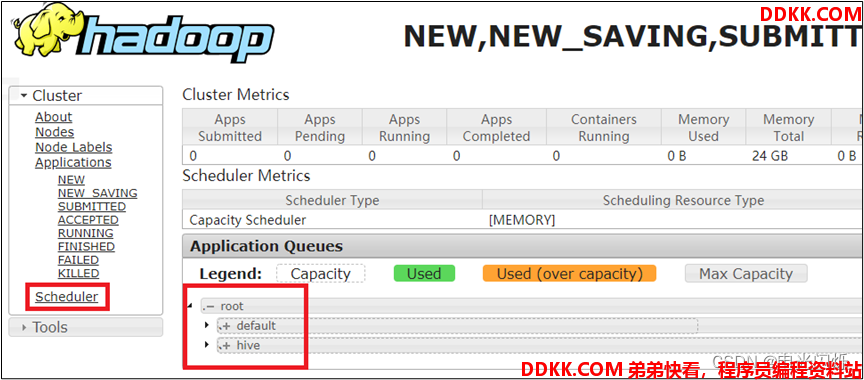
3)重启Yarn或者执行yarn rmadmin -refreshQueues刷新队列,就可以看到两条队列:
yarn rmadmin -refreshQueues
5. 向Hive队列提交任务
1)hadoop jar的方式
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
注:-D表示运行时改变参数值
2)打jar包的方式
默认的任务提交都是提交到default队列的。如果希望向其他队列提交任务,需要在Driver中声明:
public class WcDrvier {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename","hive");
//1. 获取一个Job实例
Job job = Job.getInstance(conf);
。。。 。。。
//6. 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
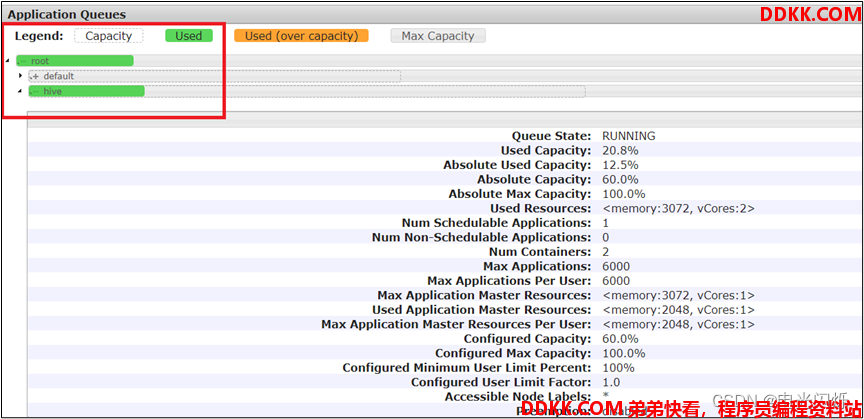
这样,这个任务在集群提交时,就会提交到hive队列:
6. 任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn将所有任务的优先级限制为0,若想使用任务的优先级功能,须开放该限制。
1)修改yarn-site.xml文件,增加以下参数
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
2)分发配置,并重启Yarn
xsync yarn-site.xml
sbin/stop-yarn.sh
sbin/start-yarn.sh
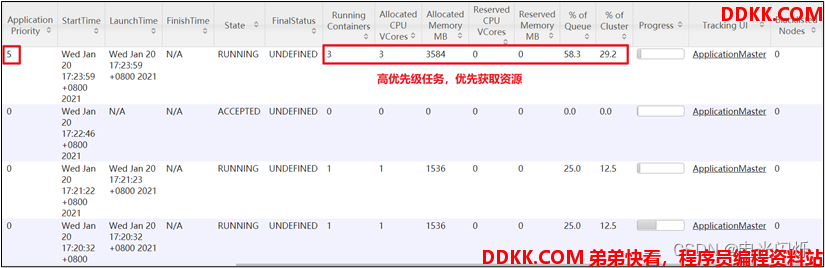
3)模拟资源紧张环境,可连续提交以下任务,直到新提交的任务申请不到资源为止。
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 2000000

4)再次重新提交优先级高的任务
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -D mapreduce.job.priority=5 5 2000000
5)也可以通过以下命令修改正在执行的任务的优先级。
yarn application -appID
yarn application -appID application_1611133087930_0009 -updatePriority 5