一、 流处理中的特殊概念
Table API 和 SQL,本质上还是基于关系型表的操作方式;而关系型表、关系代数,以及 SQL 本身,一般是有界的,更适合批处理的场景。这就导致在进行流处理的过程中,理解会 稍微复杂一些,需要引入一些特殊概念。
1.1 流处理和关系代数(表,及 SQL)的区别
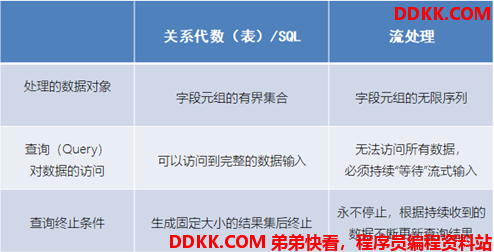
可以看到,其实关系代数(主要就是指关系型数据库中的表)和 SQL,主要就是针对批 处理的,这和流处理有天生的隔阂。
1.2 动态表(Dynamic Tables)
因为流处理面对的数据,是连续不断的,这和我们熟悉的关系型数据库中保存的“表” 完全不同。所以,如果我们把流数据转换成 Table,然后执行类似于 table 的 select 操作,结 果就不是一成不变的,而是随着新数据的到来,会不停更新。
我们可以随着新数据的到来,不停地在之前的基础上更新结果。这样得到的表,在 Flink Table API 概念里,就叫做“动态表”(Dynamic Tables)。
动态表是 Flink 对流数据的 Table API 和 SQL 支持的核心概念。与表示批处理数据的静态 表不同,动态表是随时间变化的。动态表可以像静态的批处理表一样进行查询,查询一个动 态表会产生持续查询(Continuous Query)。连续查询永远不会终止,并会生成另一个动态表。
查询(Query)会不断更新其动态结果表,以反映其动态输入表上的更改。
1.3 流式持续查询的过程
下图显示了流、动态表和连续查询的关系:

流式持续查询的过程为:
1、 流被转换为动态表;
2、 对动态表计算连续查询,生成新的动态表;
3、 生成的动态表被转换回流;
1.3.1 将流转换成表(Table)
为了处理带有关系查询的流,必须先将其转换为表。 从概念上讲,流的每个数据记录,都被解释为对结果表的插入(Insert)修改。因为流式持续不断的,而且之前的输出结果无法改变。本质上,我们其实是从一个、只有插入操作的 changelog(更新日志)流,来构建一个表。
为了更好地说明动态表和持续查询的概念,我们来举一个具体的例子。 比如,我们现在的输入数据,就是用户在网站上的访问行为,数据类型(Schema)如下:
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问某个 URL 的时间戳
url: VARCHAR // 用户访问的 URL
下图显示了如何将访问 URL 事件流,或者叫点击事件流(左侧)转换为表(右侧)。
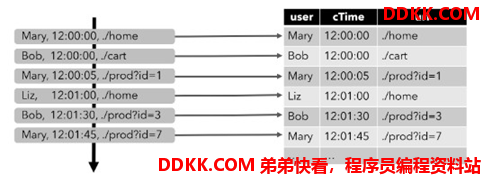
随着插入更多的访问事件流记录,生成的表将不断增长。
1.3.2 持续查询(Continuous Query)
持续查询,会在动态表上做计算处理,并作为结果生成新的动态表。与批处理查询不同, 连续查询从不终止,并根据输入表上的更新更新其结果表。
在任何时间点,连续查询的结果在语义上,等同于在输入表的快照上,以批处理模式执 行的同一查询的结果。
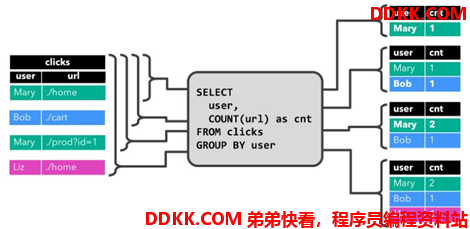
在下面的示例中,我们展示了对点击事件流中的一个持续查询。
这个 Query 很简单,是一个分组聚合做 count 统计的查询。它将用户字段上的 clicks 表 分组,并统计访问的 url 数。图中显示了随着时间的推移,当 clicks 表被其他行更新时如何 计算查询。
1.3.3 将动态表转换成流
与常规的数据库表一样,动态表可以通过插入(Insert)、更新(Update)和删除(Delete) 更改,进行持续的修改。将动态表转换为流或将其写入外部系统时,需要对这些更改进行编 码。Flink 的 Table API 和 SQL 支持三种方式对动态表的更改进行编码:
1、 仅追加(Append-only)流;
仅通过插入(Insert)更改,来修改的动态表,可以直接转换为“仅追加”流。这个流 中发出的数据,就是动态表中新增的每一行。
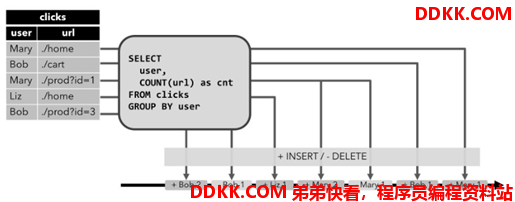
2、 撤回(Retract)流;
Retract 流是包含两类消息的流,添加(Add)消息和撤回(Retract)消息。 动态表通过将 INSERT 编码为 add 消息、DELETE 编码为 retract 消息、UPDATE 编码为被
更改行(前一行)的 retract 消息和更新后行(新行)的 add 消息,转换为 retract 流。 下图显示了将动态表转换为 Retract 流的过程。
 3、 Upsert(更新插入)流;
3、 Upsert(更新插入)流;
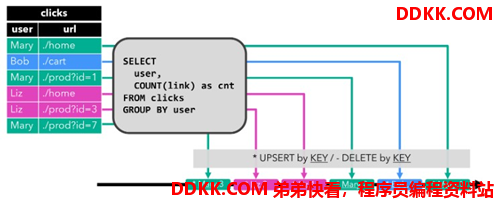
Upsert 流包含两种类型的消息:Upsert 消息和 delete 消息。转换为 upsert 流的动态表, 需要有唯一的键(key)。
通过将 INSERT 和 UPDATE 更改编码为 upsert 消息,将 DELETE 更改编码为 DELETE 消息, 就可以将具有唯一键(Unique Key)的动态表转换为流。
下图显示了将动态表转换为 upsert 流的过程。
这些概念我们之前都已提到过。需要注意的是,在代码里将动态表转换为 DataStream 时,仅支持 Append 和 Retract 流。而向外部系统输出动态表的 TableSink 接口,则可以有不 同的实现,比如之前我们讲到的 ES,就可以有 Upsert 模式。
1.4 时间特性
基于时间的操作(比如 Table API 和 SQL 中窗口操作),需要定义相关的时间语义和时间 数据来源的信息。所以,Table 可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳。
时间属性,可以是每个表 schema 的一部分。一旦定义了时间属性,它就可以作为一个 字段引用,并且可以在基于时间的操作中使用。
时间属性的行为类似于常规时间戳,可以访问,并且进行计算。
1.4.1 处理时间(Processing Time)
处理时间语义下,允许表处理程序根据机器的本地时间生成结果。它是时间的最简单概 念。它既不需要提取时间戳,也不需要生成 watermark。
定义处理时间属性有三种方法:在 DataStream 转化时直接指定;在定义 Table Schema时指定;在创建表的 DDL 中指定。
1.4.1.1 DataStream 转化成 Table 时指定
由DataStream 转换成表时,可以在后面指定字段名来定义 Schema。在定义 Schema 期间,可以使用.proctime,定义处理时间字段。
注意,这个 proctime 属性只能通过附加逻辑字段,来扩展物理 schema。因此,只能在 schema 定义的末尾定义它。
代码如下:
// 定义好 DataStream
DataStream<String> inputStream = env.readTextFile("\\sensor.txt") DataStream<SensorReading> dataStream = inputStream
.map( line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new
Double(fields[2]));
} );
// 将 DataStream 转换为 Table,并指定时间字段
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, temperature, timestamp, pt.proctime");
1.4.1.2 定义Table Schema时指定
这种方法其实也很简单,只要在定义 Schema 的时候,加上一个新的字段,并指定成proctime 就可以了。
代码如下:
tableEnv.connect(
new FileSystem().path("..\\sensor.txt"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
.field("pt", DataTypes.TIMESTAMP(3))
.proctime() // 指定 pt 字段为处理时间
) // 定义表结构
.createTemporaryTable("inputTable"); // 创建临时表
1.4.1.3 创建表的 DDL 中指定
在创建表的 DDL 中,增加一个字段并指定成 proctime,也可以指定当前的时间字段。
代码如下:
String sinkDDL = "create table dataTable (" +
" id varchar(20) not null, " +
" ts bigint, " +
" temperature double, " +
" pt AS PROCTIME() " +
") with (" +
" 'connector.type' = 'filesystem', " + " 'connector.path' = '/sensor.txt', " + " 'format.type' = 'csv')";
tableEnv.sqlUpdate(sinkDDL);
注意:运行这段 DDL,必须使用 Blink Planner。
1.4.2 事件时间(Event Time)
事件时间语义,允许表处理程序根据每个记录中包含的时间生成结果。这样即使在有乱 序事件或者延迟事件时,也可以获得正确的结果。
为了处理无序事件,并区分流中的准时和迟到事件;Flink 需要从事件数据中,提取时 间戳,并用来推进事件时间的进展(watermark)。
1.4.2.1 DataStream 转化成 Table 时指定
在DataStream 转换成 Table,schema 的定义期间,使用.rowtime 可以定义事件时间属性。 注意,必须在转换的数据流中分配时间戳和 watermark。
在将数据流转换为表时,有两种定义时间属性的方法。根据指定的.rowtime 字段名是否 存在于数据流的架构中,timestamp 字段可以:
⚫作为新字段追加到 schema
⚫替换现有字段
在这两种情况下,定义的事件时间戳字段,都将保存 DataStream 中事件时间戳的值。
代码如下:
DataStream<String> inputStream = env.readTextFile("\\sensor.txt") DataStream<SensorReading> dataStream = inputStream
.map( line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new
Double(fields[2]));
} )
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(1)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, timestamp.rowtime as ts, temperature");
1.4.2.2 定义 Table Schema 时指定
这种方法只要在定义 Schema 的时候,将事件时间字段,并指定成 rowtime 就可以了。
代码如下:
tableEnv.connect(
new FileSystem().path("sensor.txt"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.rowtime(
new Rowtime()
.timestampsFromField("timestamp") // 从字段中提取时间戳
.watermarksPeriodicBounded(1000) // watermark 延迟 1 秒
)
.field("temperature", DataTypes.DOUBLE())
) // 定义表结构
.createTemporaryTable("inputTable"); // 创建临时表
1.4.2.3 创建表的 DDL 中指定
事件时间属性,是使用 CREATE TABLE DDL 中的 WARDMARK 语句定义的。watermark 语 句,定义现有事件时间字段上的 watermark 生成表达式,该表达式将事件时间字段标记为事 件时间属性。
代码如下:
String sinkDDL = "create table dataTable (" +
" id varchar(20) not null, " +
" ts bigint, " +
" temperature double, " +
" rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts) ), " +
" watermark for rt as rt - interval '1' second" +
") with (" +
" 'connector.type' = 'filesystem', " + " 'connector.path' = '/sensor.txt', " + " 'format.type' = 'csv')";
tableEnv.sqlUpdate(sinkDDL);
这里 FROM_UNIXTIME 是系统内置的时间函数,用来将一个整数( 秒数) 转换成 “YYYY-MM-DD hh:mm:ss”格式(默认,也可以作为第二个 String 参数传入)的日期时间 字符串(date time string);然后再用 TO_TIMESTAMP 将其转换成 Timestamp。
二、案例
代码:
package org.flink.tableapi;
import org.flink.beans.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class TableTest5_TimeAndWindow {
public static void main(String[] args) throws Exception {
// 1. 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2. 读入文件数据,得到DataStream
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 3. 转换成POJO
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
// 4. 将流转换成表,定义时间特性
// Table dataTable = tableEnv.fromDataStream(dataStream, "id, timestamp as ts, temperature as temp, pt.proctime");
Table dataTable = tableEnv.fromDataStream(dataStream, "id, timestamp as ts, temperature as temp, rt.rowtime");
tableEnv.registerTable("sensor", dataTable);
// 5. 窗口操作
// 5.1 Group Window
// table API
Table resultTable = dataTable.window(Tumble.over("10.seconds").on("rt").as("tw"))
.groupBy("id, tw")
.select("id, id.count, temp.avg, tw.end");
// SQL
Table resultSqlTable = tableEnv.sqlQuery("select id, count(id) as cnt, avg(temp) as avgTemp, tumble_end(rt, interval '10' second) " +
"from sensor group by id, tumble(rt, interval '10' second)");
// 5.2 Over Window
// table API
Table overResult = dataTable.window(Over.partitionBy("id").orderBy("rt").preceding("2.rows").as("ow"))
.select("id, rt, id.count over ow, temp.avg over ow");
// SQL
Table overSqlResult = tableEnv.sqlQuery("select id, rt, count(id) over ow, avg(temp) over ow " +
" from sensor " +
" window ow as (partition by id order by rt rows between 2 preceding and current row)");
// dataTable.printSchema();
// tableEnv.toAppendStream(resultTable, Row.class).print("result");
// tableEnv.toRetractStream(resultSqlTable, Row.class).print("sql");
tableEnv.toAppendStream(overResult, Row.class).print("result");
tableEnv.toRetractStream(overSqlResult, Row.class).print("sql");
env.execute();
}
}
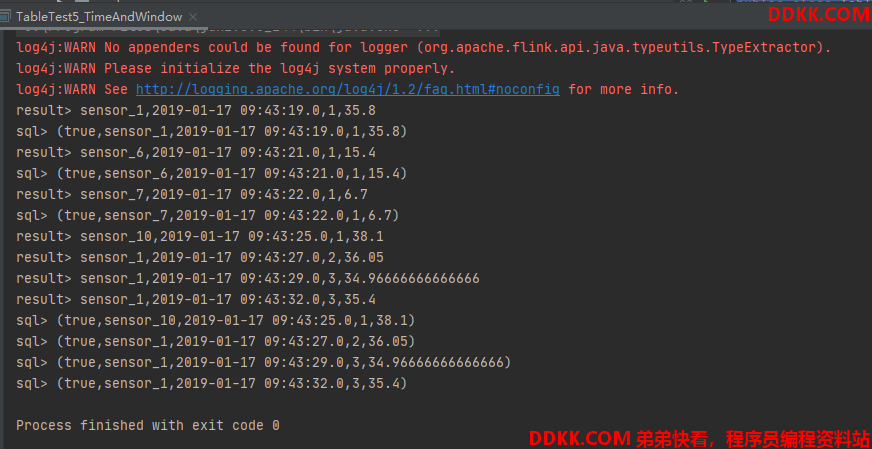
测试记录: