一、聚合操作算子简介
DataStream里没有reduce和sum这类聚合操作的方法,因为Flink设计中,所有数据必须先分组才能做聚合操作。
先keyBy得到KeyedStream,然后调用其reduce、sum等聚合操作方法。(先分组后聚合)
常见的聚合操作算子主要有:
1、 keyBy;
2、 滚动聚合算子RollingAggregation;
3、 reduce;
1.1 KeyBy
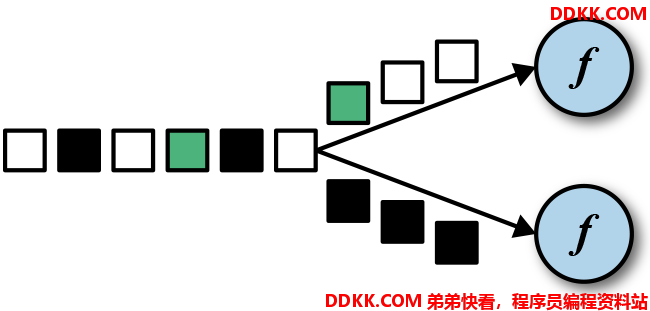
DataStream -> KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。
1、 KeyBy会重新分区;
2、 不同的key有可能分到一起,因为是通过hash原理实现的;
1.2 Rolling Aggregation
这些算子可以针对KeyedStream的每一个支流做聚合。
sum()
min()
max()
minBy()
maxBy()
1.3 reduce
Reduce适用于更加一般化的聚合操作场景。java中需要实现ReduceFunction函数式接口。
在前面Rolling Aggregation的前提下,对需求进行修改。获取同组历史温度最高的传感器信息,同时要求实时更新其时间戳信息。
二、代码实现
数据准备:
sensor.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718209,32.8
sensor_1,1547718212,37.1
2.1 maxby
代码:
package org.example;
/**
* @remark Flink 基础Transform RollingAggregation
*/
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import sun.awt.SunHints;
import javax.xml.crypto.Data;
public class TransformTest2_RollingAggregation {
public static void main(String[] args) throws Exception {
// 创建 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 执行环境并行度设置1
env.setParallelism(1);
DataStream<String> dataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// DataStream<SensorReading> sensorStream = dataStream.map(new MapFunction<String, SensorReading>() {
// @Override
// public SensorReading map(String value) throws Exception {
// String[] fields = value.split(",");
// return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
// }
// });
DataStream<SensorReading> sensorStream = dataStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 先分组再聚合
// 分组
KeyedStream<SensorReading, Tuple> keyedStream = sensorStream.keyBy("id");
//KeyedStream<SensorReading, String> keyedStream = sensorStream.keyBy(SensorReading::getId);
// 滚动聚合,max和maxBy区别在于,maxBy除了用于max比较的字段以外,其他字段也会更新成最新的,而max只有比较的字段更新,其他字段不变
DataStream<SensorReading> resultStream = keyedStream.maxBy("temperature");
resultStream.print("result");
env.execute();
}
}
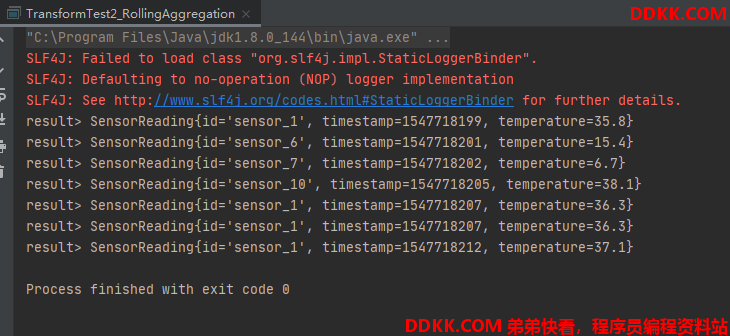
测试记录:
因为Flink是流式处理,来一条处理一条,而且我设的并行度是1,所以根据文件的顺序,读取到每一条,都会和上一条对比温度,然后输出对应的id、以及温度大的那个的timestamp及temperature。
如果我要输出最新的时间戳,该如何处理呢?
这个留到下一节reduce来处理。
2.2 reduce
代码:
package org.flink.transform;
/**
* @remark Flink 基础Transform Reduce
*/
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformTest3_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从文件读取数据
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 分组
KeyedStream<SensorReading, Tuple> keyedStream = dataStream.keyBy("id");
// reduce聚合,取最大的温度值,以及当前最新的时间戳
SingleOutputStreamOperator<SensorReading> resultStream = keyedStream.reduce(new ReduceFunction<SensorReading>() {
@Override
public SensorReading reduce(SensorReading value1, SensorReading value2) throws Exception {
return new SensorReading(value1.getId(), value2.getTimestamp(), Math.max(value1.getTemperature(), value2.getTemperature()));
}
});
keyedStream.reduce( (curState, newData) -> {
return new SensorReading(curState.getId(), newData.getTimestamp(), Math.max(curState.getTemperature(), newData.getTemperature()));
});
resultStream.print();
env.execute();
}
}
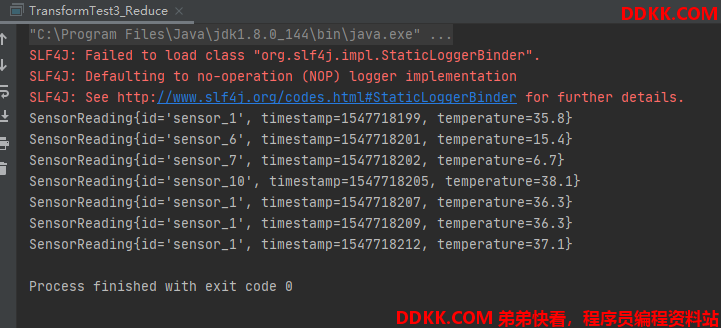
测试记录:
如下可知,输出对应id,当前timestamp,以及当前最大的temperature