1. HA概述
1)所谓 HA(High Availablity), 即高可用(7*24 小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。 HA 严格来说应该分成各个组件的 HA机制: HDFS的 HA 和 YARN 的 HA。
3)NameNode 主要在以下两个方面影响 HDFS 集群
➢NameNode 机器发生意外,如宕机,集群将无法使用,直到管理员重启
➢NameNode 机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA 功能通过配置多个 NameNodes(Active/Standby)实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将 NameNode 很快的切换到另外一台机器。
2. HDFS-HA集群搭建
当前HDFS集群规划如下:
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | Secondarynamenode | |
| DataNode | DataNode | DataNode |
HA的主要目的是消除 namenode 的单点故障,需要将 hdfs 集群规划成以下模样:
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | NameNode | NameNode |
| DataNode | DataNode | DataNode |
HDFS-HA有如下4个核心问题:
1)怎么保证三台 namenode 的数据一致:
Fsimage:让一台 nn 生成数据,让其他机器 nn 同步
Edits:需要引进新的模块 JournalNode 来保证 edtis 的文件的数据一致性
2)怎么让同时只有一台 nn 是 active,其他所有是 standby 的:
a.手动分配
b.自动分配
3)2nn 在 ha 架构中并不存在,定期合并 fsimage 和 edtis 的活谁来干:
由standby 的 nn 来干
4)如果 nn 真的发生了问题,怎么让其他的 nn 上位干活:
a.手动故障转移
b.自动故障转移
3. HDFS-HA手动模式
3.1. 规划集群
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
3.2. 配置HDFS-HA集群
1)官方地址: http://hadoop.apache.org/
2)配置 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
3)配置 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>bigdata1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>bigdata2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>bigdata3:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>bigdata1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>bigdata2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>bigdata3:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/mycluster</value>
</property>
<!-- 访问代理类: client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
4)分发配置好的 hadoop 环境到其他节点
3.3. 启动HDFS-HA集群
1)将HADOOP_HOME 环境变量更改到 HA 目录(三台机器)
在/etc/profile 文件中存在如下配置信息
## HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
2)在各个 JournalNode 节点上(所有机器),输入以下命令启动 journalnode 服务
hdfs --daemon start journalnode
3)在[nn1]上(主节点),对其进行格式化, 并启动
hdfs namenode -format
hdfs --daemon start namenode

4)在[nn2]和[nn3]上(其它2台机器),同步 nn1 的元数据信息
hdfs namenode -bootstrapStandby
5)启动[nn2]和[nn3]
hdfs --daemon start namenode
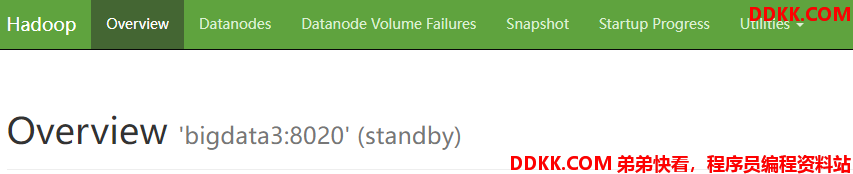
6)查看 web 页面显示


7)在所有节点上,启动 datanode
hdfs --daemon start datanode
8)将[nn1]切换为 Active
hdfs haadmin -transitionToActive nn1
9)查看是否 Active
hdfs haadmin -getServiceState nn1


4. HDFS-HA自动模式
4.1. HDFS-HA 自动故障转移工作机制
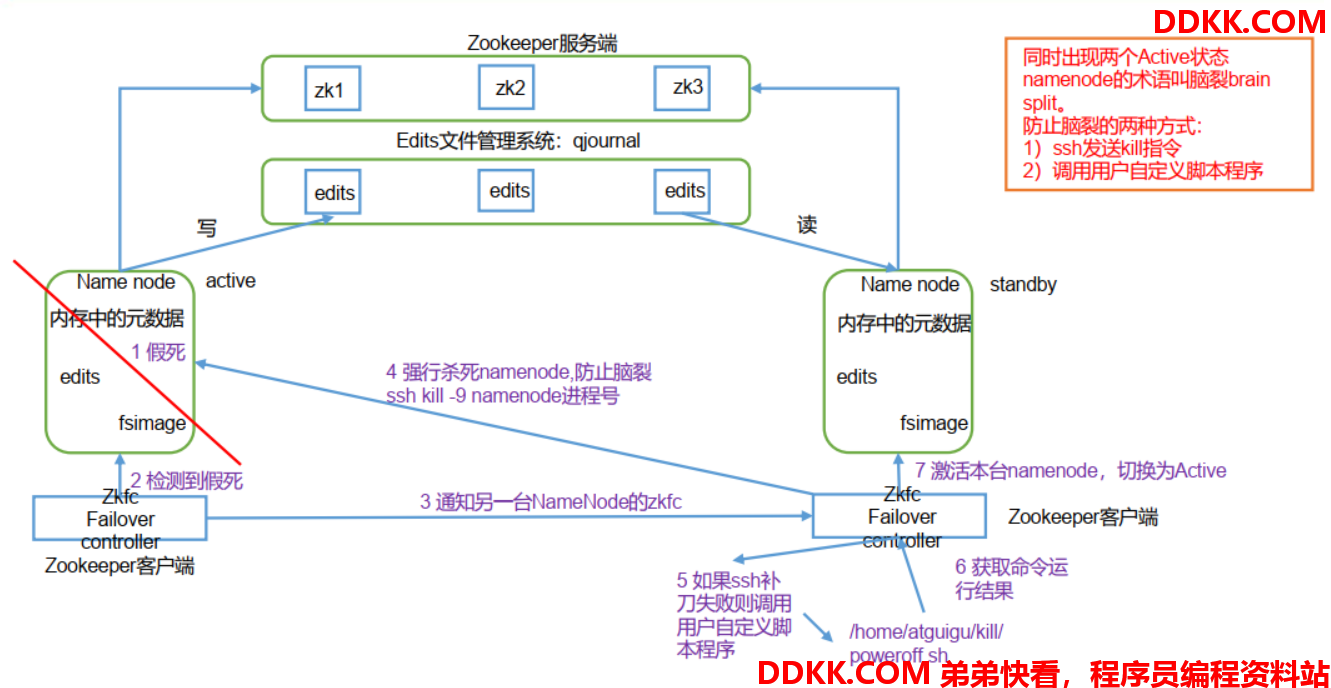
自动故障转移为 HDFS 部署增加了两个新组件: ZooKeeper 和 ZKFailoverController(ZKFC)进程,如图所示。 ZooKeeper 是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。
4.2. HDFS-HA 自动故障转移的集群规划
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
4.3. 配置 HDFS-HA 自动故障转移
4.3.1. 具体配置
1)在hdfs-site.xml 中增加
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2)在core-site.xml 文件中增加
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value>
</property>
3)修改后分发配置文件
4.3.2. 启动
1)关闭HDFS所有服务:
# 在主节点上执行如下命令
stop-dfs.sh
注意:执行此命令时会有如下错误
[root@bigdata1 name]# stop-dfs.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Stopping namenodes on [bigdata1 bigdata2 bigdata3]
上一次登录:二 3月 29 20:30:09 CST 2022从 192.168.12.1pts/0 上
Stopping datanodes
上一次登录:二 3月 29 21:33:27 CST 2022pts/0 上
Stopping journal nodes [bigdata1 bigdata3 bigdata2]
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Stopping ZK Failover Controllers on NN hosts [bigdata1 bigdata2 bigdata3]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.

此时需要在 hadoop-env.sh 脚本中,增加如下字段(是所有机器的该脚本都需要):
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root

再次执行 stop-dfs.sh 命令,停止成功:

2)启动 Zookeeper 集群:
# 在所有Zookeeper节点上执行如下命令
zkServer.sh start
# 或者执行启动脚本(在bigdata1主节点上执行如下命令)
sh zk.sh start
3)启动 Zookeeper 以后, 然后再初始化 HA 在 Zookeeper 中状态:
hdfs zkfc -formatZK
此时会发现Zookeeper中有个 hadoop-ha 目录,如下图:

4)启动 HDFS 服务:
start-dfs.sh
5)可以去 zkCli.sh 客户端查看 Namenode 选举锁节点内容:
get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
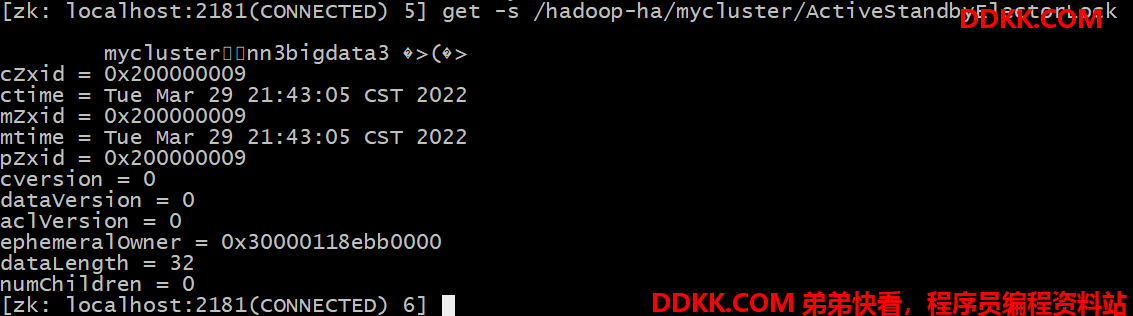
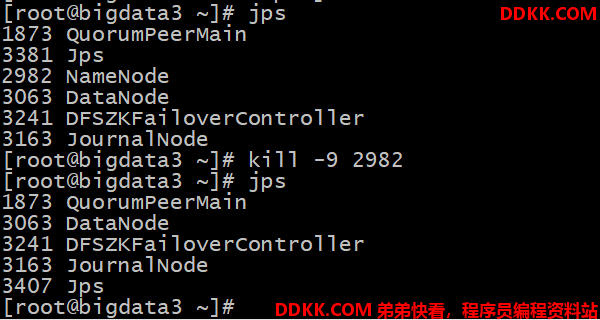
4.3.3. 验证
将Active NameNode 进程 kill,查看网页端三台 Namenode 的状态变化

4.4. 解决 NN 连接不上 JN 的问题
自动故障转移配置好以后,然后使用 start-dfs.sh 群起脚本启动 hdfs 集群,有可能会遇到 NameNode 起来一会后,进程自动关闭的问题。查看 NameNode 日志,报错信息如下:
2020-08-17 10:11:40,658 INFO org.apache.hadoop.ipc.Client: Retrying connectto server: bigdata3/192.168.6.104:8485. Already tried 0 time(s); retrypolicy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10,sleepTime=1000 MILLISECONDS)
2020-08-17 10:11:40,659 INFO org.apache.hadoop.ipc.Client: Retrying connectto server: bigdata1/192.168.6.102:8485. Already tried 0 time(s); retrypolicy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10,sleepTime=1000 MILLISECONDS)
2020-08-17 10:11:40,659 INFO org.apache.hadoop.ipc.Client: Retrying connectto server: bigdata2/192.168.6.103:8485. Already tried 0 time(s); retrypolicy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10,sleepTime=1000 MILLISECONDS)
查看报错日志,可分析出报错原因是因为 NameNode 连接不上 JournalNode,而利用 jps 命令查看到三台 JN 都已经正常启动,为什么 NN 还是无法正常连接到 JN 呢?这是因为 start-dfs.sh 群起脚本默认的启动顺序是先启动 NN,再启动 DN,然后再启动 JN,并且默认的 rpc 连接参数是重试次数为 10,每次重试的间隔是 1s,也就是说启动完 NN以后的 10s 中内, JN 还启动不起来, NN 就会报错了。
core-default.xml 里面有两个参数如下:
<!-- NN 连接 JN 重试次数,默认是 10 次 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
</property>
<!-- 重试时间间隔,默认 1s -->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>1000</value>
</property>
解决方案:遇到上述问题后,可以稍等片刻,等 JN 成功启动后,手动启动下三台
hdfs --daemon start namenode
也可以在 core-site.xml 里面适当调大上面的两个参数:
<!-- NN 连接 JN 重试次数,默认是 10 次 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>20</value>
</property>
<!-- 重试时间间隔,默认 1s -->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
</property>
5. YARN-HA 配置
5.1. YARN-HA 配置
1)官方文档:Apache Hadoop 3.1.3 – ResourceManager High Availability
2)YARN-HA 工作机制
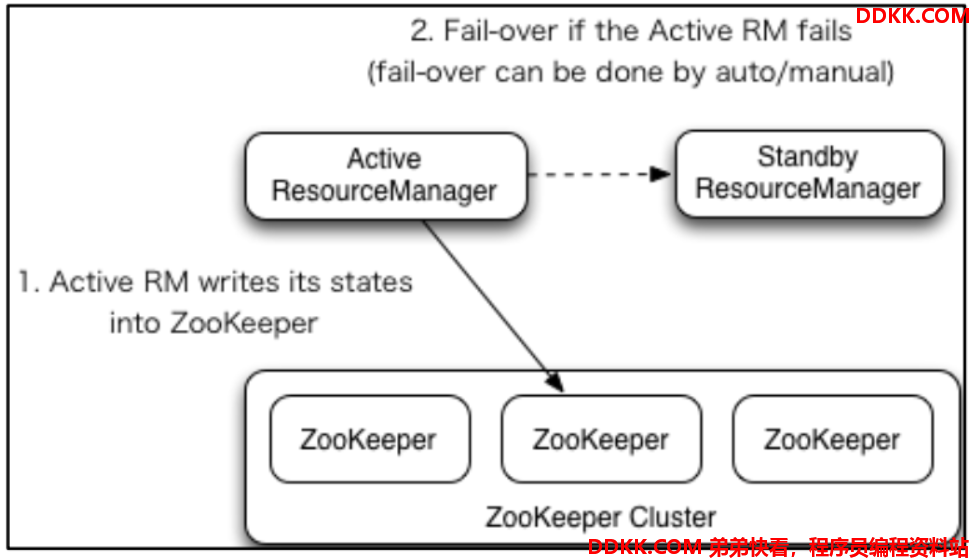
5.2. 配置YARN-HA集群
1)环境准备:根据普通YARN集群环境和安装Zookeeper环境即可
2)规划集群
| bigdata1 | bigdata2 | bigdata3 |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper |
3)核心问题
- 如果当前 active rm 挂了,其他 rm 怎么将其他 standby rm 上位,核心原理跟 hdfs 一样,利用了 zk 的临时节点
- 当前 rm 上有很多的计算程序在等待运行,其他的 rm 怎么将这些程序接手过来接着跑rm 会将当前的所有计算程序的状态存储在 zk 中,其他 rm 上位后会去读取,然后接着跑
4)具体配置(yarn-site.xml 配置)
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata1</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>bigdata1:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>bigdata1:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>bigdata1:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>bigdata1:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>bigdata2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>bigdata2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>bigdata2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>bigdata2:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>bigdata3</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>bigdata3:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>bigdata3:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>bigdata3:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>bigdata3:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
5)同步更新其他节点的配置信息,分发配置文件
xsync /opt/module/hadoop/etc/hadoop/*
6)在bigdata1 中执行如下命令,启动YARN:
start-yarn.sh

会发现启动报错,通过查看logs目录下的日志报错信息如下:
2022-03-29 22:05:43,253 INFO org.apache.hadoop.service.AbstractService: Service RMActiveServices failed in state INITED
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2670)
at org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStoreFactory.getStore(RMStateStoreFactory.java:31)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$RMActiveServices.serviceInit(ResourceManager.java:682)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.createAndInitActiveServices(ResourceManager.java:1224)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:318)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1506)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2662)
... 7 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
2022-03-29 22:05:43,256 INFO org.apache.hadoop.service.AbstractService: Service ResourceManager failed in state INITED
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2670)
at org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStoreFactory.getStore(RMStateStoreFactory.java:31)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$RMActiveServices.serviceInit(ResourceManager.java:682)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.createAndInitActiveServices(ResourceManager.java:1224)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:318)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1506)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2662)
... 7 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
2022-03-29 22:05:43,256 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state
2022-03-29 22:05:43,257 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioned to standby state
2022-03-29 22:05:43,257 FATAL org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManager
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2670)
at org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStoreFactory.getStore(RMStateStoreFactory.java:31)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$RMActiveServices.serviceInit(ResourceManager.java:682)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.createAndInitActiveServices(ResourceManager.java:1224)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:318)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1506)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2662)
... 7 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
2022-03-29 22:05:43,259 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down ResourceManager at bigdata1/192.168.12.131
此时可以在 yarn-site.xml 配置文件中添加如下配置:
<!-- ZK中ZNode节点能存储的最大数据量,以字节为单位,默认是 1048576 字节,也就是1MB,现在扩大100倍 -->
<property>
<name>yarn.resourcemanager.zk-max-znode-size.bytes</name>
<value>104857600</value>
</property>
<!--用于状态存储的类,可以设置为-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
然后重新启动 yarn,发现启动成功
7)查看服务状态
yarn rmadmin -getServiceState rm1

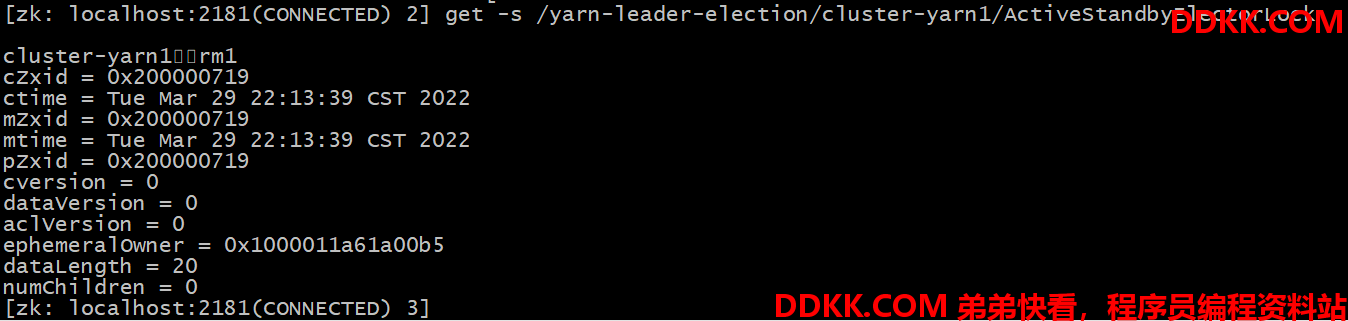
8)可以去 zkCli.sh 客户端查看 ResourceManager 选举锁节点内容:
get -s /yarn-leader-election/cluster-yarn1/ActiveStandbyElectorLock
9)web 端查看 hadoop102:8088 和 hadoop103:8088 的 YARN 的状态
6. Hadoop HA 的最终规划
将整个ha 搭建完成后,集群将形成以下模样
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |