环境介绍
测试服务器CDH 6.3.1版本安装Flink 1.9版本。
hello.txt文件
hello word
hello hdfs
hello mapreduce
hello yarn
hello hive
hello spark
hello flink
一、Maven配置
Flink依赖的配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
因为是本地写Java代码,要打包成jar文件,然后上传到服务器后运行,要设置主入口,不然会报错
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>org.example.wordCount</mainClass> <!-- 此处为主入口-->
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
其中org.example.wordCount 需要自己调整
org.example 是包名
wordCount 是类名
二、Java代码编写
如下:
package org.example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
/*
* @remark Flink的第一个wordCount程序
*/
public class wordCount {
public static void main(String[] args) throws Exception{
//创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
String inputPath = "hdfs://hp1:8020/user/hive/warehouse/hello.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第一个位置的word分组
.sum(1); // 将第二个位置上的数据求和;
resultSet.print();
//env.execute();
//env.execute("Word Count Example");
}
//自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//按空格分词
String[] words = value.split(" ");
//遍历所有word,包成二元组输出
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
三、Maven打包并上传
通过mvn package命令打包
C:\Users\Administrator\IdeaProjects\FlinkStudy>mvn package
[INFO] Scanning for projects...
[WARNING]
[WARNING] Some problems were encountered while building the effective model for org.example:FlinkStudy:jar:1.0-SNAPSHOT
[WARNING] 'build.pluginManagement.plugins.plugin.(groupId:artifactId)' must be unique but found duplicate declaration of plugin org.apache.maven.plugins:maven-compiler-plugin @ line 98, column 17
[WARNING] 'build.pluginManagement.plugins.plugin.(groupId:artifactId)' must be unique but found duplicate declaration of plugin org.apache.maven.plugins:maven-surefire-plugin @ line 107, column 17
[WARNING] 'build.pluginManagement.plugins.plugin.(groupId:artifactId)' must be unique but found duplicate declaration of plugin org.apache.maven.plugins:maven-jar-plugin @ line 116, column 17
[WARNING]
[WARNING] It is highly recommended to fix these problems because they threaten the stability of your build.
[WARNING]
[WARNING] For this reason, future Maven versions might no longer support building such malformed projects.
[WARNING]
[INFO]
[INFO] -----------------------< org.example:FlinkStudy >-----------------------
[INFO] Building FlinkStudy 1.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] --- maven-resources-plugin:3.0.2:resources (default-resources) @ FlinkStudy ---
[INFO] Using 'UTF-8' encoding to copy filtered resources.
[INFO] Copying 0 resource
[INFO]
[INFO] --- maven-compiler-plugin:3.6.0:compile (default-compile) @ FlinkStudy ---
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 2 source files to C:\Users\Administrator\IdeaProjects\FlinkStudy\target\classes
[INFO]
[INFO] --- maven-resources-plugin:3.0.2:testResources (default-testResources) @ FlinkStudy ---
[INFO] Using 'UTF-8' encoding to copy filtered resources.
[INFO] Copying 0 resource
[INFO]
[INFO] --- maven-compiler-plugin:3.6.0:testCompile (default-testCompile) @ FlinkStudy ---
[INFO] Nothing to compile - all classes are up to date
[INFO]
[INFO] --- maven-surefire-plugin:2.19:test (default-test) @ FlinkStudy ---
[INFO] Tests are skipped.
[INFO]
[INFO] --- maven-jar-plugin:3.0.2:jar (default-jar) @ FlinkStudy ---
[INFO] Building jar: C:\Users\Administrator\IdeaProjects\FlinkStudy\target\FlinkStudy-1.0-SNAPSHOT.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1.848 s
[INFO] Finished at: 2021-08-25T09:41:03+08:00
[INFO] ------------------------------------------------------------------------
C:\Users\Administrator\IdeaProjects\FlinkStudy>
然后将生产的FlinkStudy-1.0-SNAPSHOT.jar文件上传到服务器
四、运行jar文件
命令:
flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 /home/flink/FlinkStudy-1.0-SNAPSHOT.jar
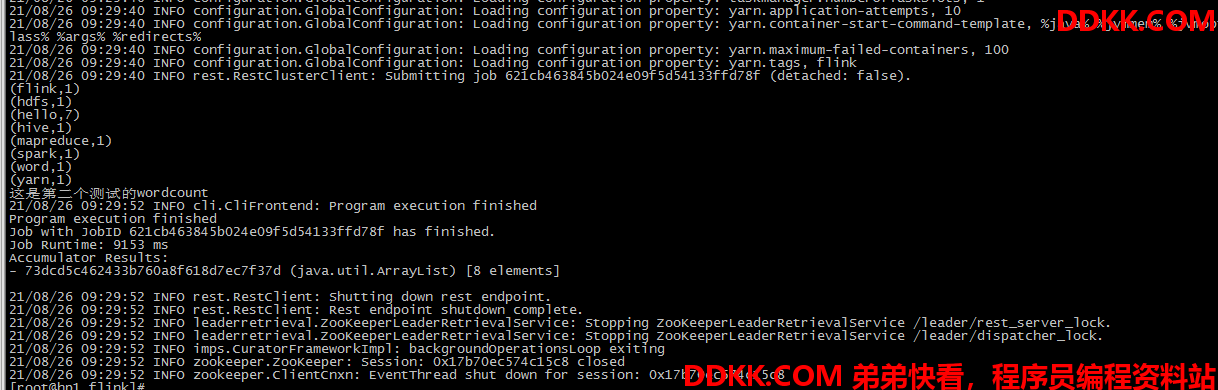
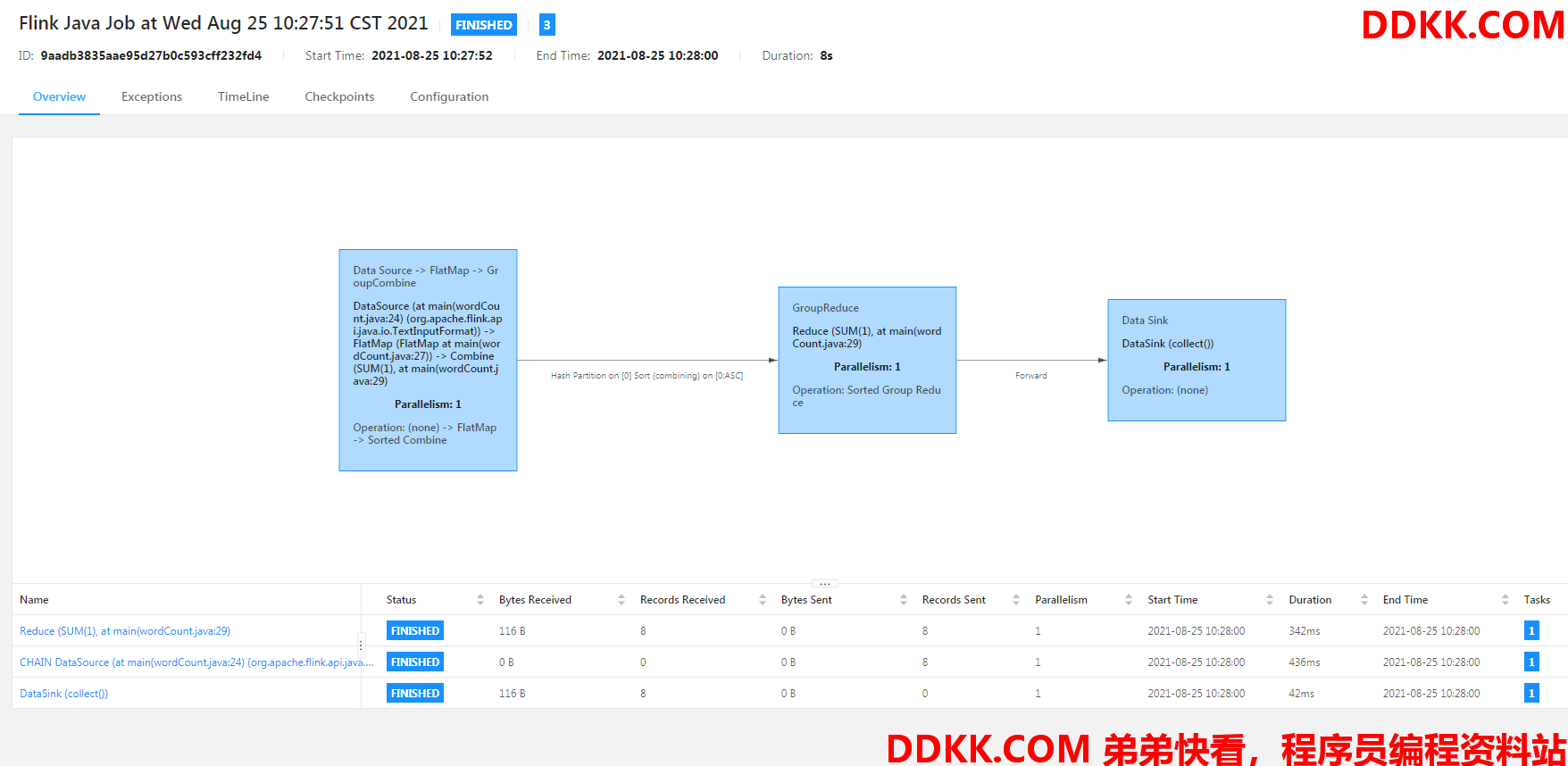
运行结果:
Web界面显示执行结果:
五、运行其它的class文件
虽然我们pom文件指定了main class,如果不指定对应的class,就执行pom文件里面指定的class,如果我们想执行该工程下其它class文件怎么办?这个时候我们需要用 -c 或者–class命令来指定对应的class文件
代码:
package org.example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
/*
* @remark Flink的第二个wordCount程序
*/
public class wordCount2 {
public static void main(String[] args) throws Exception{
//创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
String inputPath = "hdfs://hp1:8020/user/hive/warehouse/hello.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第一个位置的word分组
.sum(1); // 将第二个位置上的数据求和;
resultSet.print();
//env.execute();
//env.execute("Word Count Example");
System.out.println("这是第二个测试的wordcount");
}
//自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//按空格分词
String[] words = value.split(" ");
//遍历所有word,包成二元组输出
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
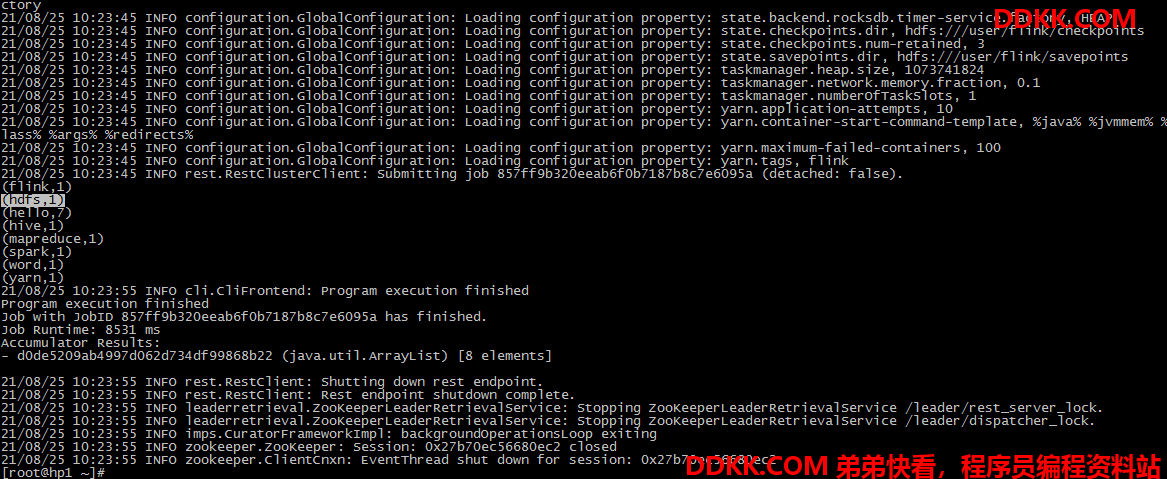
运行命令:
-- 正确
flink run -m yarn-cluster -c org.example.wordCount2 FlinkStudy-1.0-SNAPSHOT.jar
-- 正确
flink run -m yarn-cluster --class org.example.wordCount2 FlinkStudy-1.0-SNAPSHOT.jar
--错误(依旧执行pom文件里面的main class)
flink run -m yarn-cluster FlinkStudy-1.0-SNAPSHOT.jar -c org.example.wordCount2
执行截图: