一、数据重分区
重分区操作,在DataStream类中可以看到很多Partitioner字眼的类。
其中partitionCustom(…)方法用于自定义重分区。
测试代码:
package org.flink.transform;
/**
* @remark Flink 基础Transform 重分区
*/
import org.flink.beans.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformTest6_Partition {
public static void main(String[] args) throws Exception{
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度 = 4
env.setParallelism(4);
// 从文件读取数据
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// SingleOutputStreamOperator多并行度默认就rebalance,轮询方式分配
dataStream.print("input");
// 1. shuffle (并非批处理中的获取一批后才打乱,这里每次获取到直接打乱且分区)
DataStream<String> shuffleStream = inputStream.shuffle();
shuffleStream.print("shuffle");
// 2. keyBy (Hash,然后取模)
dataStream.keyBy(SensorReading::getId).print("keyBy");
// 3. global (直接发送给第一个分区,少数特殊情况才用)
dataStream.global().print("global");
env.execute();
}
}
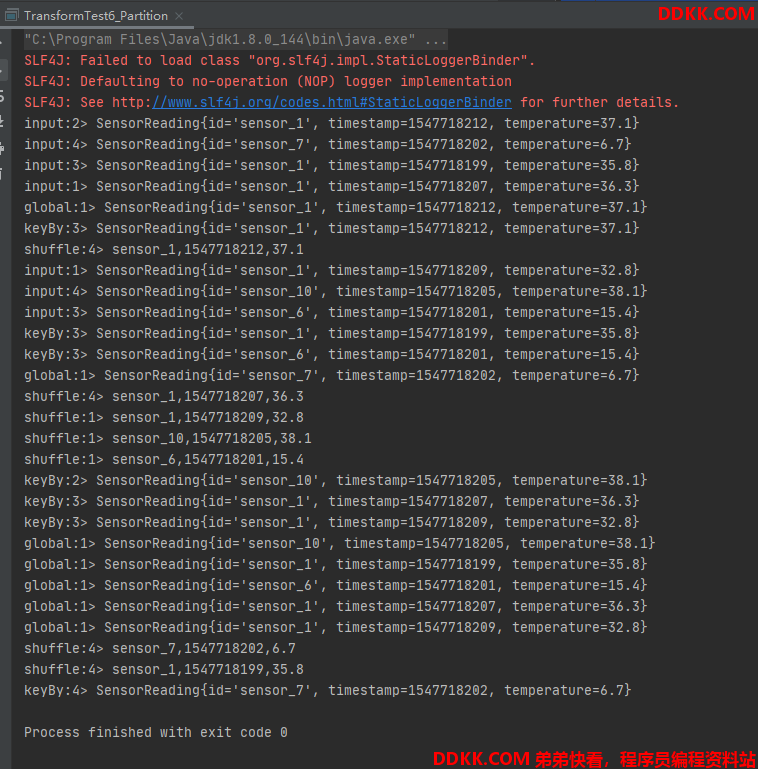
测试记录:
如下截图可以看到:
1、 input标记的是rebalance,均匀分布;
2、 global全部都分配到进程1了;
3、 keyBy非均匀分布sensor_1全部都分配到了进程1;
4、 shuffle就有点随机了;