一、 Flink CDC介绍
Flink在1.11版本中新增了CDC的特性,简称 改变数据捕获。名称来看有点乱,我们先从之前的数据架构来看CDC的内容。
以上是之前的mysql binlog日志处理流程,例如canal监听binlog把日志写入到kafka中。而Apache Flink实时消费Kakfa的数据实现mysql数据的同步或其他内容等。拆分来说整体上可以分为以下几个阶段。
1、 mysql开启binlog;
2、 canal同步binlog数据写入到kafka;
3、 flink读取kakfa中的binlog数据进行相关的业务处理;
整体的处理链路较长,需要用到的组件也比较多。Apache Flink CDC可以直接从数据库获取到binlog供下游进行业务计算分析。简单来说链路会变成这样
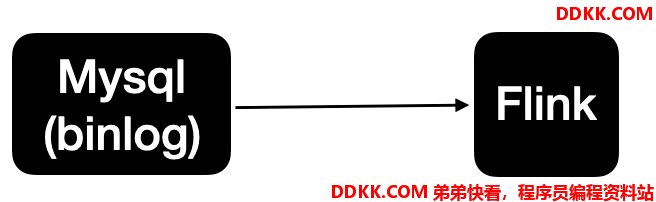
也就是说数据不再通过canal与kafka进行同步,而flink直接进行处理mysql的数据。节省了canal与kafka的过程。
Flink 1.11中实现了mysql-cdc与postgre-CDC,也就是说在Flink 1.11中我们可以直接通过Flink来直接消费mysql,postgresql的数据进行业务的处理。
使用场景:
1、 数据库数据的增量同步;
2、 数据库表之上的物理化视图;
3、 维表join;
4、 其他业务处理;
二、Flink CDC 实操
2.1 MySQL配置
MySQL必须开启binlog
MySQL表必须有主键
mysql> show variables like '%log_bin%';
+---------------------------------+---------------------------------------------+
| Variable_name | Value |
+---------------------------------+---------------------------------------------+
| log_bin | ON |
| log_bin_basename | /home/mysql/data/3306/10-31-1-122-bin |
| log_bin_index | /home/mysql/data/3306/10-31-1-122-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+---------------------------------------------+
6 rows in set (0.01 sec)
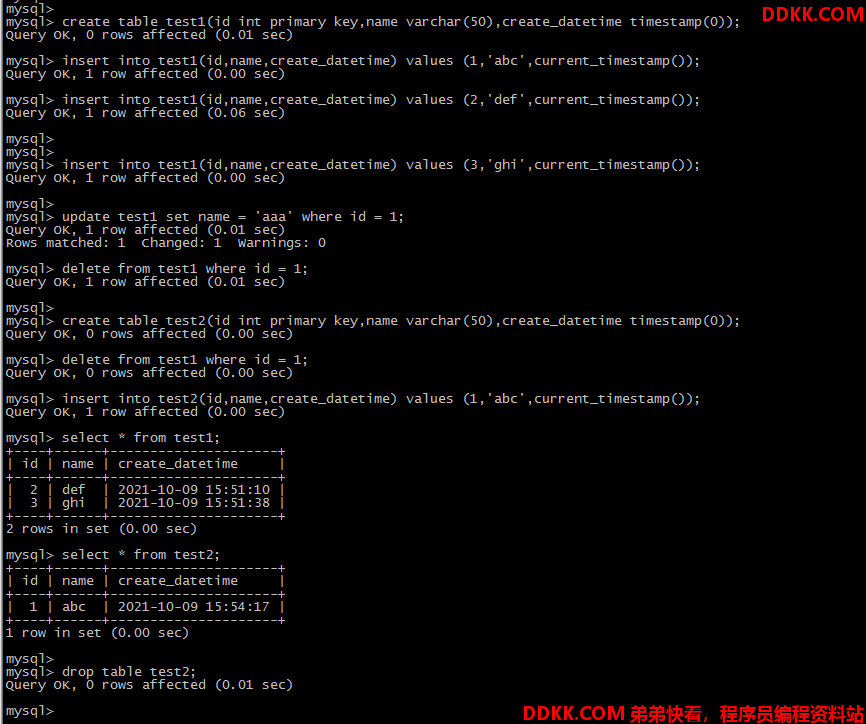
MySQL代码:
create databases cdc_test;
create table test1(id int primary key,name varchar(50),create_datetime timestamp(0));
insert into test1(id,name,create_datetime) values (1,'abc',current_timestamp());
insert into test1(id,name,create_datetime) values (2,'def',current_timestamp());
insert into test1(id,name,create_datetime) values (3,'ghi',current_timestamp());
update test1 set name = 'aaa' where id = 1;
delete from test1 where id = 1;
create table test2(id int primary key,name varchar(50),create_datetime timestamp(0));
delete from test1 where id = 1;
insert into test2(id,name,create_datetime) values (1,'abc',current_timestamp());
drop table test2;
2.2 pom文件
pom文件配置如下:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
<type>test-jar</type>
</dependency>
</dependencies>
2.3 Java代码
CdcDwdDeserializationSchema
package com.zqs.study.flink.cdc;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CdcDwdDeserializationSchema implements DebeziumDeserializationSchema<JSONObject> {
private static final long serialVersionUID = -3168848963265670603L;
public CdcDwdDeserializationSchema() {
}
@Override
public void deserialize(SourceRecord record, Collector<JSONObject> out) {
Struct dataRecord = (Struct) record.value();
Struct afterStruct = dataRecord.getStruct("after");
Struct beforeStruct = dataRecord.getStruct("before");
/*
todo 1,同时存在 beforeStruct 跟 afterStruct数据的话,就代表是update的数据
2,只存在 beforeStruct 就是delete数据
3,只存在 afterStruct数据 就是insert数据
*/
JSONObject logJson = new JSONObject();
String canal_type = "";
List<Field> fieldsList = null;
if (afterStruct != null && beforeStruct != null) {
System.out.println("这是修改数据");
canal_type = "update";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else if (afterStruct != null) {
System.out.println("这是新增数据");
canal_type = "insert";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else if (beforeStruct != null) {
System.out.println("这是删除数据");
canal_type = "detele";
fieldsList = beforeStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = beforeStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else {
System.out.println("一脸蒙蔽了");
}
//todo 拿到databases table信息
Struct source = dataRecord.getStruct("source");
Object db = source.get("db");
Object table = source.get("table");
Object ts_ms = source.get("ts_ms");
logJson.put("canal_database", db);
logJson.put("canal_database", table);
logJson.put("canal_ts", ts_ms);
logJson.put("canal_type", canal_type);
//todo 拿到topic
String topic = record.topic();
System.out.println("topic = " + topic);
//todo 主键字段
Struct pk = (Struct) record.key();
List<Field> pkFieldList = pk.schema().fields();
int partitionerNum = 0;
for (Field field : pkFieldList) {
Object pkValue = pk.get(field.name());
partitionerNum += pkValue.hashCode();
}
int hash = Math.abs(partitionerNum) % 3;
logJson.put("pk_hashcode", hash);
out.collect(logJson);
}
@Override
public TypeInformation<JSONObject> getProducedType() {
return BasicTypeInfo.of(JSONObject.class);
}
}
FlinkCDCSQLTest
package com.zqs.study.flink.cdc;
/**
* @remark Flink CDC 测试
*/
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class FlinkCDCSQLTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SourceFunction<JSONObject> sourceFunction = MySQLSource.<JSONObject>builder()
.hostname("10.31.1.122")
.port(3306)
.databaseList("cdc_test") // monitor all tables under inventory database
.username("root")
//.password("abc123")
.password("Abc123456!")
.deserializer(new CdcDwdDeserializationSchema()) // converts SourceRecord to String
.build();
DataStreamSource<JSONObject> stringDataStreamSource = env.addSource(sourceFunction);
stringDataStreamSource.print("===>");
try {
env.execute("测试mysql-cdc");
} catch (Exception e) {
e.printStackTrace();
}
}
}
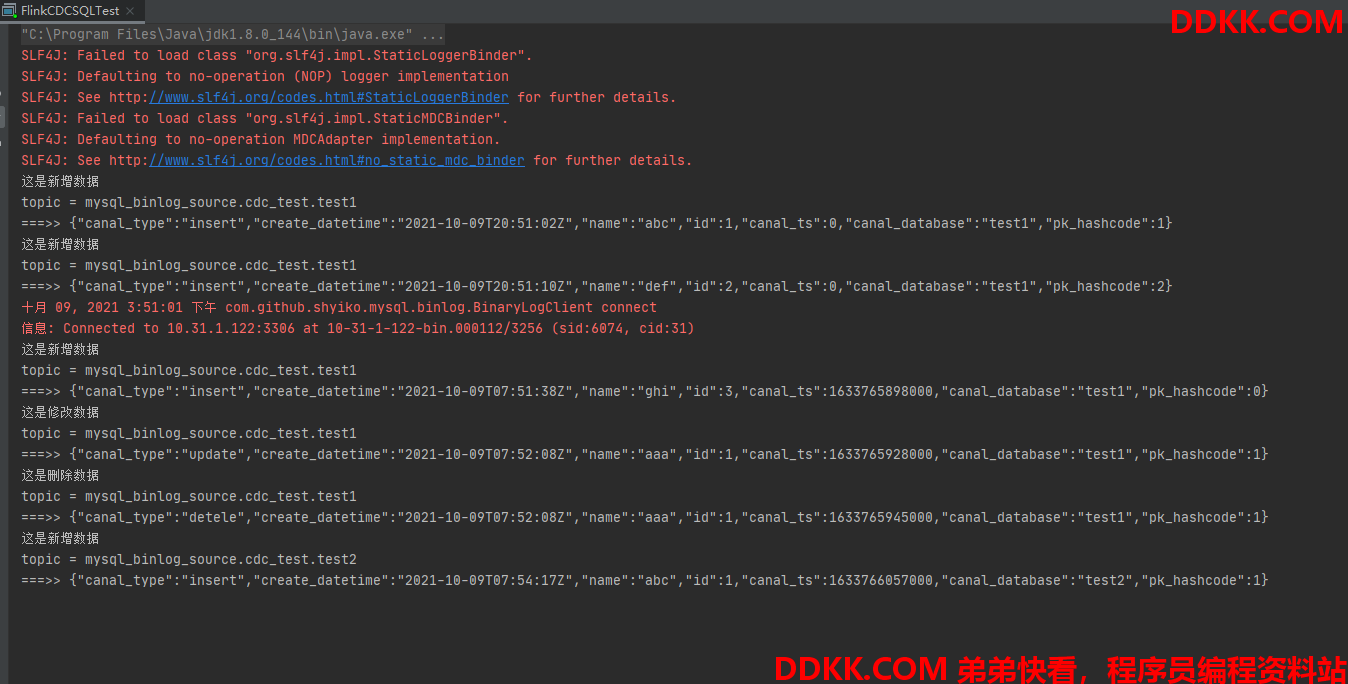
2.4 测试结果
如下截图所示,可以捕捉到DML语句,但是无法捕捉到DDL语句