一、多流转换算子概述
多流转换算子一般包括:
Split和Select (新版已经移除)
Connect和CoMap
Union
1.1 Split和Select
注:新版Flink已经不存在Split和Select这两个API了(至少Flink1.12.1没有!)
Split
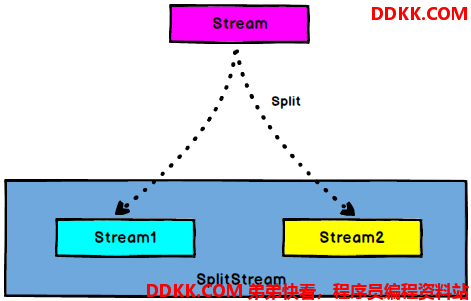
DataStream -> SplitStream:根据某些特征把DataStream拆分成SplitStream;
SplitStream虽然看起来像是两个Stream,但是其实它是一个特殊的Stream;
Select
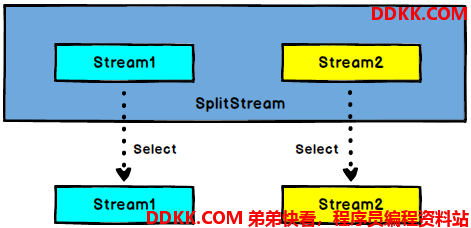
SplitStream -> DataStream:从一个SplitStream中获取一个或者多个DataStream;
我们可以结合split&select将一个DataStream拆分成多个DataStream。
1.2 Connect和CoMap
Connect
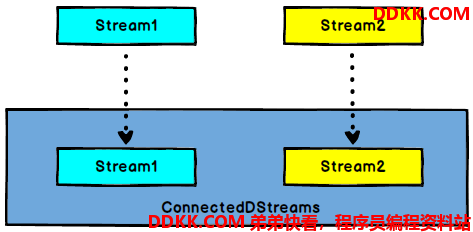
DataStream,DataStream -> ConnectedStreams: 连接两个保持他们类型的数据流,两个数据流被Connect 之后,只是被放在了一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
CoMap
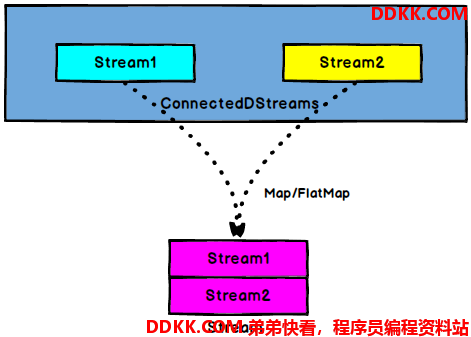
ConnectedStreams -> DataStream: 作用于ConnectedStreams 上,功能与map和flatMap一样,对ConnectedStreams 中的每一个Stream分别进行map和flatMap操作;
1.3 Union
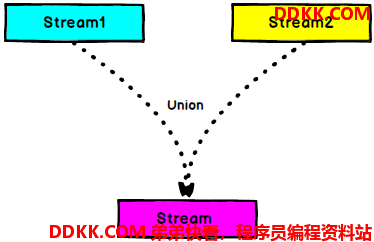
DataStream -> DataStream:对两个或者两个以上的DataStream进行Union操作,产生一个包含多有DataStream元素的新DataStream。
问题:和Connect的区别?
1、 Connect的数据类型可以不同,Connect只能合并两个流;
2、 Union可以合并多条流,Union的数据结构必须是一样的;
二、代码实现
数据准备:
sensor.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718209,32.8
sensor_1,1547718212,37.1
代码:
package org.flink.transform;
/**
* @remark Flink 基础Transform MultipleStreams
*/
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Collections;
public class TransformTest4_MultipleStreams {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从文件读取数据
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 转换成SensorReading
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
} );
// 1. 分流,按照温度值30度为界分为两条流
SplitStream<SensorReading> splitStream = dataStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading value) {
return (value.getTemperature() > 30) ? Collections.singletonList("high") : Collections.singletonList("low");
}
});
DataStream<SensorReading> highTempStream = splitStream.select("high");
DataStream<SensorReading> lowTempStream = splitStream.select("low");
DataStream<SensorReading> allTempStream = splitStream.select("high", "low");
highTempStream.print("high");
lowTempStream.print("low");
allTempStream.print("all");
// 2. 合流 connect,将高温流转换成二元组类型,与低温流连接合并之后,输出状态信息
DataStream<Tuple2<String, Double>> warningStream = highTempStream.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), value.getTemperature());
}
});
ConnectedStreams<Tuple2<String, Double>, SensorReading> connectedStreams = warningStream.connect(lowTempStream);
DataStream<Object> resultStream = connectedStreams.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> value) throws Exception {
return new Tuple3<>(value.f0, value.f1, "high temp warning");
}
@Override
public Object map2(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), "normal");
}
});
resultStream.print();
// 3. union联合多条流
// warningStream.union(lowTempStream);
highTempStream.union(lowTempStream, allTempStream);
env.execute();
}
}
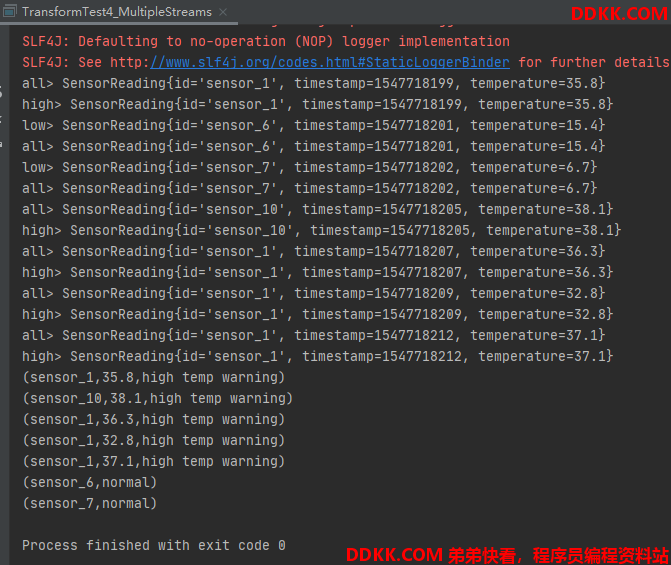
测试记录: