一、 项目剖析
基本需求:
统计近1小时内的热门商品,每5分钟更新一次
热门度用浏览次数(“pv”)来衡量
解决思路
在所有用户行为数据中,过滤出浏览(“pv”)行为进行统计
构建滑动窗口,窗口长度为1小时,滑动距离为5分钟
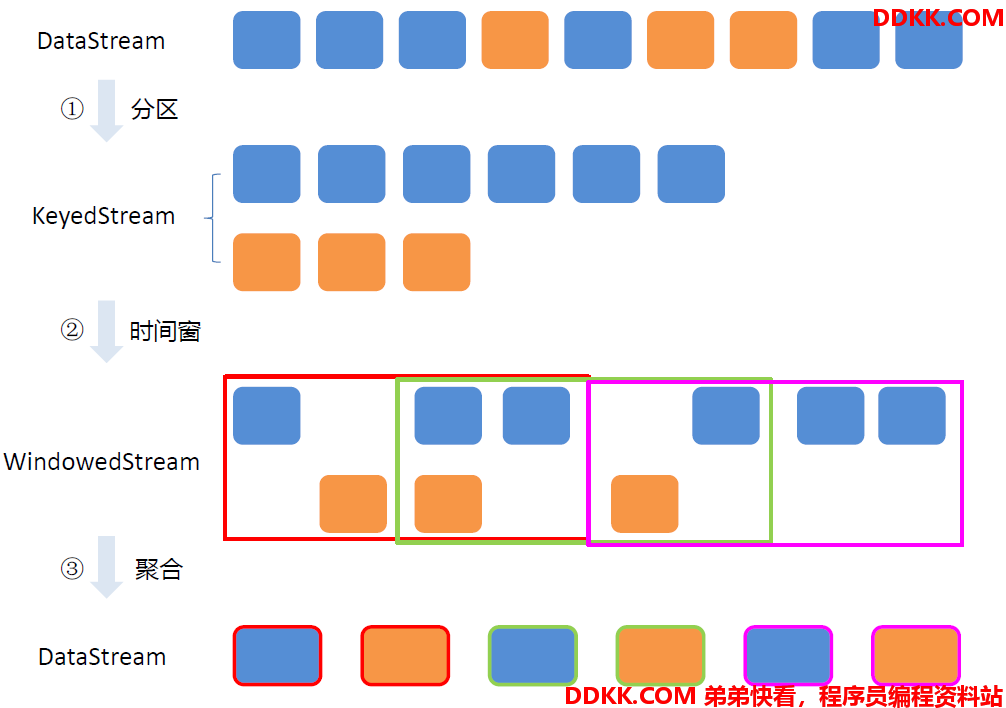
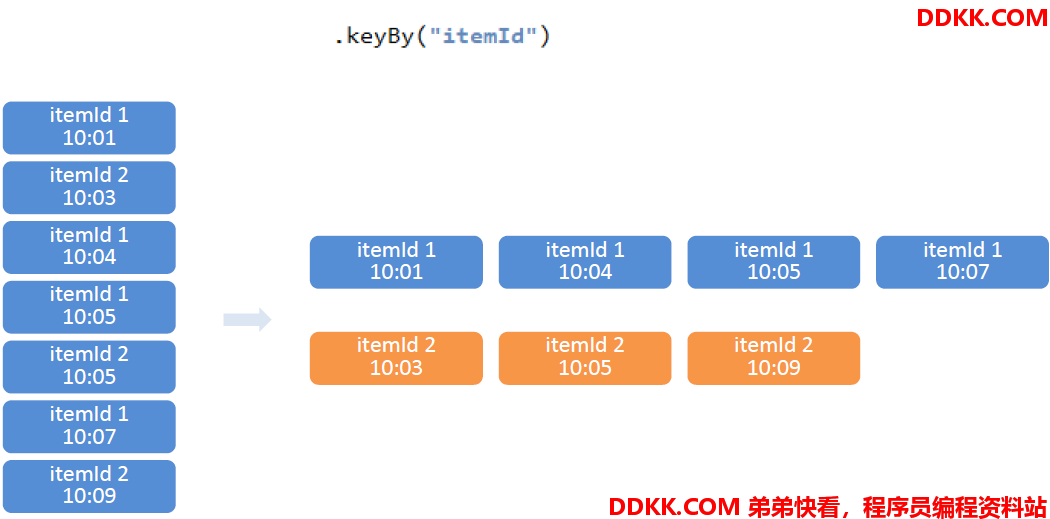
按照商品Id进行分区
设置时间窗口
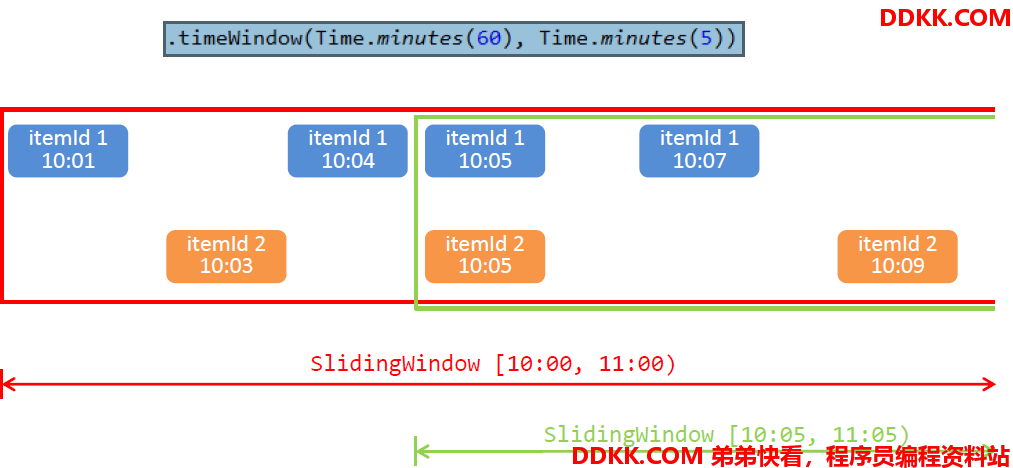
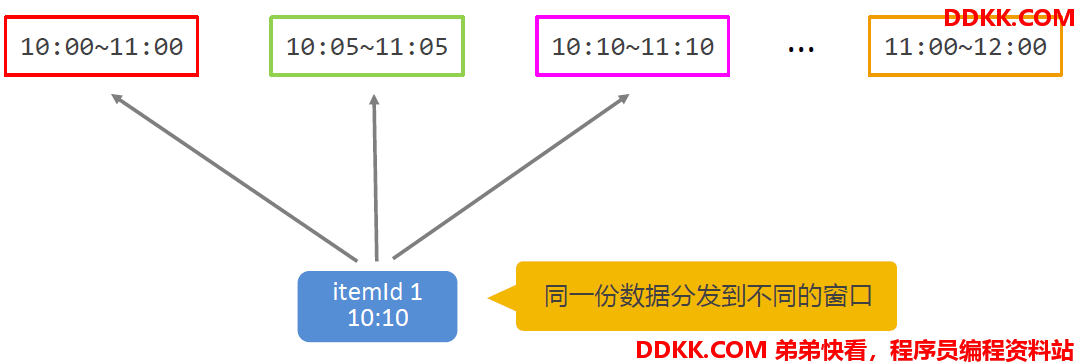
时间窗口(timeWindow)区间为左闭右开
同一份数据会被分发到不同的窗口
窗口聚合

窗口聚合策略——每出现一条记录就加一

实现 AggregateFunction 接口
in t e r f a c e A g g r e g a t e F u n c t i o n < I N , A C C , O U T > \color{red}{interface AggregateFunction<IN, ACC, OUT>} interfaceAggregateFunction<IN,ACC,OUT>
定义输出结构 —— ItemViewCount(itemId, windowEnd, count)
实现 WindowFunction 接口
in t e r f a c e W i n d o w F u n c t i o n < I N , O U T , K E Y , W e x t e n d s W i n d o w > \color{red}{interface WindowFunction<IN, OUT, KEY, W extends Window>} interfaceWindowFunction<IN,OUT,KEY,WextendsWindow>
•IN: 输入为累加器的类型,Long
•OUT: 窗口累加以后输出的类型为 ItemViewCount(itemId: Long, windowEnd: Long, count: Long), windowEnd为窗口的 结束时间,也是窗口的唯一标识
•KEY: Tuple泛型,在这里是 itemId,窗口根据itemId聚合
•W: 聚合的窗口,w.getEnd 就能拿到窗口的结束时间
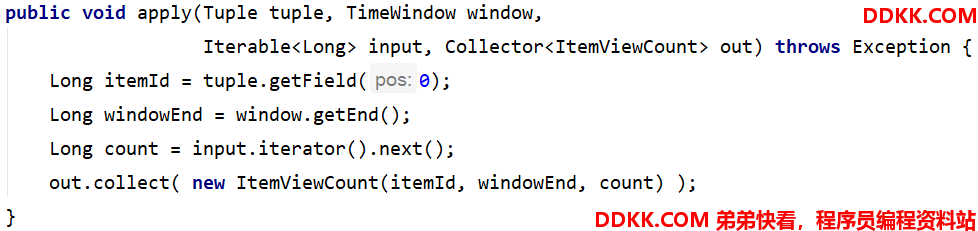
窗口聚合示例
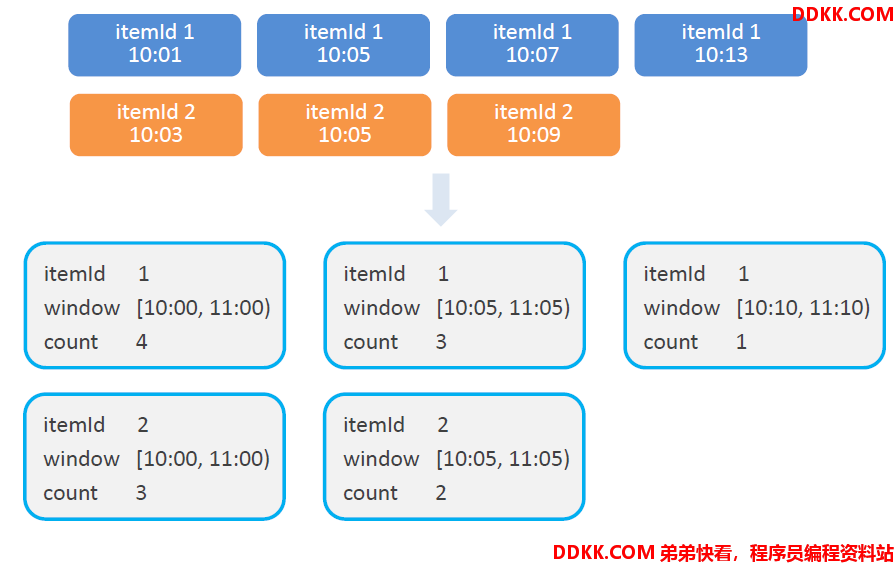
进行统计整理 —— keyBy(“windowEnd”)

状态编程
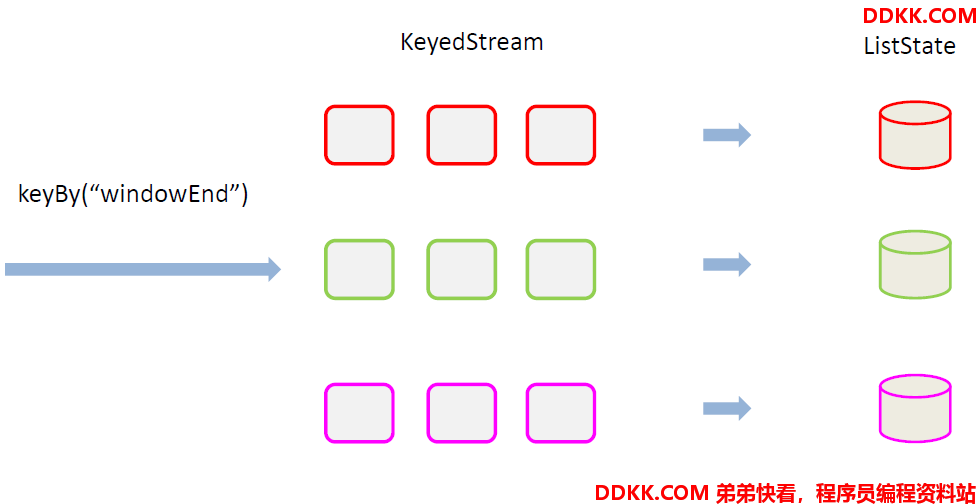
最终排序输出——keyedProcessFunction
1、 针对有状态流的底层API;
2、 KeyedProcessFunction会对分区后的每一条子流进行处理;
3、 以windowEnd作为key,保证分流以后每一条流的数据都在一个时间窗口内;
4、 从ListState中读取当前流的状态,存储数据进行排序输出;
用ProcessFunction定义KeyedStream的处理逻辑
分区之后,每个KeyedStream都有其自己的生命周期
1、 open:初始化,在这里可以获取当前流的状态;
2、 processElement:处理流中每一个元素时调用;
3、 onTimer:定时调用,注册定时器Timer并触发之后的回调操作;
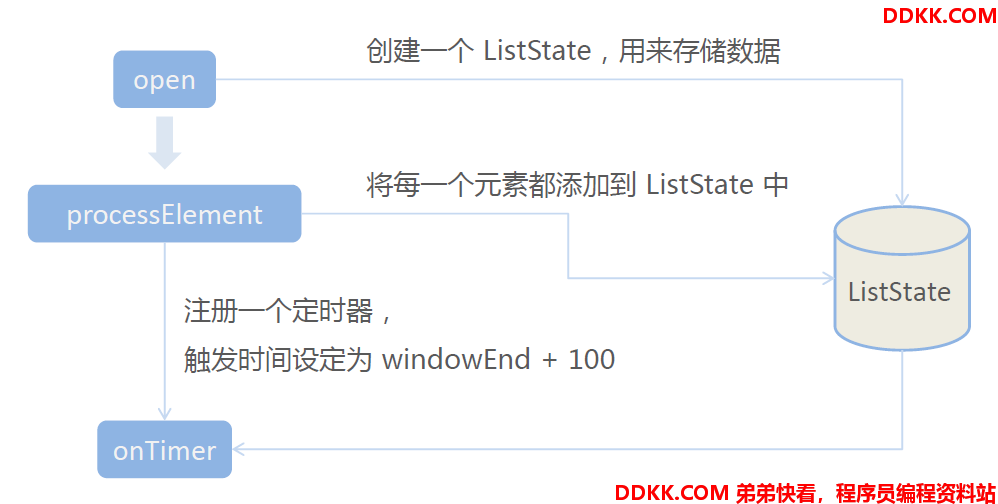
二、pom文件配置
依赖配置:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<!-- Table API 和 Flink SQL -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.10.1</version>
</dependency>
三、代码
3.1 POJO类
UserBehavior
package com.zqs.flink.project.hotitemanalysis.beans;
/**
* @remark 定义一个输入类型的class
*/
public class UserBehavior {
// 定义私有属性
private Long userId;
private Long itemId;
private Integer categoryId;
private String behavior;
private Long timestamp;
public UserBehavior() {
}
public UserBehavior(Long userId, Long itemId, Integer categoryId, String behavior, Long timestamp) {
this.userId = userId;
this.itemId = itemId;
this.categoryId = categoryId;
this.behavior = behavior;
this.timestamp = timestamp;
}
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public Long getItemId() {
return itemId;
}
public void setItemId(Long itemId) {
this.itemId = itemId;
}
public Integer getCategoryId() {
return categoryId;
}
public void setCategoryId(Integer categoryId) {
this.categoryId = categoryId;
}
public String getBehavior() {
return behavior;
}
public void setBehavior(String behavior) {
this.behavior = behavior;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
@Override
public String toString() {
return "UserBehavior{" +
"userId=" + userId +
", itemId=" + itemId +
", categoryId=" + categoryId +
", behavior='" + behavior + '\'' +
", timestamp=" + timestamp +
'}';
}
}
ItemViewCount
package com.zqs.flink.project.hotitemanalysis.beans;
/**
* @remark 定义一个输出类型的class
*/
public class ItemViewCount {
private Long itemId;
private Long windowEnd;
private Long count;
public ItemViewCount() {
}
public ItemViewCount(Long itemId, Long windowEnd, Long count) {
this.itemId = itemId;
this.windowEnd = windowEnd;
this.count = count;
}
public Long getItemId() {
return itemId;
}
public void setItemId(Long itemId) {
this.itemId = itemId;
}
public Long getWindowEnd() {
return windowEnd;
}
public void setWindowEnd(Long windowEnd) {
this.windowEnd = windowEnd;
}
public Long getCount() {
return count;
}
public void setCount(Long count) {
this.count = count;
}
@Override
public String toString() {
return "ItemViewCount{" +
"itemId=" + itemId +
", windowEnd=" + windowEnd +
", count=" + count +
'}';
}
}
3.2 热门商品-纯Java代码
HotItems
package com.zqs.flink.project.hotitemanalysis;
import com.zqs.flink.project.hotitemanalysis.beans.ItemViewCount;
import com.zqs.flink.project.hotitemanalysis.beans.UserBehavior;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Properties;
public class HotItems {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 2. 读取数据,创建DataStream
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkProject\\src\\main\\resources\\UserBehavior.csv");
//Properties properties = new Properties();
//properties.setProperty("bootstrap.servers", "localhost:9092");
//properties.setProperty("group.id", "consumer");
//properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//properties.setProperty("auto.offset.reset", "latest");
//DataStream<String> inputStream = env.addSource(new FlinkKafkaConsumer<String>("hotitems", new SimpleStringSchema(), properties));
// 3. 转换为POJO,分配时间戳和watermark
DataStream<UserBehavior> dataStream = inputStream
.map(line -> {
String[] fields = line.split(",");
return new UserBehavior(new Long(fields[0]), new Long(fields[1]), new Integer(fields[2]), fields[3], new Long(fields[4]));
})
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<UserBehavior>() {
@Override
public long extractAscendingTimestamp(UserBehavior element) {
return element.getTimestamp() * 1000L;
}
});
// 4. 分组开窗聚合,得到每个窗口内各个商品的count值
DataStream<ItemViewCount> windowAggStream = dataStream
.filter(data -> "pv".equals(data.getBehavior())) // 过滤pv行为
.keyBy("itemId") // 按商品ID分组
.timeWindow(Time.hours(1), Time.minutes(5)) // 开滑窗
.aggregate(new ItemCountAgg(), new WindowItemCountResult());
// 5. 收集同一窗口的所有商品count数据,排序输出top n
DataStream<String> resultStream = windowAggStream
.keyBy("windowEnd") // 按照窗口分组
.process(new TopNHotItems(5)); // 用自定义处理函数排序取前5
resultStream.print();
env.execute("hot items analysis");
}
// 实现自定义增量聚合函数
public static class ItemCountAgg implements AggregateFunction<UserBehavior, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(UserBehavior value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return a + b;
}
}
// 自定义全窗口函数
public static class WindowItemCountResult implements WindowFunction<Long, ItemViewCount, Tuple, TimeWindow> {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Long> input, Collector<ItemViewCount> out) throws Exception {
Long itemId = tuple.getField(0);
Long windowEnd = window.getEnd();
Long count = input.iterator().next();
out.collect(new ItemViewCount(itemId, windowEnd, count));
}
}
// 实现自定义KeyedProcessFunction
public static class TopNHotItems extends KeyedProcessFunction<Tuple, ItemViewCount, String>{
// 定义属性,top n的大小
private Integer topSize;
public TopNHotItems(Integer topSize) {
this.topSize = topSize;
}
// 定义列表状态,保存当前窗口内所有输出的ItemViewCount
ListState<ItemViewCount> itemViewCountListState;
@Override
public void open(Configuration parameters) throws Exception {
itemViewCountListState = getRuntimeContext().getListState(new ListStateDescriptor<ItemViewCount>("item-view-count-list", ItemViewCount.class));
}
@Override
public void processElement(ItemViewCount value, Context ctx, Collector<String> out) throws Exception {
// 每来一条数据,存入List中,并注册定时器
itemViewCountListState.add(value);
ctx.timerService().registerEventTimeTimer( value.getWindowEnd() + 1 );
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 定时器触发,当前已收集到所有数据,排序输出
ArrayList<ItemViewCount> itemViewCounts = Lists.newArrayList(itemViewCountListState.get().iterator());
itemViewCounts.sort(new Comparator<ItemViewCount>() {
@Override
public int compare(ItemViewCount o1, ItemViewCount o2) {
return o2.getCount().intValue() - o1.getCount().intValue();
}
});
// 将排名信息格式化成String,方便打印输出
StringBuilder resultBuilder = new StringBuilder();
resultBuilder.append("===================================\n");
resultBuilder.append("窗口结束时间:").append( new Timestamp(timestamp - 1)).append("\n");
// 遍历列表,取top n输出
for( int i = 0; i < Math.min(topSize, itemViewCounts.size()); i++ ){
ItemViewCount currentItemViewCount = itemViewCounts.get(i);
resultBuilder.append("NO ").append(i+1).append(":")
.append(" 商品ID = ").append(currentItemViewCount.getItemId())
.append(" 热门度 = ").append(currentItemViewCount.getCount())
.append("\n");
}
resultBuilder.append("===============================\n\n");
// 控制输出频率
Thread.sleep(1000L);
out.collect(resultBuilder.toString());
}
}
}
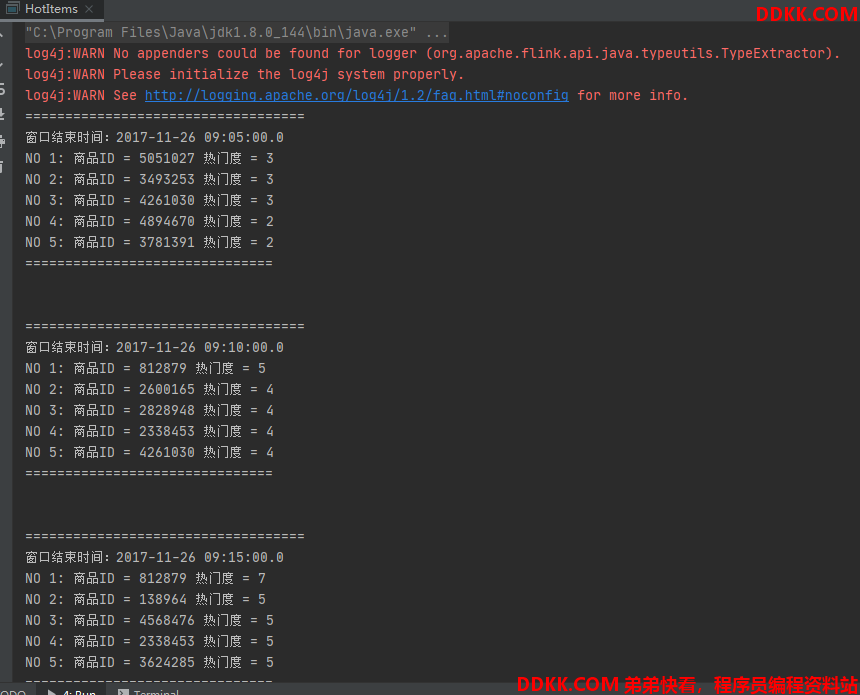
运行记录:
2.3 热门商品-Table API和Flink SQL实现
HotItemsWithSql
package com.zqs.flink.project.hotitemanalysis;
import com.zqs.flink.project.hotitemanalysis.beans.UserBehavior;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class HotItemsWithSql {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 2. 读取数据,创建DataStream
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkProject\\src\\main\\resources\\UserBehavior.csv");
// 3. 转换为POJO, 分配时间戳和watermark
DataStream<UserBehavior> dataStream = inputStream
.map(line -> {
String[] fields = line.split(",");
return new UserBehavior(new Long(fields[0]), new Long(fields[1]), new Integer(fields[2]), fields[3], new Long(fields[4]));
})
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<UserBehavior>() {
@Override
public long extractAscendingTimestamp(UserBehavior element) {
return element.getTimestamp() * 1000L;
}
});
// 4. 创建表执行环境,用blink版本
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 5. 将流转换为表
Table dataTable = tableEnv.fromDataStream(dataStream, "itemId, behavior, timestamp.rowtime as ts");
// 6. 分组开窗
// table api
Table windowAggTable = dataTable
.filter("behavior = 'pv'")
.window(Slide.over("1.hours").every("5.minutes").on("ts").as("w"))
.groupBy("itemId, w")
.select("itemId, w.end as windowEnd, itemId.count as cnt");
// 7. 利用开窗函数,对count值进行排序并获取Row number, 得到Top N
// SQL
DataStream<Row> aggStream = tableEnv.toAppendStream(windowAggTable, Row.class);
tableEnv.createTemporaryView("agg", aggStream, "itemId, windowEnd, cnt");
Table resultTable = tableEnv.sqlQuery("select * from " +
" ( select *, ROW_NUMBER() over (partition by windowEnd order by cnt desc) as row_num " +
" from agg) " +
" where row_num <= 5 ");
// 纯SQL实现
tableEnv.createTemporaryView("data_table", dataStream, "itemId, behavior, timestamp.rowtime as ts");
Table resultSqlTable = tableEnv.sqlQuery("select * from " +
" ( select *, ROW_NUMBER() over (partition by windowEnd order by cnt desc) as row_num " +
" from ( " +
" select itemId, count(itemId) as cnt, HOP_END(ts, interval '5' minute, interval '1' hour) as windowEnd " +
" from data_table " +
" where behavior = 'pv' " +
" group by itemId, HOP(ts, interval '5' minute, interval '1' hour)" +
" )" +
" ) " +
" where row_num <= 5 ");
tableEnv.toRetractStream(resultSqlTable, Row.class).print();
env.execute("hot items with sql job");
}
}
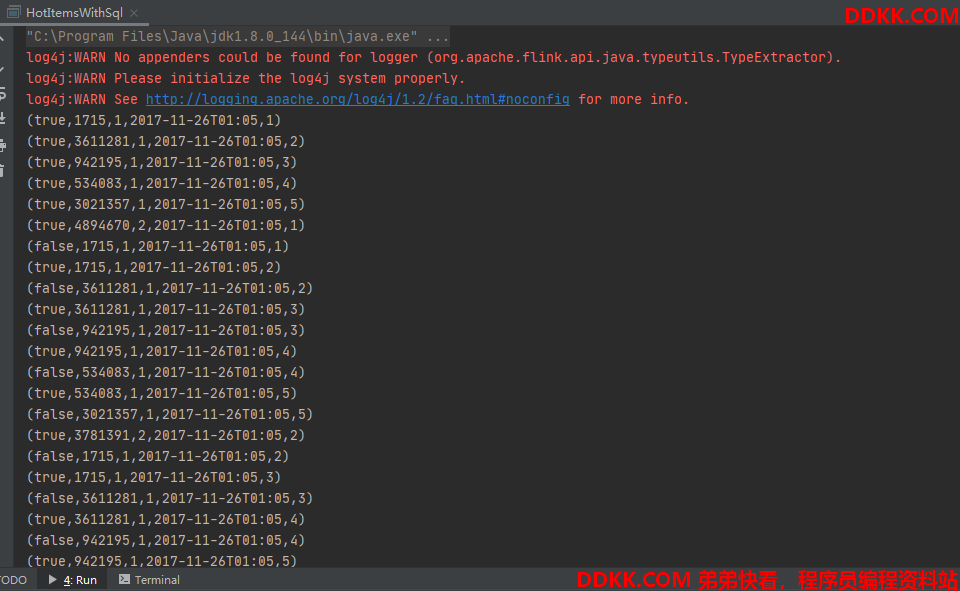
测试记录:
2.4 将文件写入kafka
真实环境一般是flink直连kafka,然后将处理的数据输出
KafkaProducerUtil
package com.zqs.flink.project.hotitemanalysis;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Properties;
/**
* @remark 读取文件数据写入到kafka
*/
public class KafkaProducerUtil {
public static void main(String[] args) throws Exception {
writeToKafka("hotitems");
}
// 包装一个写入kafka的方法
public static void writeToKafka(String topic) throws Exception{
// kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.31.1.124:9092,10.31.1.125:9092,10.31.1.126:9092");
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 定义一个Kafka Producer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 用缓冲方式读取文本
BufferedReader bufferedReader = new BufferedReader(new FileReader("C:\\Users\\Administrator\\IdeaProjects\\FlinkProject\\src\\main\\resources\\UserBehavior.csv"));
String line;
while ((line = bufferedReader.readLine()) != null ){
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, line);
//用producer发送数据
kafkaProducer.send(producerRecord);
}
kafkaProducer.close();
}
}
测试记录:
