一、转换算子
1.1 map
从如下图解可以看到,map是一对一的操作,对dataStream中的计算,一对一输出

DataStream<Integer> mapStram = dataStream.map(new MapFunction<String, Integer>() {
public Integer map(String value) throws Exception {
return value.length();
}
});
1.2 flatMap
flatMap是一个输入,多个输出,例如通过"," 分隔符将
DataStream<String> flatMapStream = dataStream.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String value, Collector<String> out) throws Exception {
String[] fields = value.split(",");
for( String field: fields )
out.collect(field);
}
});
1.3 Filter
Filter可以理解为SQL语句中的where子句,过滤数据用的

DataStream<Interger> filterStream = dataStream.filter(new FilterFunction<String>() {
public boolean filter(String value) throws Exception {
return value == 1;
}
});
二、代码
数据准备:
sensor.txt
sensor_1 1547718199 35.8
sensor_6 1547718201, 15.4
sensor_7 1547718202, 6.7
sensor_10 1547718205 38.1
代码:
package org.flink.transform;
/**
* @remark Flink 基础Transform map、flatMap、filter
*/
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransformTest1_Base {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从文件读取数据
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 1. map,把String转换成长度输出
DataStream<Integer> mapStream = inputStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return value.length();
}
});
// 2. flatmap,按逗号分字段
DataStream<String> flatMapStream = inputStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] fields = value.split(",");
for( String field: fields )
out.collect(field);
}
});
// 3. filter, 筛选sensor_1开头的id对应的数据
DataStream<String> filterStream = inputStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("sensor_1");
}
});
// 打印输出
mapStream.print("map");
flatMapStream.print("flatMap");
filterStream.print("filter");
env.execute();
}
}
运行结果:
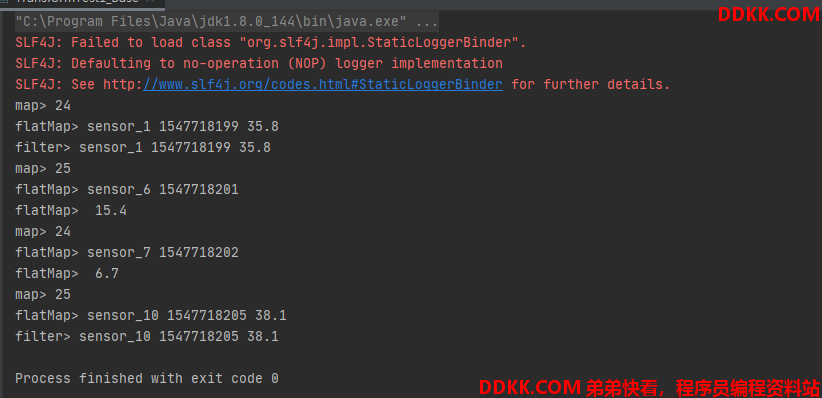
Flink是基于数据流的处理,所以是来一条处理一条,由于并行度是1所以3个算子计算一个就输出一个。
这里,我把并行度改为2,再来看输出,就可以看到输出不一样了。